【项目002】Python机器学习环境的安装和配置
作者:欧新宇(Xinyu OU)
当前版本:Release v4.0
开发平台:Paddle 2.5.2 PaddleDetection 2.7, PaddleSeg 2.9, PaddleOCR 2.3.3
运行环境:Intel Core i7-7700K CPU 4.2GHz, nVidia GeForce GTX 1080 Ti
本教案所涉及的数据集仅用于教学和交流使用,请勿用作商用。
最后更新:2024年4月23日
本安装说明为 "基于PaddlePaddle的Python深度学习环境" 的安装指南,适用于《程序设计基础(Python)》, 《计算机数学(Python)》,《机器学习》,《深度学习》,《计算机视觉》等课程。 本教案基于Python集成安装包Anaconda,同时使用VSCode编程环境和JupyterLab编程环境作为开发环境。VScode适用于调试完整的Python代码,并将整个项目的所有代码都保存为*.py文件进行发布。Jupyterlab适用于独立代码和模型的调试,特别适合于数据分析和可视化分析。
本项目中需要使用pip从服务器端安装部分软件,为提高下载速度,建议加载清华的源或阿里的源:
阿里源:pip install xxx -i https://pypi.tuna.tsinghua.edu.cn/simple清华源:pip install xxx -i https://mirrors.aliyun.com/pypi/simple
原则上,安装顺序请按照以下序号流程。
一. Python环境的安装和配置
1.1 Python的安装
Python编程环境的安装包含两种方法:
- 基于Python官网原生Python安装程序(不推荐)
- 基于第三方封装版Python,此处推荐Anaconda。Anaconda包含了大量的Python库函数,包括机器学习开发库scikit-learn,基础科学计算库Numpy,数据分析工具Pandas,绘图库Matplotlib等。
- 版本:Anaconda3-2024.02-Windows-x86_64,Python版本3.11
- URL:https://www.anaconda.com/products/individual
- 安装过程较为简单,但后续需要安装各种库时,均需要打开【Anaconda Prompt (Anaconda3)】命令提示行进行安装,包括在《程序设计基础(Python)》课程中使用到的jieba和wordcloud库。
安装时,应务必注意:1. 勾选"Install for Just Me"; 2. 将相关链接库文件添加到PATH中。
1.2 Python环境的测试
# 测试用例一: Hello world!
print("Hello world!")
Hello world!
1.3 安装Python课程所需要的其他库文件
-
安装jieba库
>> pip install jieba -i https://pypi.tuna.tsinghua.edu.cn/simple -
安装wordcloud词云库
>> pip install wordcloud -i https://pypi.tuna.tsinghua.edu.cn/simple
二. 集成开发环境的安装和配置
2.1 Visual Studio Code (VSCode) 编程环境的安装与配置
- VSCode是当今最流行的集成开发环境,不仅适用于Python,也同样适用于Html+CSS、Javascript及php等Web前端的开发,同时也支持Java、C++、C等程序的开发。类似的集成开放环境还有PyCharm、Sublime。安装过程较简单,不再累述。
- URL:https://code.visualstudio.com/Download
2.2 JupyterLab 编程环境的安装与配置
JupyterLab是Anaconda内置的Jupyter Notebook的升级版,完全兼容Notebook开发环境,但在使用上更方便,也集成了一些新的特性。
2.2.1 基于Visual Studio Code的JupyterLab配置
使用VSCode作为JupyterLab的编程环境,需要先安装Jupyter插件。打开VSCode左边工具栏的扩展选项卡,搜索并安装Microsft的 Jupyter、Jupyter Cell Tages 和 Jupyter Keymap 扩展。安装完成后,在VSCode中直接双击打开(或新创建)一个 .ipynb 文件即可。
2.2.2 官方JupyterLab的配置
2.2.1 JupyterLab的安装
本教程使用的 Anaconda3-2024.02-Windows-x86_64 已内置了JupyterLab4.0,因此无需再手动安装。启动方法如下(推荐2.2.3小节的配置方法):
>> jupyter-lab
2.2.2 更新JupyterLab内核(可选)
>> conda update jupyter_core jupyter_client
2.2.3 JupyterLab的配置 (推荐)
JupyterLab最重要的配置是初始路径的设置,下面介绍一种最简单有效的方法:在桌面创建批处理(*.bat)快捷方式,并直接双击启动JupyterLab。该方法可以实现多个路径的同时配置。
1.在桌面上新建一个文本文件,输入以下字段
C:\Users\Administrator\anaconda3\Scripts\jupyter-lab.exe D:\Workspace\DeepLearning
PS: 以上文件包含两个路径,前者为jupyter-lab.exe的路径,后者为工作任务路径。当存在多个工作任务时,只需为每个工作任务单独建立一个bat批处理文件即可
2.将文件另存为MyJupyterLab.bat (或DeepLerning.bat, ComputerVision.bat, ComputerMath.bat)
3.使用时,只需要双击该批处理(*.bat)文件即可
三. Python深度学习环境的安装和配置
以下必需工具包适应于《教育部1+X项目"计算机视觉应用开发"》所涉及的绝大部分课程。具体包括: 百度PaddlePaddle, PaddleDetection, PaddleSeg, LabelMe数据标注工具,opencv-python计算机视觉和机器学习软件库,mscoco库导入工具等。
3.1 百度飞桨PaddlePaddle的安装调试
飞桨的安装和测试比较容易,可以直接参考官网:https://www.paddlepaddle.org.cn/install/quick
值得注意的是,如果需要启用GPU模式,需要先安装 cuda 及 cudnn (具体版本请根据自己的显卡型号,并参考官网paddlepaddle安装说明)。
3.2 Microsoft Visual C++ 14.0 的安装(非常重要)
Microsoft Visual C++ 14.0是一种用于编译C++程序的开发工具集,也称为 Microsoft Visual C++ 2015-2019 Redistributable。由于Paddle很多底层代码都是使用VC++进行编译,因此包括PaddleDetection, PaddleSeg以及 pycocotools工具包等库都需要 Microsoft Visual C++ 14.0 的支持。vc14++ 是一个非常重要的编译库,如不能正常安装将影响后续很多功能包的安装和运行,原始下载地址:http://go.microsoft.com/fwlink/?LinkId=691126 (可能已失效)。
Note
注意,近期发现原版离线安装包有时无法连上服务器(仍可尝试),可直接使用CSDN定制离线包进行安装,文件名 "mu_visual_cpp_build_tools_2015_update_3_x64_dvd_dfd9a39c.iso",下载后装载到虚拟磁盘,并直接运行 "VisualCppBuildTools_Full.exe"。安装时,直接使用经典安装,无需自定义。
3.3 LabelMe标注工具
LabelMe标注工具的安装,需要先安装图形界面编辑工具pyqt,同时需要安装pycocotools。
1.启动【Anaconda Prompt (Anaconda3)】,并执行以下命令:
>> conda create –name=labelme
>> conda install pyqt
>> pip install labelme -i https://pypi.tuna.tsinghua.edu.cn/simple
2.测试LabelMe: 打开命令行,并执行:
>> labelme
3.4 opencv-python
>> pip install opencv-python -i https://mirrors.aliyun.com/pypi/simple/
>> pip install opencv-contrib-python -i https://mirrors.aliyun.com/pypi/simple/ # OpenCV第三方库contrib,支持一些基于opencv的第三方开发包
测试:启动Python,并载入opencv库
>> python
>> import cv2
3.5 pycocotools工具包
pycocotools全称是python api tools of COCO。COCO是由微软倡导了一个大型的图像数据集,用于目标检测、分割、人的关键点检测、素材分割和标题生成。这个包提供了Matlab、Python和luaapi,这些api有助于在COCO中加载、解析和可视化注释。
1. 安装
>> pip install pycocotools -i https://pypi.tuna.tsinghua.edu.cn/simple (使用清华源进行安装)
2. 测试:
启动Python,并载入pycocotools库
>> python
>> import pycocotools
3.6 百度光学字符识别PaddleOCR的安装调试
安装方法如下(根据网络和设备情况不同可能需要2-10分钟):
1. 打开Anaconda Prompt命令提示行
2. 运行如下命令进行安装
>> pip install paddleocr -i https://pypi.tuna.tsinghua.edu.cn/simple
3.7 百度目标检测PaddleDetection
1. 从官网下载PaddleDetection(当前最新版v2.7)
下载地址:https://github.com/PaddlePaddle/PaddleDetection
2. 解压压缩包
解压压缩包 "PaddleDetection-release-2.7.zip" 至工程文件夹并根据任务重命名,例如 "DetectionRoadSign"或"PaddleDetection-release-2.7"(本课程推荐)。
3. 安装PaddleDetection
(1)进入到根目录中
(2)执行安装程序 >> python setup.py install
注:安装过程中,若出现某个库安装失败,则需针对每个库进行安装,直至
requirements.txt中的库都安装完毕。特别关注Cython后面的pycocotools, lap, motmetrics三个库。对于没有安装的库,可以以此使用如下命令进行安装,直至所有库文件都安装完成。
>> pip install motmetrics -i https://pypi.tuna.tsinghua.edu.cn/simple
>> ...
>> python setup.py install
Finished processing dependencies for paddledet==2.7.0
4. 测试
>> python ppdet/modeling/tests/test_architectures.py
Ran 7 tests in 12.816s
OK
5.Inference demo测试
该测试实现模型的下载和测试图片的推理,推理结果保存在 output 文件夹中。
python tools/infer.py -c configs/ppyolo/ppyolo_r50vd_dcn_1x_coco.yml -o use_gpu=true weights=https://paddledet.bj.bcebos.com/models/ppyolo_r50vd_dcn_1x_coco.pdparams --infer_img=demo/000000014439.jpg
3.8 百度分割PaddleSeg
1. 从官网下载PaddleSeg(当前最新版v2.9)
下载地址:https://github.com/PaddlePaddle/PaddleSeg
2. 解压文件到项目文件夹
解压 PaddleSeg-release-2.9.zip 工具包到项目文件夹 MyProjects,建议直接使用带版本的文件夹命名方式 PaddleSeg-release-2.9(便于版本管理)
3. 安装PaddleSeg
(1)进入到根目录中
(2)执行安装程序
1). 将目录切换到: D:/WorkingStation/MyProjects/PaddleSeg-release-2.9
>> pip install -r requirements.txt
>> pip install -v -e .
>> pip install paddleseg
2). 所有安装的包都显示如下信息则表明安装成功:
> Requirement already satisfied:...
注:安装过程中,若出现某个库安装失败,则需针对每个库进行安装,直至 requirements.txt 中的库都安装完毕。
4. 测试
该测试实现模型的自动下载和测试图片的推理,推理结果保存在 output 文件夹中。
>> python tools/predict.py --config configs/quick_start/bisenet_optic_disc_512x512_1k.yml --model_path https://bj.bcebos.com/paddleseg/dygraph/optic_disc/bisenet_optic_disc_512x512_1k/model.pdparams --image_path docs/images/optic_test_image.jpg --save_dir output/result
测试通过将出现如下提示:
...
- type: Normalize
type: OpticDiscSeg
------------------------------------------------
W0410 13:55:31.365703 20260 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 6.1, Driver API Version: 11.1, Runtime API Version: 10.2
W0410 13:55:31.366700 20260 device_context.cc:465] device: 0, cuDNN Version: 7.6.
2022-04-10 13:55:35 [INFO] Number of predict images = 1
2022-04-10 13:55:35 [INFO] Loading pretrained model from https://bj.bcebos.com/paddleseg/dygraph/optic_disc/bisenet_optic_disc_512x512_1k/model.pdparams
2022-04-10 13:55:35 [INFO] There are 356/356 variables loaded into BiSeNetV2.
2022-04-10 13:55:35 [INFO] Start to predict...
1/1 [==============================] - 0s 168ms/step
四. Windows本地环境配置
4.1 Windows文件夹的设置
通常情况下,深度学习项目所涉及的输入、输出较多且复杂,且都需要在程序中进行配置。较为规范的文件夹结构有利于项目的规范运行。下面给出一种典型设置。
首先,在数据盘 D盘 新建一个根目录文件夹 D:/WorkSpace。然后,在该根目录中分别建立6个不同的文件夹,具体功能如下图所示。
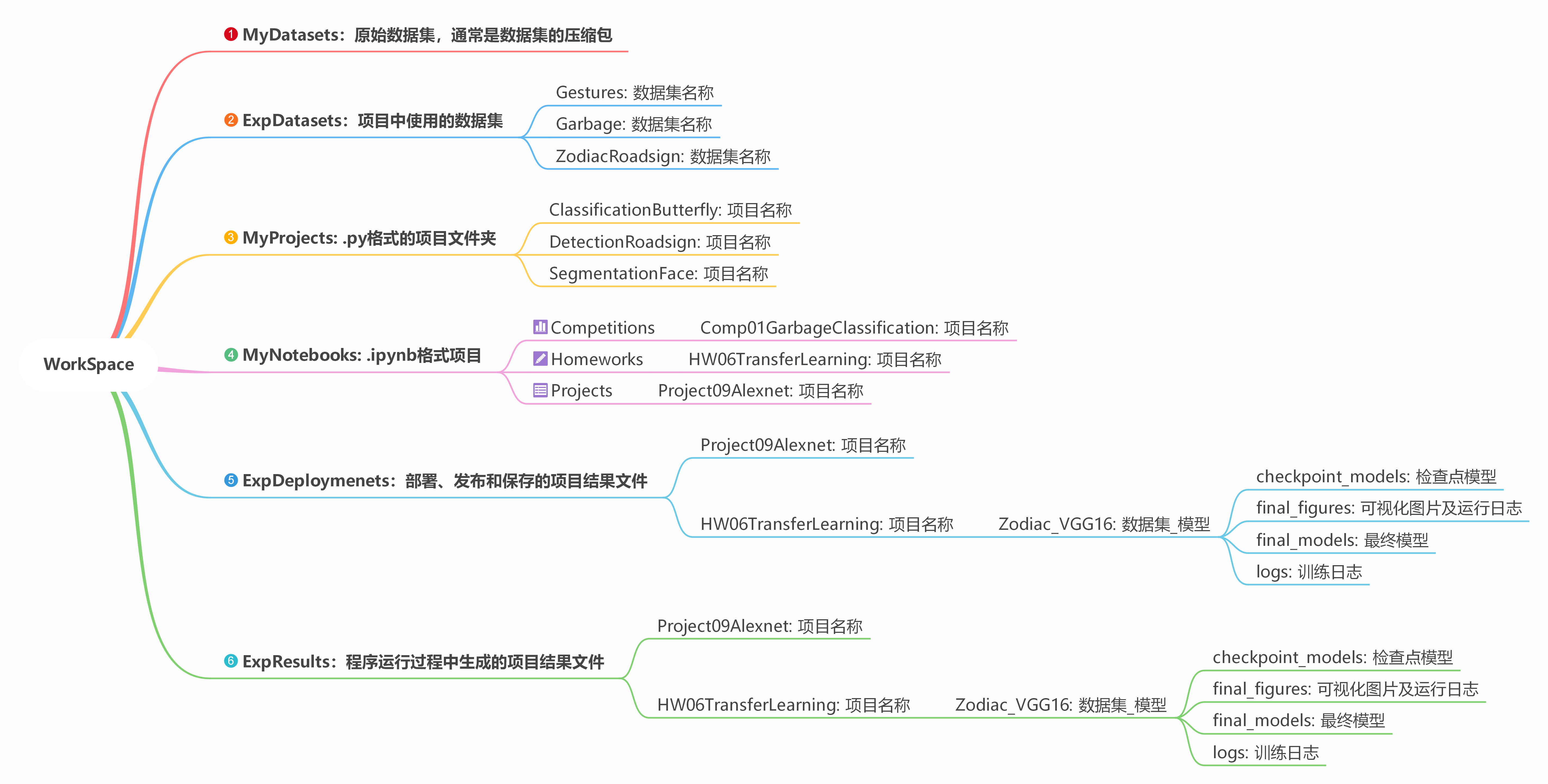
在程序中,通常需要对这些文件夹和项目的基本信息进行定义,包括数据集的根目录 dataset_root_path,训练过程的输出路径 result_root_path, 部署文件夹路径 deployment_root_path:
# 1. 定义根参数
train_parameters = {
'project_name': 'Project07Alexnet', # 定义项目名称
'dataset_name': 'Butterfly', # 定义数据集名称
'architecture': 'Alexnet', # 定义模型名称
'dataset_root_path': 'D:\\Workspace\\ExpDatasets\\', # 定义数据集初始根路径
'result_root_path': 'D:\\Workspace\\ExpResults\\', # 定义输出结果的初始根路径
'deployment_root_path': 'D:\\Workspace\\ExpDeployments\\' # 定义项目部署的初始根路径
}
model_name = train_parameters['dataset_name'] + '_' + train_parameters['architecture'] # 按照 "数据集名称_模型名称"的格式定义模型名称
# 2. 定义数据集路径
dataset_root_path = os.path.join(train_parameters['dataset_root_path'], train_parameters['dataset_name']) # 重写本项目的数据集根路径
json_dataset_info = os.path.join(dataset_root_path, 'dataset_info.json') # 定义数据集信息json文件的读取路径
# 3. 定义训练过程涉及的相关路径
result_root_path = os.path.join(train_parameters['result_root_path'], train_parameters['project_name'], model_name) # 重写本项目的结果路径
checkpoint_models_path = os.path.join(result_root_path, 'checkpoint_models') # 迭代训练模型保存路径
final_models_path = os.path.join(result_root_path, 'final_models') # 最终用于部署和推理的模型
final_figures_path = os.path.join(result_root_path, 'final_figures') # 训练过程曲线图
logs_path = os.path.join(result_root_path, 'logs') # 训练过程日志
# 4. 顶一个验证、测试及布署时的相关路径(文件)
deployment_root_path = os.path.join(train_parameters['deployment_root_path'], train_parameters['project_name'], model_name) # 重写本项目的部署路径
deployment_checkpoint_path = os.path.join(deployment_root_path, 'checkpoint_models') # 定义迭代训练模型的读取路径
deployment_final_models_path = os.path.join(deployment_root_path, 'final_models') # 定义部署模型的路径
deployment_final_figure_path = os.path.join(deployment_root_path, 'final_figures') # 定义模型训练的结果路径
deployment_logs_path = os.path.join(deployment_root_path, 'logs') # 定义模型训练的日志路径
deployment_final_models = os.path.join(deployment_final_models_path, 'final_models', model_name + '_final') # 定义部署模型路径中的final模型
4.2 JupyterLab的设置
请参考本教案 2.2.2 JupyterLab的配置 (可选)。
4.3 VSCode的设置
打开 VSCode,在菜单栏的左上角选择 文件 将文件夹添加到工作区,并选择 D:/WorkSpace 完成Windows目录和VSCode的关联。
五. 机器学习必需库的安装和测试
基于Anaconda开发包安装的Python,已经包含了大多数机器学习和数据分析所需的第三方库,因此不需要再进行额外安装。但如果是基于官方版的Python,则需要额外进行安装,请各位自行查阅安装方法。
1. Paddle 环境的测试
运行如下代码,如果出现 installed successfully, 则说明Paddle安装成功。
import paddle
paddle.utils.run_check()
paddle.__version__
Running verify PaddlePaddle program ...
PaddlePaddle works well on 1 GPU.
PaddlePaddle works well on 1 GPUs.
PaddlePaddle is installed successfully! Let's start deep learning with PaddlePaddle now.
'2.3.2'
2. 基于OpenCV的图像分割
import os
import cv2
import numpy as np
import matplotlib.pyplot as plt
root_path = 'D://Workspace//DeepLearning//Websitev2'
projcet_path = os.path.join(root_path, 'Data', 'Projects', 'Project002Installations')
img = cv2.imread(os.path.join(projcet_path, 'OpenCVTest.png'))
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 将彩色图像转换为灰度图像
ret, img_binary = cv2.threshold(img_gray, 127, 255, cv2.THRESH_BINARY) # 阈值处理,获得二值图像ret
contours, hierarchy = cv2.findContours(img_binary, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE) # opencv 3.4以下版本返回3个值
img_mask = np.zeros(img.shape,np.uint8) # 创建一个和原图一样尺度的掩模图像
img_mask = cv2.drawContours(img_mask, contours, -1, (255,255,255), -1) # 制定轮廓颜色为白色
img_seg = cv2.bitwise_and(img, img_mask) # 通过`按位与`操作,获得有颜色的分割图。及前景图。因为生成的轮廓图是0,1的二值图没有颜色
img_plt = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img_gray_plt = cv2.cvtColor(img_gray, cv2.COLOR_BGR2RGB)
img_mask_plt = cv2.cvtColor(img_mask, cv2.COLOR_BGR2RGB)
img_seg_plt = cv2.cvtColor(img_seg, cv2.COLOR_BGR2RGB)
## 基于Notebook的内嵌式显示
plt.figure(figsize=(16, 8))
ax1 = plt.subplot(2,2,1)
ax1.set_title('img_plt')
plt.imshow(img_plt)
ax2 = plt.subplot(2,2,2)
ax2.set_title('img_gray_plt')
plt.imshow(img_gray_plt)
ax3 = plt.subplot(2,2,3)
ax3.set_title('img_mask_plt')
plt.imshow(img_mask_plt)
ax5 = plt.subplot(2,2,4)
ax5.set_title('img_seg_plt')
plt.imshow(img_seg_plt)
<matplotlib.image.AxesImage at 0x24491a1c9a0>

3. Numpy 基础科学计算库
Numpy是Python中最基础的科学计算库,它的功能主要包括高位数组(Array)计算、线性代数计算、傅里叶变换以及产生伪随机数等。Numpy是机器学习库scikit-learn的重要组成部分,因为机器学习库scikit-learn主要依赖于数组形式的数据来进行处理。
更多信息请参考:RUNOOB站的Numpy栏目:https://www.runoob.com/numpy/numpy-tutorial.html
【项目022】Numpy基础科学库极简使用说明
以下代码用于测试和生成一个数组。
# 使用import关键字引入numpy库,为了简便使用缩写 “np”来表示numpy库。
import numpy as np
# 定义一个变量 i, 用于保存数组
i = np.array([[12,34,56],[78,90,11]])
# 输出变量 i
print("i = \n{}".format(i))
i =
[[12 34 56]
[78 90 11]]
4. Scipy 科学计算工具集
Scipy是Python中用于进行科学计算的工具集,它可以实现计算机统计学分布、信号处理、线性代数方程等功能。在机器学习中,稀疏矩阵的使用非常频繁,Scipy库中的sparse函数可以用来生成这种稀疏矩阵。稀疏矩阵用于存储那些大部分数值为0的np数组。以下代码用使用sparse()函数生成和测试稀疏矩阵。
# 对scipy的使用需要利用from关键字来引用其内部的子库
import numpy as np
from scipy import sparse
# 使用numpy的eye()函数生成一个6行6列的对角矩阵
# 矩阵中对角线上的元素值为 1,其余元素为 0
matrix = np.eye(6)
# 将np数组转化为 CSR格式的Scipy稀疏矩阵 (sparse matrix)
sparse_matrix = sparse.csr_matrix(matrix)
# 输出对角矩阵
print("对角矩阵:\n{}".format(matrix))
对角矩阵:
[[1. 0. 0. 0. 0. 0.]
[0. 1. 0. 0. 0. 0.]
[0. 0. 1. 0. 0. 0.]
[0. 0. 0. 1. 0. 0.]
[0. 0. 0. 0. 1. 0.]
[0. 0. 0. 0. 0. 1.]]
5. Pandas 数据分析工具
Pandas是Python中进行数据分析的库,它具有以下功能
- 生成类似Excel表格式的数据表,并对数据进行修改操作;
- 从不同的数据源中获取数据,例如:SQL Server, Excel表格, CSV文件, Oracle等;
- 在不同的列中使用不同的数据类型,例如:整型,浮点型,字符串型等。
- 更多信息请参考“Pandas中文网”,URL:https://www.pypandas.cn/
# 使用import关键字引入pandas库,为了简便使用缩写 “pd”来表示pandas库。
import pandas as pd
# 使用字典数据类型创建一个数据表,并用pandas库的DataFrame数据结构进行显示
data = {"姓名":["张飞","赵云","夏侯惇","太史慈"],
"归属国":["蜀国","蜀国","魏国","吴国"],
"年龄":[33,28,32,30],
"武力值":[98,97,94,92],
"战斗力":[100,101,98,97]
}
data_frame = pd.DataFrame(data) # 将字典数据类型转换成pandas数据类型
display(data_frame) # 值得注意的是display是Jupyter-iPython内置函数,所以在VS中是不起作用。
# 如果想要把一些数据段进行排除,可以使用查询语句来实现。例如,不显示“魏国”的武将信息
# 使用 “不等于 !=” 操作符排除字段中包含特定值的数据
display(data_frame[data_frame.归属国 != "魏国"])
姓名 归属国 年龄 武力值 战斗力 0 张飞 蜀国 33 98 100 1 赵云 蜀国 28 97 101 2 夏侯惇 魏国 32 94 98 3 太史慈 吴国 30 92 97
姓名 归属国 年龄 武力值 战斗力 0 张飞 蜀国 33 98 100 1 赵云 蜀国 28 97 101 3 太史慈 吴国 30 92 97
6. Matplotlib 绘图库
matplotlib是Python中最重要的绘图库,它可以生成出版质量级别的图形,包括折线图、散点图、直方图等。
- 具体信息可以参考RUNOOB的matplotlib板块:https://www.runoob.com/w3cnote/matplotlib-tutorial.html
- 英语不错的同学,可以直接访问matplotlib项目页:http://matplotlib.org
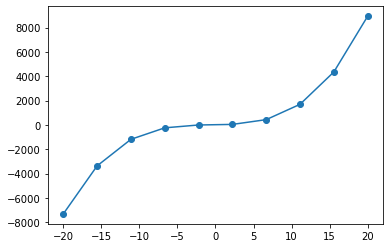
以下代码用于生成一个表达式为:y=x3+2x2+6x+5 的曲线图。
# 通过inline指令,实现在Jupyter中的实时绘图功能
%matplotlib inline
# 1. 使用import关键字引入matplotlib库,为了简便使用缩写 “plt”来表示matplotlib库。
import matplotlib.pyplot as plt
import numpy as np
# 使用linspace()函数生成一个-20到20,元素个数为10的等差数列。
# 令数列中的值为 x, 并根据表达式计算对应的 y值。
x = np.linspace(-20, 20, 10)
y = x**3 + 2*x**2 + 6*x + 5
#使用plot()函数绘制出曲线图
plt.plot(x, y, marker = "o")
print("x={}".format(x))
print("y={}".format(y))
x=[-20. -15.55555556 -11.11111111 -6.66666667 -2.22222222
2.22222222 6.66666667 11.11111111 15.55555556 20. ]
y=[-7315. -3368.4430727 -1186.4951989 -242.40740741 -9.43072702
39.18381344 430.18518519 1690.3223594 4346.34430727 8925. ]
7. scikit-learn 机器学习库
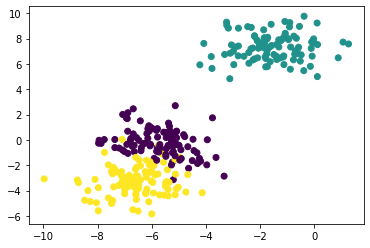
scikit-learn是Python中最重要的机器学习模块之一。它基于Scipy库,在不同的领域中已经发展出大量基于Scipy的工具包,它们被统一称为Scikits,其中最著名的一个分支就是scikit-learn。它包含众多的机器学习算法,主要分为六大类:分类、回归、聚类、数据降维、模型选择和数据预处理。下列给出一个使用scikit-learn进行分类的简单例子。在下例中会随机生成包含300个具有两种属性数据的数据集,然后利用简单的SVM分类器实现分类。
7.1 加载分类模型和可视化模块所需要的库文件
# 载入基础科学计算库 numpy
import numpy as np
# 载入可视化数据的模块 matplotlib
import matplotlib.pyplot as plt
# 从scikit-learn 库中载入预处理模块, 数据生成模块, 数据分割模块(划分为
# 训练集和测试集)和 支持向量机SVM的Support Vector Classifier分类模块
from sklearn.datasets import make_blobs
from sklearn import preprocessing
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
2. 生成数据集
# 生成300个具有2种属性的数据
X, y = make_blobs(n_samples=300, n_features=2, random_state=22)
3. 可视化数据并计算分类精度
#可视化数据
plt.scatter(X[:, 0], X[:, 1], c=y)
plt.show()
# 实现数据的正则化,可以有效提高分类精度
X = preprocessing.scale(X)
# 使用 train_test_split() 函数,将样本分割为 train训练集和 test测试集,
# 其中测试集数量为 30%
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
# 定义SVC的核函数
clf = SVC(gamma = "auto")
# 使用fit()函数对模型进行训练
clf.fit(X_train, y_train)
# 使用 test测试集输出测试准确率
print('{:.5f}'.format(clf.score(X_test, y_test)))
0.98889