【项目018】基于人像分割的背景替换(教学版) 隐藏答案 | 返回首页
作者:欧新宇(Xinyu OU)
当前版本:Release v2.0
开发平台:Paddle 3.0.0-beta1, PaddleSeg-release-2.10
运行环境:Intel Core i7-13700KF CPU 3.4GHz, nVidia GeForce RTX 4080
本教案所涉及的数据集仅用于教学和交流使用,请勿用作商用。
最后更新:2025年2月3日
注意,本项目需要使用GPU环境运行。此外,因上传问题,包含完整图片和文本的版本需要访问课程网站:【项目018】基于人像分割的背景替换。
随着 COVID-19 大流行在全球肆虐,视频会议的需求激增。为此,实时人像分割成为代替会议参与者背景的流行功能。人像分割任务旨在识别图像中的人体轮廓,与背景进行分离,返回分割后的二值图、灰度图、前景人像图,适应多个人体、复杂背景、各类人体姿态,可应用于人像扣图、人体特效和影视后期处理等场景。背景移除是图像分割的典型应用之一,传统的背景移除通常借助于阈值分隔、边缘检测等计算机视觉技术进行实习,而基于深度学习的图像分割(Segmentation)技术常常和目标检测(Detection)共同完成。
【任务提交说明】
- 所有内容均在AIStudio上进行提交,提交包含源代码和运行结果的
.ipynb文件,以及work/outputs文件夹。 - 在AIStudio平台上或本地完成PaddleSeg的安装,注意本地安装时需要先安装PaddlePaddle,并且要能够支持GPU加速
- 在PaddleSeg中完成【任务四】人像分割模型的快速体验,使用给定的视频和图片完成背景移除和替换,或自行准备样本完成视频和图片的背景移除和替换。所有结果保存在
work/outputs目录下。若原始图片名字为image01.jpg,则将移除背景的图片命名为image01_remove.jpg,替换背景的图片命名为image01_replace.jpg - 至少使用
portrait_pp_humansegv1_lite_398x224,human_pp_humansegv1_mobile_192x192,human_pp_humansegv2_mobile_192x192三个模型完成【任务五】中模型训练,并完成5.3 模型评估的性能对比表。并完成【任务六】,输出work/data/predict文件夹中的6个样本的预测结果,结果保存到work/outputs/predict文件夹中。此外,建议给出多模型预测结果的对比分析。
【任务一】PaddleSeg环境的安装与调试
任务描述: 在安装有PaddlePaddle的计算机上完成PaddleSeg的安装和测试。
任务要求:
- 学会在安装好PaddlePaddle的Windows系统中安装PaddleSeg工具包;
- 能够解决PaddleSeg安装过程中遇到的各种问题;
- 能够通过测试判断PaddleSeg是否被正确安装。
1.1 PaddleSeg的下载
- 从官网下载PaddleSeg(当前最新版v2.10)https://github.com/PaddlePaddle/PaddleSeg
- 在Windows中,使用文件管理方式进行解压,将
PaddleSeg-release-2.10.zip工具包解压到项目文件夹MyProjects,建议直接使用带版本的文件夹命名方式PaddleSeg-release-2.10(便于版本管理)。 - 在百度AIStudio中,首先将
PaddleSeg-release-2.10.zip工具包上传到服务器根目录,然后再将该.zip文件解压到工作路径/home/aistudio/work。此外,还可以使用命令行执行。以下代码可以在终端执行,也可以在.ipynb中执行(需要在前面增加一个感叹号)。
!unzip -o /home/aistudio/PaddleSeg-release-2.10.zip -d /home/aistudio/work/
1.2 PaddleSeg的安装
PaddleSeg的具体安装配置方法,请参考 【项目002】Python机器学习环境的安装和配置。 通常,PaddleSeg环境的安装只需要执行一次,确认服务器或本地环境已经具备相关依赖文件后,可跳过该步。
- 在终端中,将目录切换到:
D:\WorkSpace\MyProjects\PaddleSeg-release-2.10或/home/aistudio/work/PaddleSeg-release-2.10,然后执行以下安装命令。
>> pip install paddleseg
>> pip install -r requirements.txt
>> pip install -v -e .
- 所有依赖都安装完成,并且不报错,则表明安装成功。
注:安装过程中,若出现某个库安装失败,可手动进行安装,直至 requirements.txt 中的库都安装完毕。安装方法如下:
pip install xxxx -i https://pypi.tuna.tsinghua.edu.cn/simple
1.3 PaddleSeg的测试
该测试实现模型的自动下载和测试图片的推理,推理结果保存在 output 文件夹中,正常运行结束后可以到 output/setup_test 目录下去查看输出结果。
>> python tools/predict.py --config configs/quick_start/bisenet_optic_disc_512x512_1k.yml --model_path https://bj.bcebos.com/paddleseg/dygraph/optic_disc/bisenet_optic_disc_512x512_1k/model.pdparams --image_path docs/images/optic_test_image.jpg --save_dir output/setup_test
测试通过将出现如下提示:
...
- type: Normalize
type: OpticDiscSeg
------------------------------------------------
W0410 13:55:31.365703 20260 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 6.1, Driver API Version: 11.1, Runtime API Version: 10.2
W0410 13:55:31.366700 20260 device_context.cc:465] device: 0, cuDNN Version: 7.6.
2022-04-10 13:55:35 [INFO] Number of predict images = 1
2022-04-10 13:55:35 [INFO] Loading pretrained model from https://bj.bcebos.com/paddleseg/dygraph/optic_disc/bisenet_optic_disc_512x512_1k/model.pdparams
2022-04-10 13:55:35 [INFO] There are 356/356 variables loaded into BiSeNetV2.
[2025/02/03 13:50:42] INFO: Start to predict...
1/1 [==============================] - 0s 260ms/step
[2025/02/03 13:50:42] INFO: Predicted images are saved in output/result/added_prediction and output/result/pseudo_color_prediction .
此时,可切换文件夹至 output/result/added_prediction/optic_test_image.jpg 和 output/result/pseudo_color_prediction/optic_test_image.png 查看分割结果。
【任务二】Windows工程环境的设置
任务描述: 在本地计算机中配置和部署好用于目标检测的相关文件夹和文件。
任务要求:
- 理解项目化部署的重要性;
- 能够根据需要完成必要文件夹的创建,并将相关文件保存到指定文件夹。
为了便于项目管理,本课程所有环境都按照统一规范进行设置,详细内容请参考 【项目002】Python机器学习环境的安装和配置。
我们在 PaddleSeg-release-2.10 的根目录中可以看到多个不同功能的文件夹,其中 configs 保存了预制的多个经典模型,包括deeplabv3, unet, pp_liteseg等;tools 文件夹中保存了PaddleSeg工具用于 训练、验证、推理 等功能的可执行文件。此外,在发布文件夹 contrib 中已经保存了许多完整的项目,本项目的示例人像分割任务 PP-HumanSeg 也在其中。在该目录下,内置了若干功能文件夹(部分文件夹需要执行相应命令后才会生成),分别为:
- configs:用于保存所模型配置文件
- src:用于保存可执行的工具源代码脚本
- data:用于保存数据集配置文件
- output:用于保存训练过程中生成的模型文件和预测获得的结果文件(本项目完成后,需要将该文件夹生成的文件拷贝到
work/outputs进行作业提交) - inference_models:用于保存用于部署的模型文件
- pretrained_model:用于保存预训练模型文件
- saved_models:用于保存训练过程中生成的模型文件
更多说明,可以参考该文件夹下的 README.md 文件。
【任务三】数据准备
任务描述: 下载HumanSeg数据集,并按规范解压到指定目录,用于后续的训练、评估和预测。
任务要求:
- 下载HumanSeg数据集,并按规范解压到指定目录,用于后续的训练、评估和预测;
- 能够对图像样本和标注图像进行简单的可视化分析。
3.1 数据获取
本项目可使用两个数据集进行完成,其中HumanSeg数据集是由Supervisely发布,包含5711张高质量人像分割照片;此外,为了方便教学本项目使用PaddleSeg提供的简化版的人像分割数据集mini_supervisely,该数据集包含350副图像,其中训练、验证和测试数据分别为200, 100, 50。
-
HumanSeg数据集下载地址为:https://aistudio.baidu.com/aistudio/datasetdetail/61378
-
本例使用
mini_supervisely数据集, 先将工作目录切换到数据集目录,然后直接调用工具包的数据集下载脚本下载数据集到当前目录。- Windows:
D:\Workspace\MyProjects\PaddleSeg-release-2.10\contrib\PP-HumanSeg
python src\download_data.py
- AIStudio:
/home/aistudio/work/PaddleSeg-release-2.10/contrib/PP-HumanSeg
python src/download_data.py
- Windows:
下载完成后将提示 Data download finished!。下载好的示例数据集 mini_supervisely 将自动保存在 PaddleSeg-release-2.10\contrib\PP-HumanSeg\data\mini_supervisely 中。
此外,也可以使用Jupyter环境进行下载。
import os
# workspace = 'D:\\Workspace\\MyProjects\\PaddleSeg-release-2.10\\contrib\\PP-HumanSeg' # Windows
workspace = '/home/aistudio/work/PaddleSeg-release-2.10/contrib/PP-HumanSeg' # AIStudio
os.chdir(workspace)
!python src/download_data.py
Data download finished!
3.2 数据列表生成
在图像分割任务中,最常用的图像标注文件包括两种,一种是多通道PNG索引,另一种是单通道PNG索引。对于多通道PNG索引来说,通常会根据整个数据集类别数量来创建图片通道,每个通道表示一个类别,通道的编号与类别的ID一致,对于每一个通道来说,如果该图像存在通道ID(类别ID)的对象,那么对应的像素位置则赋值为1,其他位置则赋值为0。而对于单通道PNG索引,一般则是将PNG按照原始图片的真实像素所对应的位置填充上像素所属类别的ID。不管使用哪一种索引方式,每个PNG文件都代表一个样本,因此通常还需要一个文本文件来对这些样本建立索引,这个文本索引文件通常称作数据列表文件。数据列表的生成比较工程化,通常需要根据需求为各个数据子集(train,val,test,trainval)手动创建数据列表文件,下面给出一个标注内容的范例:
train.txt
Images/pexels-photo-267447.png Annotations/pexels-photo-267447.png
Images/pexels-photo-432506_0j2qo0nXL4.png Annotations/pexels-photo-432506_0j2qo0nXL4.png
Images/pexels-photo-881590.png Annotations/pexels-photo-881590.png
Images/pexels-photo-711938.png Annotations/pexels-photo-711938.png
Images/pexels-photo-192468.jpg Annotations/pexels-photo-192468.png
Images/pexels-photo-236953.jpg Annotations/pexels-photo-236953.png
PS:注意本数据集范例已经提供了数据列表,若使用自定义数据集则需要手动进行创建。数据列表生成的方法,可以参考 第4.3节 或 【项目003】数据准备(Data Preparation)
3.3 数据图片及标注图片的可视化
import os
import cv2
import matplotlib.pyplot as plt
import paddle.vision as vision
# 设置各种路径
# root_path = 'D:/Workspace/MyProjects/PaddleSeg-release-2.10/contrib/PP-HumanSeg/data/mini_supervisely'
root_path = '/home/aistudio/work/PaddleSeg-release-2.10/contrib/PP-HumanSeg/data/mini_supervisely'
img_name = 'beauty-woman-flowered-hat-cap-53956'
img_path = os.path.join(root_path, 'Images', img_name+'.jpg')
anno_path = os.path.join(root_path, 'Annotations', img_name+'.png')
img = cv2.imread(img_path, 1)
img_RGB = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
anno = cv2.imread(anno_path)
anno_GRAY = cv2.cvtColor(anno, cv2.COLOR_BGR2GRAY) # 因为只有两种颜色,所以转换为二值图像
# 可视化
plt.figure(figsize=(18, 10))
ax0 = plt.subplot(1,2,1)
ax0.set_title('Images')
plt.imshow(img_RGB)
ax1 = plt.subplot(1,2,2)
ax1.set_title('Annotations')
plt.imshow(anno_GRAY)
plt.show()

【任务四】人像分割模型快速体验
任务描述: 背景移除是网络中常见的应用,例如更换照片的背景色、视频聊天及视频会议中的背景替换等。任务三要求能根据不同的任务选择合适的模型,实现基本的背景移除应用。
任务要求:
- 学会使用训练好的模型对摄像头实现实时的背景移除及背景替换;
- 学会使用训练好的模型对视频进行背景移除及背景替换;
- 学会选择合适的模型对静态图片实现背景移除及背景替换。
4.1 模型介绍
本项目使用百度PaddleSeg提供的示例项目 PP-HumanSeg 完成相关任务,该项目提供四个预训练模型,分别用于服务器端、移动端、Web端的通用人像分割和Web端的肖像分割,介绍信息如下:
| 类别 | 模型名 | 模型简介/文件名 | 精度mIoU | Parameters | 计算耗时 | 模型大小 |
|---|---|---|---|---|---|---|
| 人像分割 | human_pp_humansegv1_server_192x192 | 高精度模型,适用于服务端GPU且背景复杂的场景,Backbone: Deeplabv3+/resnet50_vd_ssld_v2 | 96.47 | 26.8M | 24.90ms | 104.6MB |
| 人像分割 | human_PP-HumanSegv1-Mobile_192x192 | 轻量级模型,适用于移动端或服务端CPU的前置摄像头场景,Backbone: HRNet_w18_samll_v1 | 91.64 | 1.54M | 2.83ms | 6.04Mb |
| 人像分割 | human_PP-HumanSegv2-Mobile_192x192 | 轻量级模型,适用于移动端或服务端CPU的前置摄像头场景,Backbone: PP_STDCNet | 93.13 | 1.54M | 2.67ms | 29.4Mb |
| 人像分割 | human_pp_HumanSegv1_Lite_192x192 | 超轻量级模型,适用于Web端或移动端实时分割场景,例如手机自拍、Web视频会议 | 86.02 | 137K | 12.30ms | 0.54MB |
| 人像分割 | human_pp_HumanSegv2_Lite_192x192 | 超轻量级模型,适用于Web端或移动端实时分割场景,例如手机自拍、Web视频会议,Backbone: mobilenetv3_large_x1_0_ssld | 92.52 | 137K | 15.30ms | 11.9MB |
| 肖像分割 | portrait_PP_HumanSegv1_Lite_398x224 | 超轻量级模型,适用于Web端或移动端实时的 半身人像 场景,例如手机自拍、Web视频会议,模型结构为 |
93.60 | 137K | 29.68ms | 0.54MB |
| 肖像分割 | portrait_PP_HumanSegv2_Lite_256x144 | 超轻量级模型,适用于Web端或移动端实时的 半身人像 场景,例如手机自拍、Web视频会议,模型结构为 |
96.63 | 137K | 15.86ms | 3.67MB |
4.2 Inference模型下载
Infernce是已经训练好的用于人像分割的推理模型,高性能DeepLabv3模型有104M,轻量级的pphumanseg_lite只有543k。下面我们先将这些模型下载到 export_model 文件夹中,以供后续处理。
- Windows
>> python src\download_inference_models.py
- AIStudio
>> python src/download_inference_models.py
import os
# workspace = 'D:\\Workspace\\MyProjects\\PaddleSeg-release-2.10\\contrib\\PP-HumanSeg' # Windows
workspace = '/home/aistudio/work/PaddleSeg-release-2.10/contrib/PP-HumanSeg' # AIStudio
os.chdir(workspace)
!python src/download_inference_models.py
Data download finished!
4.3 使用Inference模型进行背景移除
使用Inference模型,我们可实现对图片和视频的背景移除以及背景替换等功能,也可以实现对摄像头采集的视频进行实时背景处理。不难发现以上所有的应用,归根到底都是对图像中的人像进行图像分割,然后根据分割结果进行后续处理。其中视频对象相当于多帧图像的融合。
下面我们使用PaddleSeg内置脚本 src/seg_demo.py 实现背景移除和替换等功能的演示,以下给出相关参数的解释:
- --config [path],其中path表示部署配置文件的路径,一般使用deploy.yaml表示;
- --use_optic_flow,表示是否使用光流进行辅助分割,光流是计算机视觉中常用的行为分析方法,可以减少视频预测前后帧闪烁的问题;
- --img_path,指定需要进行图像分割操作的 图像 文件;
- --video_path,指定需要进行图像分割操作的 视频 文件;
- --bg_img_path,指定用于
替换背景的图片; - --bg_video_path,指定用于
替换背景的视频; - --save_dir,输出结果的保存路径,默认为
./output; - --vertical_screen,若输入图片和视频是竖屏拍摄,可设定该选项为True以提高性能;
- --input_shape,指定输入模型的图像的尺度。
若 --img_path 和 --video_path 均没有参数,则调用摄像头进行图像采集。
下面,我们先将工作目录切换到 PP-HumanSeg。
import os
# workspace = 'D:\\Workspace\\MyProjects\\PaddleSeg-release-2.10\\contrib\\PP-HumanSeg' # Windows
workspace = '/home/aistudio/work/PaddleSeg-release-2.10/contrib/PP-HumanSeg' # AIStudio
os.chdir(workspace)
4.3.1 通过摄像头进行实时分割处理
注意:由于AIStudio是云端的虚拟机,无法调用本地摄像头,因此本小节的任务只能在本地运行。若未在本地部署项目,可跳过本小节的内容。
实时系统要求模型的推理速度能够基本满足人对视频的帧数FPS(通常不低于25FPS,最好能达到60FPS)的要求,否则就会产生卡顿,因此对于实时系统需要重点权衡速度与性能之间的平衡。在本例中,我们使用超轻量级模型 pphumanseg_lite_portrait_398x224 实现基于人像的分割的背景替换应用。在融合光流信息之后,分割结果有细微的提升。(本例中的视频因分辨率较低,因此视觉上变化不大)
- 背景移除
>> python src/seg_demo.py --config inference_models portrait_pp_humansegv1_lite_398x224_inference_model_with_softmax/deploy.yaml
- 背景替换
>> python src/seg_demo.py --config inference_models/portrait_pp_humansegv1_lite_398x224_inference_model_with_softmax/deploy.yaml --bg_img_path D:/WorkSpace/DeepLearning/WebsiteV2/Images/Projects/Project018HumanSegmentation/bg3.jpg
- 背景替换(with光流)
>> python src/seg_demo.py --config inference_models/portrait_pp_humansegv1_lite_398x224_inference_model_with_softmax/deploy.yaml --bg_img_path D:/WorkSpace/DeepLearning/WebsiteV2/Images/Projects/Project018HumanSegmentation/bg2.jpg --use_optic_flow
| 原始视频 | 背景移除 | 背景替换 | 背景替换(光流) |
|---|---|---|---|
从上面的实验结果不难发现,背景替换的质量由背景移除的质量决定。这说明,前景和背景融合在背景替换中影响不大,但图像分割的质量却影响较大。此外,光流特征在本例中并没有起到明显作用。(PS:演示视频和图片,请访问课程网站 【项目018】基于人像分割的背景替换。)
4.3.2 对人像视频进行分割
对于实时性要求不高的离线视频推理应用,我们可以考虑使用类似deeplabev3的高性能模型,以获得更好的性能。本项目中,光流特征同样对图像分割只有细微的性能提升。
Note: 使用高性能模型进行分割时,根据系统性能的不同,可能需要几分钟时间,请耐心等待。使用GPU可以有效提高解析速度。
- 背景移除
!python src/seg_demo.py \
--config inference_models/human_pp_humansegv2_mobile_192x192_inference_model_with_softmax/deploy.yaml \
--video_path /home/aistudio/work/data/Mike.mp4 \
--save_dir /home/aistudio/work/results/Mike_remove.avi
/opt/conda/envs/python35-paddle120-env/lib/python3.10/site-packages/paddle/utils/cpp_extension/extension_utils.py:686: UserWarning: No ccache found. Please be aware that recompiling all source files may be required. You can download and install ccache from: https://github.com/ccache/ccache/blob/master/doc/INSTALL.md
warnings.warn(warning_message)
2025-03-06 10:30:19 [INFO] Input: video
2025-03-06 10:30:19 [INFO] Create predictor...
2025-03-06 10:30:19 [INFO] Start predicting...
100%|█████████████████████████████████████████| 472/472 [00:54<00:00, 8.69it/s]
- 背景移除(with 后处理)
# 1. Windows
# !python src/seg_demo.py \
# --config inference_models/human_pp_humansegv2_mobile_192x192_inference_model_with_softmax/deploy.yaml \
# --video_path D:/WorkSpace/DeepLearning/WebsiteV2/Images/Projects/Project018HumanSegmentation/video_test_me.mp4 \
# --save_dir D:/WorkSpace/DeepLearning/WebsiteV2/Images/Projects/Project018HumanSegmentation/video_test_me_remove_with_post_process.avi \
# --use_post_process
# 2. AIStudio/Linux
!python src/seg_demo.py \
--config inference_models/human_pp_humansegv2_mobile_192x192_inference_model_with_softmax/deploy.yaml \
--video_path /home/aistudio/work/data/Mike.mp4 \
--save_dir /home/aistudio/work/results/Mike_remove_with_post_process.avi \
--use_post_process
- 背景替换
# # 1. Windows
# !python src/seg_demo.py \
# --config inference_models/human_pp_humansegv2_mobile_192x192_inference_model_with_softmax/deploy.yaml \
# --video_path D:/WorkSpace/DeepLearning/WebsiteV2/Images/Projects/Project018HumanSegmentation/video_test_me.mp4 \
# --bg_img_path D:/WorkSpace/DeepLearning/WebsiteV2/Images/Projects/Project018HumanSegmentation/bg3.jpg \
# --save_dir D:/WorkSpace/DeepLearning/WebsiteV2/Images/Projects/Project018HumanSegmentation/video_test_me_replace.avi
# 2. AIStudio/Linux
!python src/seg_demo.py \
--config inference_models/human_pp_humansegv2_mobile_192x192_inference_model_with_softmax/deploy.yaml \
--video_path /home/aistudio/work/data/Mike.mp4 \
--bg_img_path /home/aistudio/work/data/bg3.jpg \
--save_dir /home/aistudio/work/results/Mike_replace.avi
- 背景替换(with 后处理)
# # 1. Windows
# !python src/seg_demo.py \
# --config inference_models/human_pp_humansegv2_mobile_192x192_inference_model_with_softmax/deploy.yaml \
# --video_path D:/WorkSpace/DeepLearning/WebsiteV2/Images/Projects/Project018HumanSegmentation/video_test_me.mp4 \
# --bg_img_path D:/WorkSpace/DeepLearning/WebsiteV2/Images/Projects/Project018HumanSegmentation/bg3.jpg \
# --save_dir D:/WorkSpace/DeepLearning/WebsiteV2/Images/Projects/Project018HumanSegmentation/video_test_me_replace_with_post_process.avi \
# --use_post_process
# 2. AIStudio/Linux
!python src/seg_demo.py \
--config inference_models/human_pp_humansegv2_mobile_192x192_inference_model_with_softmax/deploy.yaml \
--video_path /home/aistudio/work/data/Mike.mp4 \
--bg_img_path /home/aistudio/work/data/bg3.jpg \
--save_dir /home/aistudio/work/results/Mike_replace_with_post_process.avi \
--use_post_process
| 原始视频 | 背景移除 | 背景移除(后处理) | 背景替换 | 背景替换(后处理) |
|---|---|---|---|---|
相比摄像头,基于视频的图像移除清晰度更好一些。(PS:结果视频文件需要下载到本地才能进行播放。)
4.3.3 对单张图片进行分割
下面我们使用四种不同的模型对图片进行分割处理,不难发现性能更好的模型(DeepLabv3+)可以获得更好的推理结果,但同样也需要更长的推理时间。使用性能较好的模型对于提高分割精度有重要意义,适合一些离线应用;而使用效率较高的模型有利于提高推理速度,适合一些实时性要求较高的应用。
- 背景移除
# 1. Windows
# !python src/seg_demo.py \
# --config inference_models/portrait_pp_humansegv2_lite_256x144_inference_model_with_softmax/deploy.yaml \
# --img_path /home/aistudio/work/data/nezha.jpg \
# --save_dir /home/aistudio/work/results/nezha_remove_portrait_pp_humansegv2_lite_256x144.jpg
# 2. AIStudio/Linux
!python src/seg_demo.py \
--config inference_models/portrait_pp_humansegv2_lite_256x144_inference_model_with_softmax/deploy.yaml \
--img_path /home/aistudio/work/data/nezha.jpg \
--save_dir /home/aistudio/work/results/nezha_remove_portrait_pp_humansegv2_lite_256x144.jpg

- 背景替换一
# 1. Windows
# !python src/seg_demo.py \
# --config inference_models/portrait_pp_humansegv1_lite_398x224_inference_model_with_softmax/deploy.yaml \
# --img_path /home/aistudio/work/images/nezha.jpg \
# --bg_img_path /home/aistudio/work/images/bg3.jpg \
# --save_dir /home/aistudio/work/results/nezha_replace_human_pp_deeplabv3p.jpg
# 2. AIStudio/Linux
!python src/seg_demo.py \
--config inference_models/portrait_pp_humansegv1_lite_398x224_inference_model_with_softmax/deploy.yaml \
--img_path /home/aistudio/work/data/nezha.jpg \
--bg_img_path /home/aistudio/work/data/bg3.jpg \
--save_dir /home/aistudio/work/results/nezha_replace_portrait_pp_humansegv1_lite_398x224.jpg

- 背景替换二
下面我们使用同一副图像实现多种不同背景的替换,该任务类似于证件照的背景替换。
# 1. Windows
# !python src/seg_demo.py \
# --config inference_models/human_pp_humansegv2_mobile_192x192_inference_model_with_softmax/deploy.yaml \
# --img_path D:/WorkSpace/DeepLearning/WebsiteV2/Images/Projects/Project018HumanSegmentation/photo.png \
# --bg_img_path D:/WorkSpace/DeepLearning/WebsiteV2/Images/Projects/Project018HumanSegmentation/background_scene1.png \
# --save_dir D:/WorkSpace/DeepLearning/WebsiteV2/Images/Projects/Project018HumanSegmentation/photo_scene1.png
# 2. AIStudio/Linux
!python src/seg_demo.py \
--config inference_models/human_pp_humansegv2_mobile_192x192_inference_model_with_softmax/deploy.yaml \
--img_path /home/aistudio/work/data/photo.png \
--bg_img_path /home/aistudio/work/data/background_scene1.png \
--save_dir /home/aistudio/work/results/photo_scene1.png

【任务五】模型训练和评估验证
任务描述: 图像分割是计算机视觉的重要人物之一,这其中对于人像的分割是图像分割的重要任务之一,它的主要功能是实现将人物和背景在像素级别进行区分,具有广泛的应用。一般而言,该任务可以分为两类:针对半身人像的分割,简称肖像分割;针对全身和半身人像的分割,简称通用人像分割。肖像分割和通用人像分割往往都需要根据不同的任务选择合适的模型,实现基本的人像分割应用。本项目主要实现分割任务的模型训练和验证。
任务要求:
- 学会使用预训练模型进行模型的微调训练
- 学会针对不同的任务实现模型配置文件的修改
- 能够利用PaddleSeg实现人像分割模型的训练、验证和模型导出
- 学会收集和整理训练日志,并分析训练日志,了解模型训练过程
模型训练一般分为两种方式,一种是使用大规模的原始图像数据直接从头开始训练(train from scatch),即使用随机初始化的方式初始化化权重参数,然后从随机噪声开始进行训练;另外一种是使用迁移学习的方式从一个已经训练好的预训练模型开始训练(Fine-tuning),即从预训练好的参数开始进行训练。为了简化训练过程,本项目使用后者从一个已经训练好的预训练模型开始训练。此外,本项目完全使用PaddleSeg接口进行训练、评估和预测。
以下示例代码提供了 命令行 的执行模式和 JupyterLab 的执行模式,理论上两种方式都可以实现模型训练,但为了便于查看执行过程,建议使用命令行模式进行训练。因为,JupyterLab模式在训练和执行过程中,日志不会即时显示,必须要等程序运行结束后才会一次性打印到控制台。
5.1 预训练模型下载
下列代码可以实现预训练模型的下载,下载前同样需要先将工作目录切换到 work/PaddleSeg-release-2.10/contrib/PP-HumanSeg。
>> cd work/PaddleSeg-release-2.10/contrib/PP-HumanSeg
>> python src/download_pretrained_models.py
5.2 模型训练
在本项目中,我们使用抽取的 mini_supervisely 数据集进行训练,并使用 human_pp_humansegv1_lite, ``human_pp_humansegv2_lite和human_pp_humansegv1_server` 三个模型进行训练、评估和推理。
Note:因训练时间较长,因此建议使用 命令提示行 执行下列训练代码。
- 命令行模式
>> python ../../tools/train.py --config configs/human_pp_humansegv1_lite.yml --save_dir saved_model/human_pp_humansegv1_lite --save_interval 100 --do_eval
在以上命令中,
train.py 是主程序;
--config 定义yml配置文件;
--save_dir 定义结果输出路径;
--save_interval 定义结果保存的间隔时间,此处表示100次iter保存一次,同时完成一次验证;
--do_eval 表示训练的过程中启用验证测试,测试间隔由 --save_interval 进行定义。
对于配置文件 configs/human_pp_humansegv1_lite.yml 有兴趣的同学可以将其与课堂上的知识进行对照研究。例如,缩短迭代训练的次数 iters 可以减少等待时间,但也可能导致模型训练结束时尚未收敛。
- JupyterLab模式
!python ../../tools/train.py \
--config configs/human_pp_humansegv1_lite.yml \
--save_dir saved_model/human_pp_humansegv1_lite \
--save_interval 100 \
--do_eval
aistudio@jupyter-249713-8839437:~/work/PaddleSeg-release-2.10/contrib/PP-HumanSeg$ python ../../tools/train.py --config configs/human_pp_humansegv1_lite.yml --save_dir saved_model/human_pp_humansegv1_lite --save_interval 100 --do_eval
[2025/03/06 21:48:50] INFO:
------------Environment Information-------------
platform: Linux-5.4.0-139-generic-x86_64-with-glibc2.31
Python: 3.10.10 (main, Mar 21 2023, 18:45:11) [GCC 11.2.0]
Paddle compiled with cuda: True
NVCC: Build cuda_11.8.r11.8/compiler.31833905_0
cudnn: 8.9
GPUs used: 1
CUDA_VISIBLE_DEVICES: None
GPU: ['GPU 0: Tesla V100-SXM2-32GB']
GCC: gcc (Ubuntu 9.4.0-1ubuntu1~20.04.2) 9.4.0
PaddleSeg: 0.0.0.dev0
PaddlePaddle: 3.0.0-beta2
OpenCV: 4.5.5
------------------------------------------------
[2025/03/06 21:48:50] INFO:
---------------Config Information---------------
batch_size: 8
iters: 1000
train_dataset:
dataset_root: data/mini_supervisely
mode: train
num_classes: 2
train_path: data/mini_supervisely/train.txt
transforms:
- target_size:
- 192
- 192
type: Resize
- scale_step_size: 0
type: ResizeStepScaling
- type: RandomRotation
- crop_size:
- 192
- 192
type: RandomPaddingCrop
- type: RandomHorizontalFlip
- type: RandomDistort
- prob: 0.3
type: RandomBlur
- type: Normalize
type: Dataset
val_dataset:
dataset_root: data/mini_supervisely
mode: val
num_classes: 2
transforms:
- target_size:
- 192
- 192
type: Resize
- type: Normalize
type: Dataset
val_path: data/mini_supervisely/val.txt
optimizer:
momentum: 0.9
type: sgd
weight_decay: 0.0005
lr_scheduler:
end_lr: 0
learning_rate: 0.0001
power: 0.9
type: PolynomialDecay
loss:
coef:
- 1
types:
- coef:
- 0.8
- 0.2
losses:
- type: CrossEntropyLoss
- type: LovaszSoftmaxLoss
type: MixedLoss
model:
align_corners: false
num_classes: 2
pretrained: https://paddleseg.bj.bcebos.com/dygraph/pp_humanseg_v2/human_pp_humansegv1_lite_192x192_pretrained.zip
type: PPHumanSegLite
export:
transforms:
- target_size:
- 192
- 192
type: Resize
- type: Normalize
------------------------------------------------
[2025/03/06 21:48:50] INFO: Set device: gpu
[2025/03/06 21:48:50] INFO: Use the following config to build model
model:
align_corners: false
num_classes: 2
pretrained: https://paddleseg.bj.bcebos.com/dygraph/pp_humanseg_v2/human_pp_humansegv1_lite_192x192_pretrained.zip
type: PPHumanSegLite
W0306 21:48:50.596593 6224 gpu_resources.cc:119] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 12.0, Runtime API Version: 11.8
W0306 21:48:50.596652 6224 gpu_resources.cc:164] device: 0, cuDNN Version: 8.9.
[2025/03/06 21:48:56] INFO: Loading pretrained model from https://paddleseg.bj.bcebos.com/dygraph/pp_humanseg_v2/human_pp_humansegv1_lite_192x192_pretrained.zip
Connecting to https://paddleseg.bj.bcebos.com/dygraph/pp_humanseg_v2/human_pp_humansegv1_lite_192x192_pretrained.zip
Downloading human_pp_humansegv1_lite_192x192_pretrained.zip
[==================================================] 100.00%
Uncompress human_pp_humansegv1_lite_192x192_pretrained.zip
[==================================================] 100.00%
[2025/03/06 21:48:56] INFO: There are 340/340 variables loaded into PPHumanSegLite.
[2025/03/06 21:48:56] INFO: Use the following config to build train_dataset
train_dataset:
dataset_root: data/mini_supervisely
mode: train
num_classes: 2
train_path: data/mini_supervisely/train.txt
transforms:
- target_size:
- 192
- 192
type: Resize
- scale_step_size: 0
type: ResizeStepScaling
- type: RandomRotation
- crop_size:
- 192
- 192
type: RandomPaddingCrop
- type: RandomHorizontalFlip
- type: RandomDistort
- prob: 0.3
type: RandomBlur
- type: Normalize
type: Dataset
[2025/03/06 21:48:56] INFO: Use the following config to build val_dataset
val_dataset:
dataset_root: data/mini_supervisely
mode: val
num_classes: 2
transforms:
- target_size:
- 192
- 192
type: Resize
- type: Normalize
type: Dataset
val_path: data/mini_supervisely/val.txt
[2025/03/06 21:48:56] INFO: If the type is SGD and momentum in optimizer config, the type is changed to Momentum.
[2025/03/06 21:48:56] INFO: Use the following config to build optimizer
optimizer:
momentum: 0.9
type: Momentum
weight_decay: 0.0005
[2025/03/06 21:48:56] INFO: Use the following config to build loss
loss:
coef:
- 1
types:
- coef:
- 0.8
- 0.2
losses:
- type: CrossEntropyLoss
- type: LovaszSoftmaxLoss
type: MixedLoss
/opt/conda/envs/python35-paddle120-env/lib/python3.10/site-packages/paddle/nn/layer/norm.py:818: UserWarning: When training, we now always track global mean and variance.
warnings.warn(
[2025/03/06 21:49:04] INFO: [TRAIN] epoch: 1, iter: 10/1000, loss: 0.5410, lr: 0.000099, batch_cost: 0.7412, reader_cost: 0.17556, ips: 10.7935 samples/sec, max_mem_reserved: 306 MB, max_mem_allocated: 263 MB | ETA 00:12:13
[2025/03/06 21:49:08] INFO: [TRAIN] epoch: 1, iter: 20/1000, loss: 0.5360, lr: 0.000098, batch_cost: 0.4500, reader_cost: 0.32141, ips: 17.7787 samples/sec, max_mem_reserved: 306 MB, max_mem_allocated: 263 MB | ETA 00:07:20
[2025/03/06 21:49:12] INFO: [TRAIN] epoch: 2, iter: 30/1000, loss: 0.5740, lr: 0.000097, batch_cost: 0.4006, reader_cost: 0.27697, ips: 19.9676 samples/sec, max_mem_reserved: 306 MB, max_mem_allocated: 263 MB | ETA 00:06:28
[2025/03/06 21:49:16] INFO: [TRAIN] epoch: 2, iter: 40/1000, loss: 0.4963, lr: 0.000096, batch_cost: 0.3580, reader_cost: 0.23838, ips: 22.3476 samples/sec, max_mem_reserved: 306 MB, max_mem_allocated: 263 MB | ETA 00:05:43
[2025/03/06 21:49:20] INFO: [TRAIN] epoch: 2, iter: 50/1000, loss: 0.4150, lr: 0.000096, batch_cost: 0.4292, reader_cost: 0.31825, ips: 18.6393 samples/sec, max_mem_reserved: 306 MB, max_mem_allocated: 263 MB | ETA 00:06:47
[2025/03/06 21:49:23] INFO: [TRAIN] epoch: 3, iter: 60/1000, loss: 0.3682, lr: 0.000095, batch_cost: 0.3401, reader_cost: 0.24402, ips: 23.5233 samples/sec, max_mem_reserved: 306 MB, max_mem_allocated: 263 MB | ETA 00:05:19
[2025/03/06 21:49:27] INFO: [TRAIN] epoch: 3, iter: 70/1000, loss: 0.3740, lr: 0.000094, batch_cost: 0.3984, reader_cost: 0.31738, ips: 20.0783 samples/sec, max_mem_reserved: 306 MB, max_mem_allocated: 263 MB | ETA 00:06:10
......
[2025/03/06 21:56:08] INFO: [TRAIN] epoch: 38, iter: 950/1000, loss: 0.2828, lr: 0.000007, batch_cost: 0.4082, reader_cost: 0.29815, ips: 19.5965 samples/sec, max_mem_reserved: 306 MB, max_mem_allocated: 265 MB | ETA 00:00:20
[2025/03/06 21:56:12] INFO: [TRAIN] epoch: 39, iter: 960/1000, loss: 0.2808, lr: 0.000006, batch_cost: 0.3902, reader_cost: 0.29046, ips: 20.5030 samples/sec, max_mem_reserved: 306 MB, max_mem_allocated: 265 MB | ETA 00:00:15
[2025/03/06 21:56:15] INFO: [TRAIN] epoch: 39, iter: 970/1000, loss: 0.3024, lr: 0.000004, batch_cost: 0.3421, reader_cost: 0.22416, ips: 23.3860 samples/sec, max_mem_reserved: 306 MB, max_mem_allocated: 265 MB | ETA 00:00:10
[2025/03/06 21:56:19] INFO: [TRAIN] epoch: 40, iter: 980/1000, loss: 0.3132, lr: 0.000003, batch_cost: 0.4175, reader_cost: 0.29797, ips: 19.1614 samples/sec, max_mem_reserved: 306 MB, max_mem_allocated: 265 MB | ETA 00:00:08
[2025/03/06 21:56:23] INFO: [TRAIN] epoch: 40, iter: 990/1000, loss: 0.2474, lr: 0.000002, batch_cost: 0.3701, reader_cost: 0.26007, ips: 21.6171 samples/sec, max_mem_reserved: 306 MB, max_mem_allocated: 265 MB | ETA 00:00:03
[2025/03/06 21:56:27] INFO: [TRAIN] epoch: 40, iter: 1000/1000, loss: 0.2740, lr: 0.000000, batch_cost: 0.4033, reader_cost: 0.28684, ips: 19.8347 samples/sec, max_mem_reserved: 306 MB, max_mem_allocated: 265 MB | ETA 00:00:00
[2025/03/06 21:56:27] INFO: Start evaluating (total_samples: 100, total_iters: 100)...
100/100 [==============================] - 6s 56ms/step - batch_cost: 0.0556 - reader cost: 0.0169
[2025/03/06 21:56:33] INFO: [EVAL] #Images: 100 mIoU: 0.8234 Acc: 0.9231 Kappa: 0.8025 Dice: 0.9012
[2025/03/06 21:56:33] INFO: [EVAL] Class IoU:
[0.9006 0.7463]
[2025/03/06 21:56:33] INFO: [EVAL] Class Precision:
[0.939 0.8773]
[2025/03/06 21:56:33] INFO: [EVAL] Class Recall:
[0.9566 0.8332]
[2025/03/06 21:56:33] INFO: [EVAL] The model with the best validation mIoU (0.8322) was saved at iter 800.
<class 'paddle.nn.layer.conv.Conv2D'>'s flops has been counted
<class 'paddle.nn.layer.norm.BatchNorm2D'>'s flops has been counted
Total Flops: 110028672 Total Params: 137466
在上面的训练日志中,可以看到训练过程和评估过程的信息。训练过程包括每个epoch的迭代次数、损失值、学习率、每批次的处理时间、读取数据的时间、每秒处理的样本数、最大内存使用情况等。评估过程包括验证集上的mIoU、Acc、Kappa、Dice等指标,以及每个类别的IoU、Precision和Recall。
下面给出训练过程中的日志文件。
- 在
---Environment Information---中给出了基本环境信息,包括操作系统Windows10,python版本3.11.7,Paddle启用了CUDA,cudnn版本9.0,并使用1个GPU进行运算,PaddleSeg版本2.10.0,Paddle版本3.0.0-beta1,OpenCV版本4.5.5. - 在
---Config Information---,给出了模型的配置信息,这些超参数由human_pp_humansegv1_lite.yml进行定义,包括batch_size,输入尺寸,迭代次数,学习率,模型设置,优化器,训练数据,测试数据等信息。 - 在接下来的训练过程中,给出了训练过程中的迭代次数,周期数,损失,学习率和IPS;每隔100个iter进行一次评估验证,并给出了验证图像的数量100,以及两个重要的评价指标mIoU和Acc。
- 注意下面的训练流程使用的是迁移学习,由于当前使用的模型比较简单,并且训练数据也只是一个非常小的子集,因此很快就收敛了,模型性能改进也很小。
- 这里同时给出完整的
iter=1000的 训练日志。
5.3 模型评估
模型评估需要在项目文件夹中执行 val.py 文件,同时需要指定好 --config 配置文件和 --model_path 训练好的模型文件。配置文件需要指定前向传输相关的超参数。在项目中,为了便于查看程序执行的反馈信息,建议使用命令提示行执行验证,命令如下:
>> python ../../tools/val.py --config configs/human_pp_humansegv1_lite.yml --model_path saved_model/human_pp_humansegv1_lite/best_model/model.pdparams
若要在Notebook中执行,需要先切换到项目目录,然后在 python 命令前增加 !,再进行执行。
!python ../../tools/val.py \
--config configs/human_pp_humansegv1_lite.yml \
--model_path saved_model/human_pp_humansegv1_lite/best_model/model.pdparams
[2025/03/06 22:04:10] INFO:
------------Environment Information-------------
platform: Linux-5.4.0-139-generic-x86_64-with-glibc2.31
Python: 3.10.10 (main, Mar 21 2023, 18:45:11) [GCC 11.2.0]
Paddle compiled with cuda: True
NVCC: Build cuda_11.8.r11.8/compiler.31833905_0
cudnn: 8.9
GPUs used: 1
CUDA_VISIBLE_DEVICES: None
GPU: ['GPU 0: Tesla V100-SXM2-32GB']
GCC: gcc (Ubuntu 9.4.0-1ubuntu1~20.04.2) 9.4.0
PaddleSeg: 0.0.0.dev0
PaddlePaddle: 3.0.0-beta2
OpenCV: 4.5.5
------------------------------------------------
[2025/03/06 22:04:10] INFO:
---------------Config Information---------------
batch_size: 8
iters: 1000
train_dataset:
dataset_root: data/mini_supervisely
mode: train
num_classes: 2
train_path: data/mini_supervisely/train.txt
transforms:
- target_size:
- 192
- 192
type: Resize
- scale_step_size: 0
type: ResizeStepScaling
- type: RandomRotation
- crop_size:
- 192
- 192
type: RandomPaddingCrop
- type: RandomHorizontalFlip
- type: RandomDistort
- prob: 0.3
type: RandomBlur
- type: Normalize
type: Dataset
val_dataset:
dataset_root: data/mini_supervisely
mode: val
num_classes: 2
transforms:
- target_size:
- 192
- 192
type: Resize
- type: Normalize
type: Dataset
val_path: data/mini_supervisely/val.txt
optimizer:
momentum: 0.9
type: sgd
weight_decay: 0.0005
lr_scheduler:
end_lr: 0
learning_rate: 0.0001
power: 0.9
type: PolynomialDecay
loss:
coef:
- 1
types:
- coef:
- 0.8
- 0.2
losses:
- type: CrossEntropyLoss
- type: LovaszSoftmaxLoss
type: MixedLoss
model:
align_corners: false
num_classes: 2
pretrained: https://paddleseg.bj.bcebos.com/dygraph/pp_humanseg_v2/human_pp_humansegv1_lite_192x192_pretrained.zip
type: PPHumanSegLite
export:
transforms:
- target_size:
- 192
- 192
type: Resize
- type: Normalize
------------------------------------------------
[2025/03/06 22:04:10] INFO: Set device: gpu
[2025/03/06 22:04:10] INFO: Use the following config to build model
model:
align_corners: false
num_classes: 2
pretrained: https://paddleseg.bj.bcebos.com/dygraph/pp_humanseg_v2/human_pp_humansegv1_lite_192x192_pretrained.zip
type: PPHumanSegLite
W0306 22:04:10.522313 27408 gpu_resources.cc:119] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 12.0, Runtime API Version: 11.8
W0306 22:04:10.522353 27408 gpu_resources.cc:164] device: 0, cuDNN Version: 8.9.
[2025/03/06 22:04:15] INFO: Loading pretrained model from https://paddleseg.bj.bcebos.com/dygraph/pp_humanseg_v2/human_pp_humansegv1_lite_192x192_pretrained.zip
[2025/03/06 22:04:15] INFO: There are 340/340 variables loaded into PPHumanSegLite.
[2025/03/06 22:04:15] INFO: Loading pretrained model from saved_model/human_pp_humansegv1_lite/best_model/model.pdparams
[2025/03/06 22:04:15] INFO: There are 340/340 variables loaded into PPHumanSegLite.
[2025/03/06 22:04:15] INFO: Loaded trained weights successfully.
[2025/03/06 22:04:15] INFO: Use the following config to build val_dataset
val_dataset:
dataset_root: data/mini_supervisely
mode: val
num_classes: 2
transforms:
- target_size:
- 192
- 192
type: Resize
- type: Normalize
type: Dataset
val_path: data/mini_supervisely/val.txt
[2025/03/06 22:04:15] INFO: Start evaluating (total_samples: 100, total_iters: 100)...
100/100 [==============================] - 9s 92ms/step - batch_cost: 0.0922 - reader cost: 0.0212
[2025/03/06 22:04:25] INFO: [EVAL] #Images: 100 mIoU: 0.8322 Acc: 0.9275 Kappa: 0.8134 Dice: 0.9067
[2025/03/06 22:04:25] INFO: [EVAL] Class IoU:
[0.9061 0.7584]
[2025/03/06 22:04:25] INFO: [EVAL] Class Precision:
[0.9411 0.888 ]
[2025/03/06 22:04:25] INFO: [EVAL] Class Recall:
[0.9606 0.8387]
PaddleSeg 默认会打印出配置文件信息 ----Config Information----,验证过程,以及验证结果(注意Notebook中结果打印顺序略有瑕疵,默认配置文件信息在最前面)。其中验证的结果包括,在整个验证集上的平均IoU和精度ACC,以及每个类别的IoU和ACC。
在图像分割领域中,评估模型质量主要是通过三个指标进行判断:准确率(acc)、平均交并比(Mean Intersection over Union,简称mIoU)、Kappa系数。
-
准确率:指类别预测正确的像素占总像素的比例,准确率越高模型质量越好。
-
平均交并比:对每个类别数据集单独进行推理计算,计算出的预测区域和实际区域交集除以预测区域和实际区域的并集,然后将所有类别得到的结果取平均。在本例中,正常情况下模型在验证集上的mIoU指标值会达到0.80以上,显示信息示例如上所示的 mIoU=0.9266 即为mIoU。
-
Kappa系数:一个用于一致性检验的指标,可以用于衡量分类的效果。kappa系数的计算是基于混淆矩阵的,取值为-1到1之间,通常大于0。其公式如下所示,,其中 为分类器的准确率, 为期望的准确率。Kappa系数越高模型质量越好。
-
三个模型的评估结果
| 模型名称 | mIoU | Acc | Kappa | Dice |
|---|---|---|---|---|
| human_pp_humansegv1_lite | 0.8295 | 0.9263 | 0.8100 | 0.9050 |
| human_pp_humansegv2_lite | 0.9266 | 0.9696 | 0.9232 | 0.9616 |
| human_pp_humansegv1_server | 0.9599 | 0.9837 | 0.9589 | 0.9795 |
【任务六】模型预测(推理)
任务描述: 在PaddleSeg中,使用给定的图片在训练好的模型上进行推理和预测。
任务要求:
- 能够在命令行中使用训练好的模型对给定图片进行推理和预测;
- 能够Notebook中使用训练好的模型对给定图片进行推理和预测;
- 能够将推理生成的图片进行可视化。
6.1 基于命令行的模型推理
模型预测(推理)同样需要在项目文件夹中执行,执行程序为 predict.py;同样需要指定好 --config 配置文件和 --model_path 训练好的模型文件。此外,待推理文件由 --image_path 进行指定,可以是一个图片,例如 data\test.jpg;也可以是一个目录例如 data/predict,当指定路径为目录时,会自动预测路径下的所有图片文件,包括子目录中的图片文件。参数 --save_dir (可省略) 用于设置输出目录,默认值为 ./output/result。在项目中,为了便于查看程序执行的反馈信息,建议使用命令提示行执行验证,命令如下:
>> python ../../tools/predict.py --config configs/human_pp_humansegv1_server.yml --model_path saved_model/human_pp_humansegv1_server/best_model/model.pdparams --image_path data/predict --save_dir output/human_pp_humansegv1_server
在输出路径 ./output/xxx/ 路径下,会生成两个文件夹 added_prediction 和 pseudo_color_prediction。前者用于保存分割结果和原始图片的叠加,便于对分割结果进行理解,数据格式和原始图片一致;后者为单纯的分割结果,数据格式为 .png,和标注文件一致。
6.2 基于JupyterLab的模型推理
若要在JupyterLab中执行,需要在 python 命令前增加 !,同时将工作目录切换到项目文件夹。
!python ../../tools/predict.py \
--config configs/human_pp_humansegv1_lite.yml \
--model_path saved_model/human_pp_humansegv1_lite/best_model/model.pdparams \
--image_path ../../../data/predict \
--save_dir output/human_pp_humansegv1_lite
/opt/conda/envs/python35-paddle120-env/lib/python3.10/site-packages/paddle/utils/cpp_extension/extension_utils.py:686: UserWarning: No ccache found. Please be aware that recompiling all source files may be required. You can download and install ccache from: https://github.com/ccache/ccache/blob/master/doc/INSTALL.md
warnings.warn(warning_message)
[2025/03/07 07:46:07] INFO:
------------Environment Information-------------
platform: Linux-5.4.0-139-generic-x86_64-with-glibc2.31
Python: 3.10.10 (main, Mar 21 2023, 18:45:11) [GCC 11.2.0]
Paddle compiled with cuda: True
NVCC: Build cuda_11.8.r11.8/compiler.31833905_0
cudnn: 8.9
GPUs used: 1
CUDA_VISIBLE_DEVICES: None
GPU: ['GPU 0: Tesla V100-SXM2-32GB']
GCC: gcc (Ubuntu 9.4.0-1ubuntu1~20.04.2) 9.4.0
PaddleSeg: 0.0.0.dev0
PaddlePaddle: 3.0.0-beta2
OpenCV: 4.5.5
------------------------------------------------
[2025/03/07 07:46:07] INFO:
---------------Config Information---------------
batch_size: 8
iters: 1000
train_dataset:
dataset_root: data/mini_supervisely
mode: train
num_classes: 2
train_path: data/mini_supervisely/train.txt
transforms:
- target_size:
- 192
- 192
type: Resize
- scale_step_size: 0
type: ResizeStepScaling
- type: RandomRotation
- crop_size:
- 192
- 192
type: RandomPaddingCrop
- type: RandomHorizontalFlip
- type: RandomDistort
- prob: 0.3
type: RandomBlur
- type: Normalize
type: Dataset
val_dataset:
dataset_root: data/mini_supervisely
mode: val
num_classes: 2
transforms:
- target_size:
- 192
- 192
type: Resize
- type: Normalize
type: Dataset
val_path: data/mini_supervisely/val.txt
optimizer:
momentum: 0.9
type: sgd
weight_decay: 0.0005
lr_scheduler:
end_lr: 0
learning_rate: 0.0001
power: 0.9
type: PolynomialDecay
loss:
coef:
- 1
types:
- coef:
- 0.8
- 0.2
losses:
- type: CrossEntropyLoss
- type: LovaszSoftmaxLoss
type: MixedLoss
model:
align_corners: false
num_classes: 2
pretrained: https://paddleseg.bj.bcebos.com/dygraph/pp_humanseg_v2/human_pp_humansegv1_lite_192x192_pretrained.zip
type: PPHumanSegLite
export:
transforms:
- target_size:
- 192
- 192
type: Resize
- type: Normalize
------------------------------------------------
[2025/03/07 07:46:07] INFO: Set device: gpu:0
[2025/03/07 07:46:07] INFO: Use the following config to build model
model:
align_corners: false
num_classes: 2
...
[2025/03/07 07:46:12] INFO: There are 340/340 variables loaded into PPHumanSegLite.
[2025/03/07 07:46:12] INFO: Start to predict...
6/6 [==============================] - 3s 502ms/step
[2025/03/07 07:46:15] INFO: Predicted images are saved in output/human_pp_humansegv1_lite/added_prediction and output/human_pp_humansegv1_lite/pseudo_color_prediction .
Output is truncated. View as a scrollable element or open in a text editor. Adjust cell output settings...
从上述推理过程可以看到,predict.py 对 参数 --image_path 所指定的图片源文件夹 data/predict 中的6幅图片进行以此预测,并保存在参数 --save_dir 所指定的路径 output/result 中。
6.3 预测结果可视化
############ 可视化结果 ##########
import os
import cv2
import paddle
import matplotlib.pyplot as plt
# 设置各种路径
model_name = 'human_pp_humansegv1_lite'
root_path = os.path.join('/home/aistudio/work/PaddleSeg-release-2.10/contrib/PP-HumanSeg/output', model_name)
image_list = []
dirs = os.listdir(root_path)
for dir in dirs:
img_list = os.listdir(os.path.join(root_path, dir))
for img in img_list:
img_path = os.path.join(root_path, dir, img)
image_list.append(img_path)
plt.figure(figsize=(18,5))
plt.title(model_name)
plt.gca().axis('off')
n = len(image_list)
for i in range(n):
img = cv2.imread(image_list[i])
img = cv2.resize(img, (400, 250), interpolation=cv2.INTER_AREA)
img_RGB = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
ax = plt.subplot(2,6,i+1)
if i <= 5:
plt.title('Image {}'.format(i+1))
else:
plt.title('Mask {}'.format(i-5))
ax.tick_params(axis='both', labelsize=8)
plt.imshow(img_RGB)
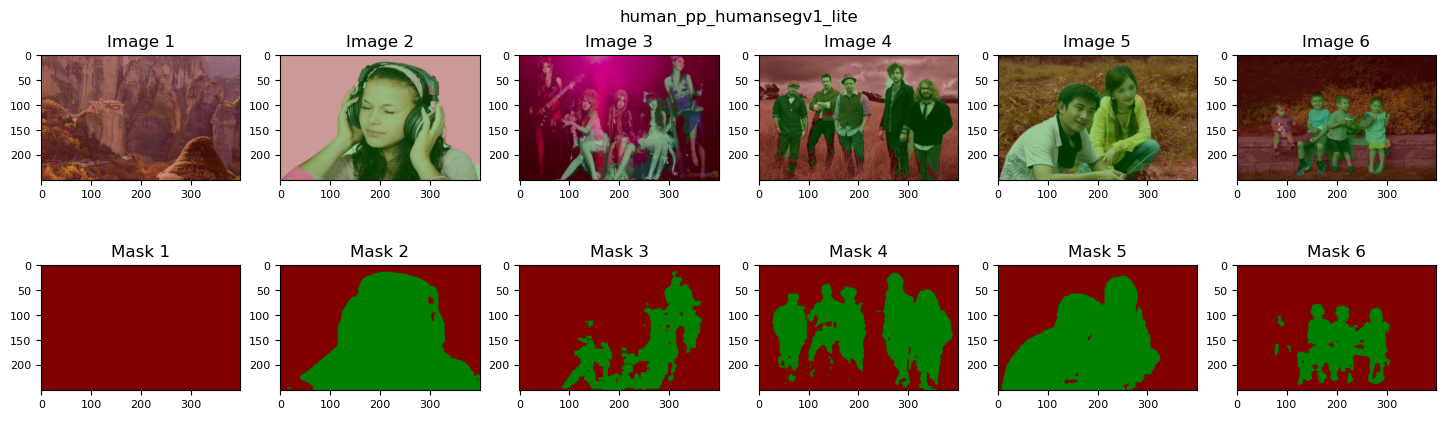
6.4 实验结果分析
为了进一步分析和对比各个模型的性能差异,我们使用 portrait_pp_humansegv1_lite_398x224, human_pp_humansegv2_lite_192x192, human_pp_humansegv1_server_512x512 等三个模型对work/data/pridict 中的6个样本进行预测,并进行可视化。
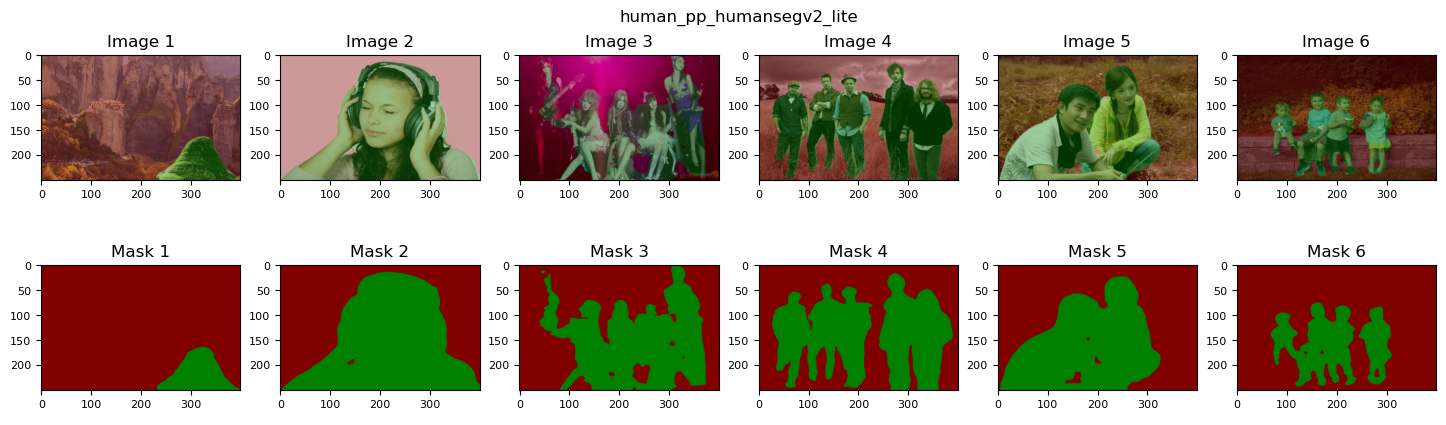
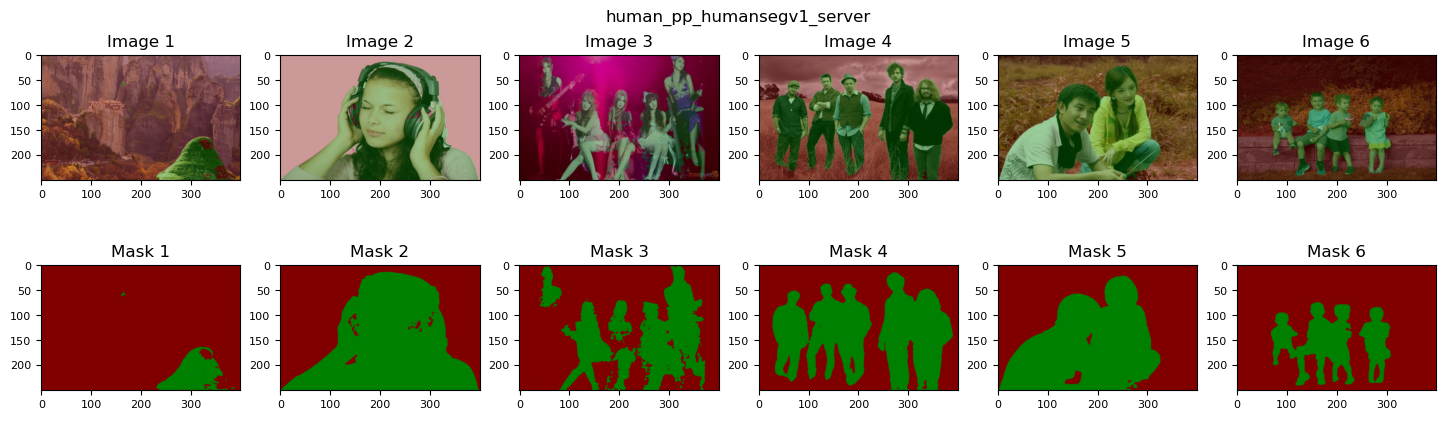
【实验结果分析】
从上面的实验结果可以得出以下结论,
- 整体看,
pp_humansegv1_server和pp_humansegv2_lite的效果比pp_humansegv1_lite的效果要好。 - 在原图1中,只存在背景而不存在行人,但是分割结果仍然有一部分像素被错分成Human类,相对而言判别能力稍弱的
v1_lite反而没有错判 - 图3,4,5 为多人场景,
v1_server和v2_lite表现都不错,并且前者更细腻一些,而后者有一定的过拟合和假阳性存在;v1_lite的主要部分落在了人体部分,但是包裹性并不是特别好,一部分像素没有被容纳,而一部分属于背景的像素却被包裹在内,说明该模型对于主目标存在欠拟合和假阴性。从上面对实验过程的描述,不难发现,分割结果不理想的原因主要有3个,一是训练数据比较少,只有350副图片,使用完整版的HumanSeg数据可以获得更好的性能;二是pp_humansegv1_lite模型比较简单,主要关注的是速度,因此性能并不是特别好。 - 尽管如此,在图2,5中,三个模型都获得了较好的性能。说明简单的背景,并且主目标较为显著的情况下,超轻量级的效率模型也能够获得不错的性能。
在实际应用中,我们可以根据应用场景的不同选择不同的模型。对于背景单一,且简单的模型,可以使用高效率的轻量级模型,甚至超轻量级模型;而对于要求精度比较高的任务,则可以使用DeepLabv3同级别的高精度模型,对于这类模型的使用,通常需要GPU的支持,但是由于参数数量较为庞大,因此也需要更多的推理时间,这类模型并不是很适合实时推理的应用。