【项目026】基于ResNet的十二生肖识别(演示版)返回首页
作者:欧新宇(Xinyu OU)
当前版本:Release v1.0
开发平台:Paddle 2.3.2
运行环境:Intel Core i7-7700K CPU 4.2GHz, nVidia GeForce GTX 1080 Ti
本教案所涉及的数据集仅用于教学和交流使用,请勿用作商用。
最后更新:2022年10月9日
【项目说明】
本项目使用ResNet18模型进行训练,基本流程与AlexNet模型一致,且训练周期设置为10,并未进行过多收敛性探索,仅作探索使用。有兴趣的同学可以尝试使用更深的ResNet模型进行尝试。
【实验目的】
- 学会基于Paddle2.3+版实现卷积神经网络
- 学会自己设计AlexNet的类结构,并基于AlexNet模型进行训练、验证和推理
- 学会对模型进行整体准确率测评和单样本预测
- 学会使用logging函数进行日志输出和保存
- 熟练函数化编程方法
【代码逻辑结构图】
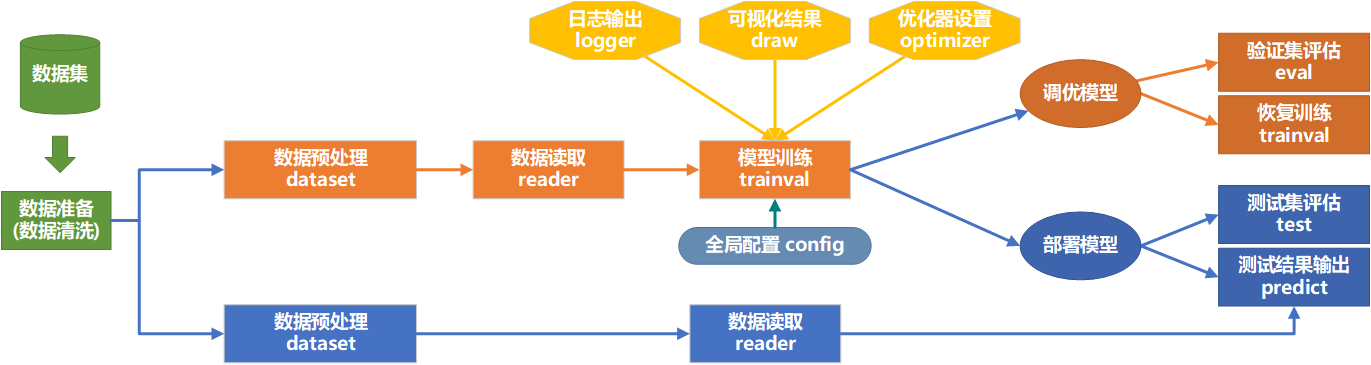
【实验一】 数据集准备
实验摘要: 对于模型训练的任务,需要数据预处理,将数据整理成为适合给模型训练使用的格式。数据集包含12个类别,其中训练集样本7199个, 验证集样本650个, 测试集样本660个, 共计8509个,其中包含9个损坏的文件。
实验目的:
- 学会观察数据集的文件结构,考虑是否需要进行数据清理,包括删除无法读取的样本、处理冗长不合规范的文件命名等
- 能够按照训练集、验证集、训练验证集、测试集四种子集对数据集进行划分,并生成数据列表
- 能够根据数据划分结果和样本的类别,生成包含数据集摘要信息下数据集信息文件
dataset_info.json - 能简单展示和预览数据的基本信息,包括数据量,规模,数据类型和位深度等
1.0 数据清洗
本项目的数据清晰主要解决部分数据损坏的问题,因此采取尝试读读取的方法进行测试,若无法正确读取则判定为损坏图像。
注意:一般来说,数据清晰只需要执行一次,且数据清洗时间较长。
# ##################################################################################
# # 数据清洗
# # 作者: Xinyu Ou (http://ouxinyu.cn)
# # 数据集名称:十二生肖数据集Zodiac
# # 本程序功能:
# # 对图像坏样本,进行索引,并保存到bad.txt中,扫描文件夹时,自动跳过文件夹'.DS_Store'和'.ipynb_checkpoints'
# ###################################################################################
# import os
# import cv2
# import codecs
# # 本地运行时,需要修改数据集的名称和绝对路径,注意和文件夹名称一致
# dataset_name = 'Zodiac'
# dataset_path = 'D:\\Workspace\\ExpDatasets\\'
# dataset_root_path = os.path.join(dataset_path, dataset_name)
# excluded_folder = ['.DS_Store', '.ipynb_checkpoints'] # 被排除的文件夹
# class_prefix = ['train', 'valid', 'test']
# num_bad = 0
# num_good = 0
# num_folder = 0
# # 检测坏文件列表是否存在,如果存在则先删除。
# bad_list = os.path.join(dataset_root_path, 'bad.txt')
# if os.path.exists(bad_list):
# os.remove(bad_list)
# # 执行数据清洗
# with codecs.open(bad_list, 'a', 'utf-8') as f_bad:
# for prefix in class_prefix:
# class_name_list = os.listdir(os.path.join(dataset_root_path, prefix))
# for class_name in class_name_list:
# if class_name not in excluded_folder: # 跳过排除文件夹
# images = os.listdir(os.path.join(dataset_root_path, prefix, class_name))
# for image in images:
# if image not in excluded_folder: # 跳过排除文件夹
# img_path = os.path.join(dataset_root_path, prefix, class_name, image)
# try: # 通过尝试读取并显示图像维度来判断样本是否损坏
# img = cv2.imread(img_path, 1)
# x = img.shape
# num_good += 1
# pass
# except:
# bad_file = os.path.join(prefix, class_name, image)
# f_bad.write("{}\n".format(bad_file))
# num_bad += 1
# num_folder += 1
# print('\r 当前清洗进度:{}/{}'.format(num_folder, 3*len(class_name_list)), end='')
# print('数据集清洗完成, 损坏文件{}个, 正常文件{}.'.format(num_bad, num_good))
1.1 生产图像列表及类别标签
##################################################################################
# 数据集预处理
# 作者: Xinyu Ou (http://ouxinyu.cn)
# 数据集名称:十二生肖数据集Zodiac
# 数据集简介: 数据集包含12个类别,其中训练集样本7199个, 验证集样本650个, 测试集样本660个, 共计8509个,其中包含9个损坏的文件。
# 本程序功能:
# 1. 将数据集由官方进行划分,大体上训练集、验证集、测试集的比例为: 85:7.5:7.5
# 2. 代码将生成4个列表文件:训练集列表train.txt, 验证集列表val.txt, 测试集列表test.txt, 训练验证集trainval.txt
# 3. 数据集基本信息:数据集的基本信息使用json格式进行输出,包括数据库名称、数据样本的数量、类别数以及类别标签。
###################################################################################
import os
import cv2
import json
import codecs
# 初始化参数
num_trainval = 0
num_train = 0
num_val = 0
num_test = 0
class_dim = 0
dataset_info = {
'dataset_name': '',
'num_trainval': -1,
'num_train': -1,
'num_val': -1,
'num_test': -1,
'num_bad': -1,
'class_dim': -1,
'label_dict': {}
}
# 本地运行时,需要修改数据集的名称和绝对路径,注意和文件夹名称一致
dataset_name = 'Zodiac'
dataset_path = 'D:\\Workspace\\ExpDatasets\\'
dataset_root_path = os.path.join(dataset_path, dataset_name)
class_prefix = ['train', 'valid', 'test']
excluded_folder = ['.DS_Store', '.ipynb_checkpoints'] # 被排除的文件或文件夹
# 定义生成文件的路径
# data_path = os.path.join(dataset_root_path,=) # 该数据的样本分别保存在train,valid和test文件夹中,因此不需要统一指定路径
trainval_list = os.path.join(dataset_root_path, 'trainval.txt')
train_list = os.path.join(dataset_root_path, 'train.txt')
val_list = os.path.join(dataset_root_path, 'val.txt')
test_list = os.path.join(dataset_root_path, 'test.txt')
dataset_info_list = os.path.join(dataset_root_path, 'dataset_info.json')
# 读取数据清洗获得的坏样本列表
bad_list = os.path.join(dataset_root_path, 'bad.txt')
with codecs.open(bad_list, 'r', 'utf-8') as f_bad:
bad_file = f_bad.read().splitlines()
num_bad = len(bad_file)
# 检测数据集列表是否存在,如果存在则先删除。其中测试集列表是一次写入,因此可以通过'w'参数进行覆盖写入,而不用进行手动删除。
if os.path.exists(trainval_list):
os.remove(trainval_list)
if os.path.exists(train_list):
os.remove(train_list)
if os.path.exists(val_list):
os.remove(val_list)
if os.path.exists(test_list):
os.remove(test_list)
# 获取类别的名称,因为train,valid,test的类别是相同的,因此只需要从train中获取即可
class_name_list = os.listdir(os.path.join(dataset_root_path, 'train'))
# 分别从train,valid和test文件夹中去索引图像,并写入列表文件中
with codecs.open(trainval_list, 'a', 'utf-8') as f_trainval:
with codecs.open(train_list, 'a', 'utf-8') as f_train:
with codecs.open(val_list, 'a', 'utf-8') as f_val:
with codecs.open(test_list, 'a', 'utf-8') as f_test:
for prefix in class_prefix:
class_name_dir = os.listdir(os.path.join(dataset_root_path, prefix))
for i in range(len(class_name_list)):
class_name = class_name_list[i]
dataset_info['label_dict'][i] = class_name_list[i]
images = os.listdir(os.path.join(dataset_root_path, prefix, class_name))
for image in images:
if image not in excluded_folder and os.path.join(prefix, class_name, image) not in bad_file: # 判断文件是否是坏样本
if prefix == 'train':
f_train.write("{}\t{}\n".format(os.path.join(dataset_root_path, prefix, class_name, image), str(i)))
f_trainval.write("{}\t{}\n".format(os.path.join(dataset_root_path, prefix, class_name, image), str(i)))
num_train += 1
num_trainval += 1
elif prefix == 'valid':
f_val.write("{}\t{}\n".format(os.path.join(dataset_root_path, prefix, class_name, image), str(i)))
f_trainval.write("{}\t{}\n".format(os.path.join(dataset_root_path, prefix, class_name, image), str(i)))
num_val += 1
num_trainval += 1
elif prefix == 'test':
f_test.write("{}\t{}\n".format(os.path.join(dataset_root_path, prefix, class_name, image), str(i)))
num_test += 1
# 将数据集信息保存到json文件中供训练时使用
dataset_info['dataset_name'] = dataset_name
dataset_info['num_trainval'] = num_trainval
dataset_info['num_train'] = num_train
dataset_info['num_val'] = num_val
dataset_info['num_test'] = num_test
dataset_info['num_bad'] = num_bad
dataset_info['class_dim'] = len(class_name_list)
# 输出数据集信息json和统计情况
with codecs.open(dataset_info_list, 'w', encoding='utf-8') as f_dataset_info:
json.dump(dataset_info, f_dataset_info, ensure_ascii=False, indent=4, separators=(',', ':')) # 格式化字典格式的参数列表
print("图像列表已生成, 其中训练验证集样本{},训练集样本{}个, 验证集样本{}个, 测试集样本{}个, 共计{}个; 损坏文件{}个。".format(num_trainval, num_train, num_val, num_test, num_train+num_val+num_test, num_bad))
display(dataset_info) # 展示数据集列表信息
图像列表已生成, 其中训练验证集样本7840,训练集样本7190个, 验证集样本650个, 测试集样本660个, 共计8500个; 损坏文件9个。
{'dataset_name': 'Zodiac',
'num_trainval': 7840,
'num_train': 7190,
'num_val': 650,
'num_test': 660,
'num_bad': 9,
'class_dim': 12,
'label_dict': {0: 'dog',
1: 'dragon',
2: 'goat',
3: 'horse',
4: 'monkey',
5: 'ox',
6: 'pig',
7: 'rabbit',
8: 'ratt',
9: 'rooster',
10: 'snake',
11: 'tiger'}}
【实验二】 全局参数设置及数据基本处理
实验摘要: 十二生肖识别是一个多分类问题,我们通过卷积神经网络来完成。这部分通过PaddlePaddle手动构造一个Alexnet卷积神经的网络来实现识别功能。本实验主要实现训练前的一些准备工作,包括:全局参数定义,数据集载入,数据预处理,可视化函数定义,日志输出函数定义。
实验目的:
- 学会使用配置文件定义全局参数
- 学会设置和载入数据集
- 学会对输入样本进行基本的预处理
- 学会定义可视化函数,可视化训练过程,同时输出可视化结果图和数据
- 学会使用logging定义日志输出函数,用于训练过程中的日志保持
1.1 全局参数设置
#################导入依赖库##################################################
import os
import sys
import json
import codecs
import numpy as np
import time # 载入time时间库,用于计算训练时间
import paddle
import matplotlib.pyplot as plt # 载入python的第三方图像处理库
from pprint import pprint
sys.path.append(r'D:\WorkSpace\DeepLearning\WebsiteV2\Notebook\Projects')
from utils.getSystemInfo import getSystemInfo
################全局参数配置###################################################
#### 1. 训练超参数定义
train_parameters = {
# Q1. 完成下列未完成的参数的配置
# [Your codes 1]
'project_name': 'Project026ResNetZodiac',
'dataset_name': 'Zodiac',
'architecture': 'ResNet',
'training_data': 'train',
'starting_time': time.strftime("%Y%m%d%H%M", time.localtime()), # 全局启动时间
'input_size': [3, 227, 227], # 输入样本的尺度
'mean_value': [0.485, 0.456, 0.406], # Imagenet均值
'std_value': [0.229, 0.224, 0.225], # Imagenet标准差
'num_trainval': -1,
'num_train': -1,
'num_val': -1,
'num_test': -1,
'class_dim': -1,
'label_dict': {},
'total_epoch': 10, # 总迭代次数, 代码调试好后考虑
'batch_size': 64, # 设置每个批次的数据大小,同时对训练提供器和测试
'log_interval': 10, # 设置训练过程中,每隔多少个batch显示一次
'eval_interval': 1, # 设置每个多少个epoch测试一次
'dataset_root_path': 'D:\\Workspace\\ExpDatasets\\',
'result_root_path': 'D:\\Workspace\\ExpResults\\',
'deployment_root_path': 'D:\\Workspace\\ExpDeployments\\',
'useGPU': True, # True | Flase
'learning_strategy': { # 学习率和优化器相关参数
'optimizer_strategy': 'Momentum', # 优化器:Momentum, RMS, SGD, Adam
'learning_rate_strategy': 'CosineAnnealingDecay', # 学习率策略: 固定fixed, 分段衰减PiecewiseDecay, 余弦退火CosineAnnealingDecay, 指数ExponentialDecay, 多项式PolynomialDecay
'learning_rate': 0.001, # 固定学习率|起始学习率
'momentum': 0.9, # 动量
'Piecewise_boundaries': [60, 80, 90], # 分段衰减:变换边界,每当运行到epoch时调整一次
'Piecewise_values': [0.01, 0.001, 0.0001, 0.00001], # 分段衰减:步进学习率,每次调节的具体值
'Exponential_gamma': 0.9, # 指数衰减:衰减指数
'Polynomial_decay_steps': 10, # 多项式衰减:衰减周期,每个多少个epoch衰减一次
'verbose': True # 是否显示学习率变化日志 True|Fasle
},
'augmentation_strategy': {
'withAugmentation': True, # 数据扩展相关参数
'augmentation_prob': 0.5, # 设置数据增广的概率
'rotate_angle': 15, # 随机旋转的角度
'Hflip_prob': 0.5, # 随机翻转的概率
'brightness': 0.4,
'contrast': 0.4,
'saturation': 0.4,
'hue': 0.4,
},
}
#### 2. 设置简化参数名
args = train_parameters
argsAS = args['augmentation_strategy']
argsLS = train_parameters['learning_strategy']
model_name = args['dataset_name'] + '_' + args['architecture']
#### 3. 定义设备工作模式 [GPU|CPU]
# 定义使用CPU还是GPU,使用CPU时use_cuda = False,使用GPU时use_cuda = True
def init_device(useGPU=args['useGPU']):
paddle.device.set_device('gpu:0') if useGPU else paddle.device.set_device('cpu')
init_device()
#### 4.定义各种路径:模型、训练、日志结果图
# 4.1 数据集路径
dataset_root_path = os.path.join(args['dataset_root_path'], args['dataset_name'])
json_dataset_info = os.path.join(dataset_root_path, 'dataset_info.json')
# 4.2 训练过程涉及的相关路径
result_root_path = os.path.join(args['result_root_path'], args['project_name'])
checkpoint_models_path = os.path.join(result_root_path, 'checkpoint_models') # 迭代训练模型保存路径
final_figures_path = os.path.join(result_root_path, 'final_figures') # 训练过程曲线图
final_models_path = os.path.join(result_root_path, 'final_models') # 最终用于部署和推理的模型
logs_path = os.path.join(result_root_path, 'logs') # 训练过程日志
# 4.3 checkpoint_ 路径用于定义恢复训练所用的模型保存
# checkpoint_path = os.path.join(result_path, model_name + '_final')
# checkpoint_model = os.path.join(args['result_root_path'], model_name + '_' + args['checkpoint_time'], 'checkpoint_models', args['checkpoint_model'])
# 4.4 验证和测试时的相关路径(文件)
deployment_root_path = os.path.join(args['deployment_root_path'], args['project_name'])
deployment_checkpoint_path = os.path.join(deployment_root_path, 'checkpoint_models', model_name + '_final')
deployment_final_models_path = os.path.join(deployment_root_path, 'final_models', model_name + '_final')
deployment_final_figures_path = os.path.join(deployment_root_path, 'final_figures')
deployment_logs_path = os.path.join(deployment_root_path, 'logs')
# 4.5 初始化结果目录
def init_result_path():
if not os.path.exists(final_models_path):
os.makedirs(final_models_path)
if not os.path.exists(final_figures_path):
os.makedirs(final_figures_path)
if not os.path.exists(logs_path):
os.makedirs(logs_path)
if not os.path.exists(checkpoint_models_path):
os.makedirs(checkpoint_models_path)
init_result_path()
#### 5. 初始化参数
def init_train_parameters():
dataset_info = json.loads(open(json_dataset_info, 'r', encoding='utf-8').read())
train_parameters['num_trainval'] = dataset_info['num_trainval']
train_parameters['num_train'] = dataset_info['num_train']
train_parameters['num_val'] = dataset_info['num_val']
train_parameters['num_test'] = dataset_info['num_test']
train_parameters['class_dim'] = dataset_info['class_dim']
train_parameters['label_dict'] = dataset_info['label_dict']
init_train_parameters()
##############################################################################################
# 输出训练参数 train_parameters
# if __name__ == '__main__':
# pprint(args)
2.2 数据集定义及数据预处理
2.2.1 数据集定义
import os
import sys
import cv2
import numpy as np
import paddle
import paddle.vision.transforms as T
from paddle.io import DataLoader
input_size = (args['input_size'][1], args['input_size'][2])
# 1. 数据集的定义
class ZodiacDataset(paddle.io.Dataset):
def __init__(self, dataset_root_path, mode='test', withAugmentation=argsAS['withAugmentation']):
assert mode in ['train', 'val', 'test', 'trainval']
self.data = []
self.withAugmentation = withAugmentation
with open(os.path.join(dataset_root_path, mode+'.txt')) as f:
for line in f.readlines():
info = line.strip().split('\t')
image_path = os.path.join(dataset_root_path, 'Data', info[0].strip())
if len(info) == 2:
self.data.append([image_path, info[1].strip()])
elif len(info) == 1:
self.data.append([image_path, -1])
prob = np.random.random()
if mode in ['train', 'trainval'] and prob >= argsAS['augmentation_prob']:
self.transforms = T.Compose([
T.RandomResizedCrop(input_size),
T.RandomHorizontalFlip(argsAS['Hflip_prob']),
T.RandomRotation(argsAS['rotate_angle']),
T.ColorJitter(brightness=argsAS['brightness'], contrast=argsAS['contrast'], saturation=argsAS['saturation'], hue=argsAS['hue']),
T.ToTensor(),
T.Normalize(mean=args['mean_value'], std=args['std_value'])
])
else: # mode in ['val', 'test'] or mode in ['train', 'trainval'] and prob < argsAS['augmentation_prob']:
self.transforms = T.Compose([
T.Resize(input_size),
T.ToTensor(),
T.Normalize(mean=args['mean_value'], std=args['std_value'])
])
# 根据索引获取单个样本
def __getitem__(self, index):
image_path, label = self.data[index]
image = cv2.imread(image_path, 1) # 使用cv2进行数据读取可以强制将的图像转化为彩色模式,其中0为灰度模式,1为彩色模式
if self.withAugmentation == True:
image = self.transforms(image)
label = np.array(label, dtype='int64')
return image, label
# 获取样本总数
def __len__(self):
return len(self.data)
###############################################################
# 测试输入数据类:分别输出进行预处理和未进行预处理的数据形态和例图
if __name__ == "__main__":
import random
# 1. 载入数据
dataset_val_withoutAugmentation = ZodiacDataset(dataset_root_path, mode='val', withAugmentation=False)
id = random.randrange(0, len(dataset_val_withoutAugmentation))
img1 = dataset_val_withoutAugmentation[id][0]
dataset_val_withAugmentation = ZodiacDataset(dataset_root_path, mode='val')
img2 = dataset_val_withAugmentation[id][0]
print('第{}个验证集样本,\n 数据预处理前的形态为:{},\n 数据预处理后的数据形态为: {}'.format(id, img1.shape, img2.shape))
第645个验证集样本,
数据预处理前的形态为:(506, 900, 3),
2.2.2 定义数据迭代器
import os
import sys
from paddle.io import DataLoader
# 1. 从数据集库中获取数据
dataset_trainval = ZodiacDataset(dataset_root_path, mode='trainval')
dataset_train = ZodiacDataset(dataset_root_path, mode='train')
dataset_val = ZodiacDataset(dataset_root_path, mode='val')
dataset_test = ZodiacDataset(dataset_root_path, mode='test')
# 2. 创建读取器
trainval_reader = DataLoader(dataset_trainval, batch_size=args['batch_size'], shuffle=True, drop_last=True)
train_reader = DataLoader(dataset_train, batch_size=args['batch_size'], shuffle=True, drop_last=True)
val_reader = DataLoader(dataset_val, batch_size=args['batch_size'], shuffle=False, drop_last=False)
test_reader = DataLoader(dataset_test, batch_size=args['batch_size'], shuffle=False, drop_last=False)
######################################################################################
# 测试读取器
if __name__ == "__main__":
for i, (image, label) in enumerate(val_reader()):
if i == 2:
break
print('验证集batch_{}的图像形态:{}, 标签形态:{}'.format(i, image.shape, label.shape))
验证集batch_0的图像形态:[64, 3, 227, 227], 标签形态:[64]
验证集batch_1的图像形态:[64, 3, 227, 227], 标签形态:[64]
2.3 定义过程可视化函数
sys.path.append(r'D:\WorkSpace\DeepLearning\WebsiteV2\Notebook\Projects') # 定义模块保存位置
from utils.getVisualization import draw_process # 导入日志模块
######################################################################################
# 测试可视化函数
if __name__ == '__main__':
try:
train_log = np.load(os.path.join(final_figures_path, 'train.npy'))
print('训练数据可视化结果:')
draw_process('Training', 'loss', 'accuracy', iters=train_log[0], losses=train_log[1], accuracies=train_log[2], final_figures_path=final_figures_path, figurename='train', isShow=True)
except:
print('以下图例为测试数据。')
draw_process('Training', 'loss', 'accuracy', figurename='default', isShow=True)
以下图例为测试数据。
2.4 定义日志输出函数
sys.path.append(r'D:\WorkSpace\DeepLearning\WebsiteV2\Notebook\Projects')
from utils.getLogging import init_log_config
logger = init_log_config(logs_path=logs_path, model_name=model_name)
######################################################################################
# 测试日志输出
if __name__ == '__main__':
system_info = json.dumps(getSystemInfo(), indent=4, ensure_ascii=False, sort_keys=False, separators=(',', ':'))
logger.info('系统基本信息:')
logger.info(system_info)
2022-10-10 09:32:53,625 - INFO: 系统基本信息:
2022-10-10 09:32:53,626 - INFO: {
"操作系统":"Windows-10-10.0.22000-SP0",
"CPU":"Intel(R) Core(TM) i7-9700 CPU @ 3.00GHz",
"内存":"8.31G/15.88G (52.30%)",
"GPU":"b'GeForce RTX 2080' 1.33G/8.00G (0.17%)",
"CUDA":"7.6.5",
"cuDNN":"7.6.5",
"Paddle":"2.3.2"
}
【实验三】 模型训练与评估
实验摘要: 十二生肖分类是一个多分类问题,我们通过卷积神经网络来完成。这部分通过PaddlePaddle手动构造一个Alexnet卷积神经的网络来实现识别功能,最后一层采用Softmax激活函数完成分类任务。
实验目的:
- 掌握卷积神经网络的构建和基本原理
- 深刻理解训练集、验证集、训练验证集及测试集在模型训练中的作用
- 学会按照网络拓扑结构图定义神经网络类 (Paddle 2.0+)
- 学会在线测试和离线测试两种测试方法
- 学会定义多种优化方法,并在全局参数中进行定义选择
3.1 配置网络
3.1.1 网络拓扑结构图
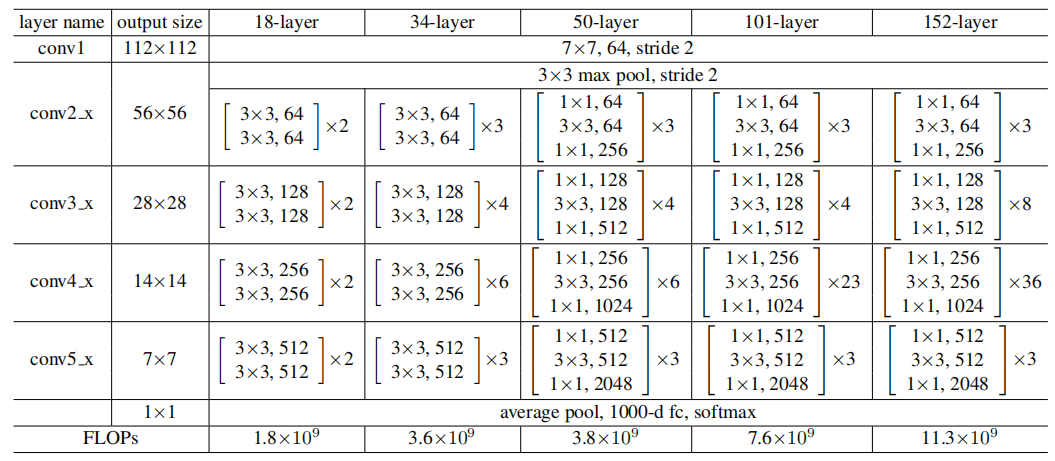
需要注意的是,在Alexnet的原版论文中,尺度会被Crop为227×227×3,但在后面很多框架的实现中,该尺度被统一到了224×224×3
3.1.2 网络参数配置表
| Layer | Input | Kernels_num | Kernels_size | Stride | Padding | PoolingType | Output | Parameters |
|---|---|---|---|---|---|---|---|---|
| Input | 3×227×227 | |||||||
| Conv1 | 3×227×227 | 96 | 3×11×11 | 4 | 0 | 96×55×55 | (3×11×11+1)×96=34944 | |
| Pool1 | 96×55×55 | 96 | 96×3×3 | 2 | 0 | max | 96×27×27 | 0 |
| Conv2 | 96×27×27 | 256 | 96×5×5 | 1 | 2 | 256×27×27 | (96×5×5+1)×256=614656 | |
| Pool2 | 256×27×27 | 256 | 256×3×3 | 2 | 0 | max | 256×13×13 | 0 |
| Conv3 | 256×13×13 | 384 | 256×3×3 | 1 | 1 | 384×13×13 | (256×3×3+1)×384=885120 | |
| Conv4 | 384×13×13 | 384 | 384×3×3 | 1 | 1 | 384×13×13 | (384×3×3+1)×384=1327488 | |
| Conv5 | 384×13×13 | 256 | 384×3×3 | 1 | 1 | 256×13×13 | (384×3×3+1)×256=884992 | |
| Pool5 | 256×13×13 | 256 | 256×3×3 | 2 | 0 | max | 256×6×6 | 0 |
| FC6 | (256×6×6)×1 | 4096×1 | (9216+1)×4096=37752832 | |||||
| FC7 | 4096×1 | 4096×1 | (4096+1)×4096=16781312 | |||||
| FC8 | 4096×1 | 1000×1 | (4096+1)×1000=4097000 | |||||
| Output | 1000×1 | |||||||
| Total = 62378344 | ||||||||
其中卷积层参数:3747200,占总参数的6%。
from numpy import pad
from paddle.vision.models import resnet18, resnet50
network = paddle.vision.models.resnet18(num_classes=12)
paddle.summary(network, (1,3,227,227))
-------------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===============================================================================
Conv2D-1 [[1, 3, 227, 227]] [1, 64, 114, 114] 9,408
BatchNorm2D-1 [[1, 64, 114, 114]] [1, 64, 114, 114] 256
ReLU-1 [[1, 64, 114, 114]] [1, 64, 114, 114] 0
MaxPool2D-1 [[1, 64, 114, 114]] [1, 64, 57, 57] 0
Conv2D-2 [[1, 64, 57, 57]] [1, 64, 57, 57] 36,864
BatchNorm2D-2 [[1, 64, 57, 57]] [1, 64, 57, 57] 256
ReLU-2 [[1, 64, 57, 57]] [1, 64, 57, 57] 0
Conv2D-3 [[1, 64, 57, 57]] [1, 64, 57, 57] 36,864
BatchNorm2D-3 [[1, 64, 57, 57]] [1, 64, 57, 57] 256
BasicBlock-1 [[1, 64, 57, 57]] [1, 64, 57, 57] 0
Conv2D-4 [[1, 64, 57, 57]] [1, 64, 57, 57] 36,864
BatchNorm2D-4 [[1, 64, 57, 57]] [1, 64, 57, 57] 256
ReLU-3 [[1, 64, 57, 57]] [1, 64, 57, 57] 0
Conv2D-5 [[1, 64, 57, 57]] [1, 64, 57, 57] 36,864
BatchNorm2D-5 [[1, 64, 57, 57]] [1, 64, 57, 57] 256
BasicBlock-2 [[1, 64, 57, 57]] [1, 64, 57, 57] 0
Conv2D-7 [[1, 64, 57, 57]] [1, 128, 29, 29] 73,728
BatchNorm2D-7 [[1, 128, 29, 29]] [1, 128, 29, 29] 512
ReLU-4 [[1, 128, 29, 29]] [1, 128, 29, 29] 0
Conv2D-8 [[1, 128, 29, 29]] [1, 128, 29, 29] 147,456
BatchNorm2D-8 [[1, 128, 29, 29]] [1, 128, 29, 29] 512
Conv2D-6 [[1, 64, 57, 57]] [1, 128, 29, 29] 8,192
BatchNorm2D-6 [[1, 128, 29, 29]] [1, 128, 29, 29] 512
BasicBlock-3 [[1, 64, 57, 57]] [1, 128, 29, 29] 0
Conv2D-9 [[1, 128, 29, 29]] [1, 128, 29, 29] 147,456
BatchNorm2D-9 [[1, 128, 29, 29]] [1, 128, 29, 29] 512
ReLU-5 [[1, 128, 29, 29]] [1, 128, 29, 29] 0
Conv2D-10 [[1, 128, 29, 29]] [1, 128, 29, 29] 147,456
BatchNorm2D-10 [[1, 128, 29, 29]] [1, 128, 29, 29] 512
BasicBlock-4 [[1, 128, 29, 29]] [1, 128, 29, 29] 0
Conv2D-12 [[1, 128, 29, 29]] [1, 256, 15, 15] 294,912
BatchNorm2D-12 [[1, 256, 15, 15]] [1, 256, 15, 15] 1,024
ReLU-6 [[1, 256, 15, 15]] [1, 256, 15, 15] 0
Conv2D-13 [[1, 256, 15, 15]] [1, 256, 15, 15] 589,824
BatchNorm2D-13 [[1, 256, 15, 15]] [1, 256, 15, 15] 1,024
Conv2D-11 [[1, 128, 29, 29]] [1, 256, 15, 15] 32,768
BatchNorm2D-11 [[1, 256, 15, 15]] [1, 256, 15, 15] 1,024
BasicBlock-5 [[1, 128, 29, 29]] [1, 256, 15, 15] 0
Conv2D-14 [[1, 256, 15, 15]] [1, 256, 15, 15] 589,824
BatchNorm2D-14 [[1, 256, 15, 15]] [1, 256, 15, 15] 1,024
ReLU-7 [[1, 256, 15, 15]] [1, 256, 15, 15] 0
Conv2D-15 [[1, 256, 15, 15]] [1, 256, 15, 15] 589,824
BatchNorm2D-15 [[1, 256, 15, 15]] [1, 256, 15, 15] 1,024
BasicBlock-6 [[1, 256, 15, 15]] [1, 256, 15, 15] 0
Conv2D-17 [[1, 256, 15, 15]] [1, 512, 8, 8] 1,179,648
BatchNorm2D-17 [[1, 512, 8, 8]] [1, 512, 8, 8] 2,048
ReLU-8 [[1, 512, 8, 8]] [1, 512, 8, 8] 0
Conv2D-18 [[1, 512, 8, 8]] [1, 512, 8, 8] 2,359,296
BatchNorm2D-18 [[1, 512, 8, 8]] [1, 512, 8, 8] 2,048
Conv2D-16 [[1, 256, 15, 15]] [1, 512, 8, 8] 131,072
BatchNorm2D-16 [[1, 512, 8, 8]] [1, 512, 8, 8] 2,048
BasicBlock-7 [[1, 256, 15, 15]] [1, 512, 8, 8] 0
Conv2D-19 [[1, 512, 8, 8]] [1, 512, 8, 8] 2,359,296
BatchNorm2D-19 [[1, 512, 8, 8]] [1, 512, 8, 8] 2,048
ReLU-9 [[1, 512, 8, 8]] [1, 512, 8, 8] 0
Conv2D-20 [[1, 512, 8, 8]] [1, 512, 8, 8] 2,359,296
BatchNorm2D-20 [[1, 512, 8, 8]] [1, 512, 8, 8] 2,048
BasicBlock-8 [[1, 512, 8, 8]] [1, 512, 8, 8] 0
AdaptiveAvgPool2D-1 [[1, 512, 8, 8]] [1, 512, 1, 1] 0
Linear-1 [[1, 512]] [1, 12] 6,156
===============================================================================
Total params: 11,192,268
Trainable params: 11,173,068
Non-trainable params: 19,200
-------------------------------------------------------------------------------
Input size (MB): 0.59
Forward/backward pass size (MB): 60.82
Params size (MB): 42.70
Estimated Total Size (MB): 104.10
-------------------------------------------------------------------------------
{'total_params': 11192268, 'trainable_params': 11173068}
3.2 定义优化方法
import paddle
sys.path.append(r'D:\WorkSpace\DeepLearning\WebsiteV2\Notebook\Projects')
from utils.getOptimizer import learning_rate_setting, optimizer_setting
# 5. 学习率输出测试
if __name__ == '__main__':
# print('当前学习率策略为: {} + {}'.format(argsLS['optimizer_strategy'], argsLS['learning_rate_strategy']))
linear = paddle.nn.Linear(10, 10)
lr = learning_rate_setting(args=args, argsO=argsLS)
optimizer = optimizer_setting(linear, lr, argsO=argsLS)
if argsLS['optimizer_strategy'] == 'fixed':
print('learning = {}'.format(argsLS['learning_rate']))
else:
for epoch in range(10):
for batch_id in range(10):
x = paddle.uniform([10, 10])
out = linear(x)
loss = paddle.mean(out)
loss.backward()
optimizer.step()
optimizer.clear_gradients()
# lr.step() # 按照batch进行学习率更新
lr.step() # 按照epoch进行学习率更新
当前学习率策略为: Momentum + CosineAnnealingDecay
Epoch 0: CosineAnnealingDecay set learning rate to 0.001.
Epoch 1: CosineAnnealingDecay set learning rate to 0.0009999921320324326.
Epoch 2: CosineAnnealingDecay set learning rate to 0.0009999685283773503.
Epoch 3: CosineAnnealingDecay set learning rate to 0.000999929189777604.
Epoch 4: CosineAnnealingDecay set learning rate to 0.0009998741174712532.
Epoch 5: CosineAnnealingDecay set learning rate to 0.0009998033131915264.
Epoch 6: CosineAnnealingDecay set learning rate to 0.0009997167791667666.
Epoch 7: CosineAnnealingDecay set learning rate to 0.0009996145181203613.
Epoch 8: CosineAnnealingDecay set learning rate to 0.0009994965332706571.
Epoch 9: CosineAnnealingDecay set learning rate to 0.0009993628283308578.
Epoch 10: CosineAnnealingDecay set learning rate to 0.000999213407508908.
3.3 定义验证函数
# 载入项目文件夹
import sys
import numpy as np
import paddle
import paddle.nn.functional as F
from paddle.static import InputSpec
def eval(model, data_reader, verbose=0):
accuracies_top1 = []
accuracies_top5 = []
losses = []
n_total = 0
for batch_id, (image, label) in enumerate(data_reader):
n_batch = len(label)
n_total = n_total + n_batch
label = paddle.unsqueeze(label, axis=1)
loss, acc = model.eval_batch([image], [label])
losses.append(loss[0])
accuracies_top1.append(acc[0][0]*n_batch)
accuracies_top5.append(acc[0][1]*n_batch)
if verbose == 1:
print('\r Batch:{}/{}, acc_top1:[{:.5f}], acc_top5:[{:.5f}]'.format(batch_id+1, len(data_reader), acc[0][0], acc[0][1]), end='')
avg_loss = np.sum(losses)/n_total # loss 记录的是当前batch的累积值
avg_acc_top1 = np.sum(accuracies_top1)/n_total # metric 是当前batch的平均值
avg_acc_top5 = np.sum(accuracies_top5)/n_total
return avg_loss, avg_acc_top1, avg_acc_top5
##############################################################
if __name__ == '__main__':
try:
# 设置输入样本的维度
input_spec = InputSpec(shape=[None] + args['input_size'], dtype='float32', name='image')
label_spec = InputSpec(shape=[None, 1], dtype='int64', name='label')
# 载入模型
network = paddle.vision.models.resnet18(num_classes=12)
model = paddle.Model(network, input_spec, label_spec) # 模型实例化
model.load(deployment_checkpoint_path) # 载入调优模型的参数
model.prepare(loss=paddle.nn.CrossEntropyLoss(), # 设置loss
metrics=paddle.metric.Accuracy(topk=(1,5))) # 设置评价指标
# 执行评估函数,并输出验证集样本的损失和精度
print('开始评估...')
avg_loss, avg_acc_top1, avg_acc_top5 = eval(model, val_reader(), verbose=1)
print('\r [验证集] 损失: {:.5f}, top1精度:{:.5f}, top5精度为:{:.5f} \n'.format(avg_loss, avg_acc_top1, avg_acc_top5), end='')
avg_loss, avg_acc_top1, avg_acc_top5 = eval(model, test_reader(), verbose=1)
print('\r [测试集] 损失: {:.5f}, top1精度:{:.5f}, top5精度为:{:.5f}'.format(avg_loss, avg_acc_top1, avg_acc_top5), end='')
except:
print('数据不存在跳过测试')
开始评估...
[验证集] 损失: 0.02803, top1精度:0.43231, top5精度为:0.85077
[测试集] 损失: 0.03046, top1精度:0.40758, top5精度为:0.85152
3.4 模型训练及在线测试
import os
import time
import json
import paddle
from paddle.static import InputSpec
# 初始配置变量
total_epoch = train_parameters['total_epoch']
# 初始化绘图列表
all_train_iters = []
all_train_losses = []
all_train_accs_top1 = []
all_train_accs_top5 = []
all_test_losses = []
all_test_iters = []
all_test_accs_top1 = []
all_test_accs_top5 = []
def train(model):
# 初始化临时变量
num_batch = 0
best_result = 0
best_result_id = 0
elapsed = 0
for epoch in range(1, total_epoch+1):
for batch_id, (image, label) in enumerate(train_reader()):
num_batch += 1
label = paddle.unsqueeze(label, axis=1)
loss, acc = model.train_batch([image], [label])
if num_batch % train_parameters['log_interval'] == 0: # 每10个batch显示一次日志,适合大数据集
avg_loss = loss[0][0]
acc_top1 = acc[0][0]
acc_top5 = acc[0][1]
elapsed_step = time.perf_counter() - elapsed - start
elapsed = time.perf_counter() - start
logger.info('Epoch:{}/{}, batch:{}, train_loss:[{:.5f}], acc_top1:[{:.5f}], acc_top5:[{:.5f}]({:.2f}s)'
.format(epoch, total_epoch, num_batch, loss[0][0], acc[0][0], acc[0][1], elapsed_step))
# 记录训练过程,用于可视化训练过程中的loss和accuracy
all_train_iters.append(num_batch)
all_train_losses.append(avg_loss)
all_train_accs_top1.append(acc_top1)
all_train_accs_top5.append(acc_top5)
# 每隔一定周期进行一次测试
if epoch % train_parameters['eval_interval'] == 0 or epoch == total_epoch:
# 模型校验
avg_loss, avg_acc_top1, avg_acc_top5 = eval(model, val_reader())
logger.info('[validation] Epoch:{}/{}, val_loss:[{:.5f}], val_top1:[{:.5f}], val_top5:[{:.5f}]'.format(epoch, total_epoch, avg_loss, avg_acc_top1, avg_acc_top5))
# 记录测试过程,用于可视化训练过程中的loss和accuracy
all_test_iters.append(epoch)
all_test_losses.append(avg_loss)
all_test_accs_top1.append(avg_acc_top1)
all_test_accs_top5.append(avg_acc_top5)
# 将性能最好的模型保存为final模型
if avg_acc_top1 > best_result:
best_result = avg_acc_top1
best_result_id = epoch
# finetune model 用于调优和恢复训练
model.save(os.path.join(checkpoint_models_path, model_name + '_final'))
# inference model 用于部署和预测
model.save(os.path.join(final_models_path, model_name + '_final'), training=False)
logger.info('已保存当前测试模型(epoch={})为最优模型:{}_final'.format(best_result_id, model_name))
logger.info('最优top1测试精度:{:.5f} (epoch={})'.format(best_result, best_result_id))
logger.info('训练完成,最终性能accuracy={:.5f}(epoch={}), 总耗时{:.2f}s, 已将其保存为:{}_final'.format(best_result, best_result_id, time.perf_counter() - start, model_name))
#### 训练主函数 ########################################################3
if __name__ == '__main__':
system_info = json.dumps(getSystemInfo(), indent=4, ensure_ascii=False, sort_keys=False, separators=(',', ':'))
logger.info('系统基本信息')
logger.info(system_info)
# 将此次训练的超参数进行保存
data = json.dumps(train_parameters, indent=4, ensure_ascii=False, sort_keys=False, separators=(',', ':')) # 格式化字典格式的参数列表
logger.info(data)
# 启动训练过程
logger.info('训练参数保存完毕,使用{}模型, 训练{}数据, 训练集{}, 启动训练...'.format(train_parameters['architecture'],train_parameters['dataset_name'],train_parameters['training_data']))
logger.info('当前模型目录为:{}'.format(model_name + '_' + train_parameters['starting_time']))
# 设置输入样本的维度
input_spec = InputSpec(shape=[None] + train_parameters['input_size'], dtype='float32', name='image')
label_spec = InputSpec(shape=[None, 1], dtype='int64', name='label')
# 初始化AlexNet,并进行实例化
network = paddle.vision.models.resnet18(num_classes=12)
model = paddle.Model(network, input_spec, label_spec)
logger.info('模型参数信息:')
logger.info(model.summary()) # 是否显示神经网络的具体信息
# 设置学习率、优化器、损失函数和评价指标
lr = learning_rate_setting(args=args, argsO=argsLS)
optimizer = optimizer_setting(model, lr, argsO=argsLS)
model.prepare(optimizer,
paddle.nn.CrossEntropyLoss(),
paddle.metric.Accuracy(topk=(1,5)))
# 启动训练过程
start = time.perf_counter()
train(model)
logger.info('训练完毕,结果路径{}.'.format(result_root_path))
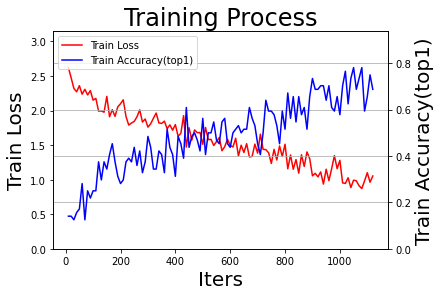
# 输出训练过程图
logger.info('Done.')
draw_process("Training Process", 'Train Loss', 'Train Accuracy(top1)', all_train_iters, all_train_losses, all_train_accs_top1, final_figures_path=final_figures_path, figurename='train', isShow=True)
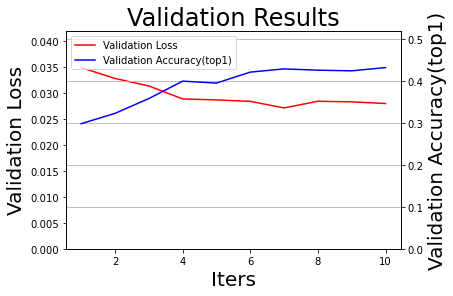
draw_process("Validation Results", 'Validation Loss', 'Validation Accuracy(top1)', all_test_iters, all_test_losses, all_test_accs_top1, final_figures_path=final_figures_path, figurename='val', isShow=True)
2022-10-10 09:32:56,631 - INFO: 系统基本信息
2022-10-10 09:32:56,632 - INFO: {
"操作系统":"Windows-10-10.0.22000-SP0",
"CPU":"Intel(R) Core(TM) i7-9700 CPU @ 3.00GHz",
"内存":"9.30G/15.88G (58.60%)",
"GPU":"b'GeForce RTX 2080' 1.83G/8.00G (0.23%)",
"CUDA":"7.6.5",
"cuDNN":"7.6.5",
"Paddle":"2.3.2"
}
2022-10-10 09:32:56,633 - INFO: {
"project_name":"Project012AlexNetZodiac",
"dataset_name":"Zodiac",
"architecture":"resnet18",
"training_data":"train",
"starting_time":"202210100932",
"input_size":[
3,
227,
227
],
"mean_value":[
0.485,
0.456,
0.406
],
"std_value":[
0.229,
0.224,
0.225
],
"num_trainval":7840,
"num_train":7190,
"num_val":650,
"num_test":660,
"class_dim":12,
"label_dict":{
"0":"dog",
"1":"dragon",
"2":"goat",
"3":"horse",
"4":"monkey",
"5":"ox",
"6":"pig",
"7":"rabbit",
"8":"ratt",
"9":"rooster",
"10":"snake",
"11":"tiger"
},
"total_epoch":10,
"batch_size":64,
"log_interval":10,
"eval_interval":1,
"dataset_root_path":"D:\\Workspace\\ExpDatasets\\",
"result_root_path":"D:\\Workspace\\ExpResults\\",
"deployment_root_path":"D:\\Workspace\\ExpDeployments\\",
"useGPU":true,
"learning_strategy":{
"optimizer_strategy":"Momentum",
"learning_rate_strategy":"CosineAnnealingDecay",
"learning_rate":0.001,
"momentum":0.9,
"Piecewise_boundaries":[
60,
80,
90
],
"Piecewise_values":[
0.01,
0.001,
0.0001,
1e-05
],
"Exponential_gamma":0.9,
"Polynomial_decay_steps":10,
"verbose":true
},
"augmentation_strategy":{
"withAugmentation":true,
"augmentation_prob":0.5,
"rotate_angle":15,
"Hflip_prob":0.5,
"brightness":0.4,
"contrast":0.4,
"saturation":0.4,
"hue":0.4
}
}
2022-10-10 09:32:56,634 - INFO: 训练参数保存完毕,使用resnet18模型, 训练Zodiac数据, 训练集train, 启动训练...
2022-10-10 09:32:56,635 - INFO: 当前模型目录为:Zodiac_resnet18_202210100932
2022-10-10 09:32:56,663 - INFO: 模型参数信息:
2022-10-10 09:32:56,678 - INFO: {'total_params': 11192268, 'trainable_params': 11173068}
-------------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===============================================================================
Conv2D-41 [[1, 3, 227, 227]] [1, 64, 114, 114] 9,408
BatchNorm2D-41 [[1, 64, 114, 114]] [1, 64, 114, 114] 256
ReLU-19 [[1, 64, 114, 114]] [1, 64, 114, 114] 0
MaxPool2D-3 [[1, 64, 114, 114]] [1, 64, 57, 57] 0
Conv2D-42 [[1, 64, 57, 57]] [1, 64, 57, 57] 36,864
BatchNorm2D-42 [[1, 64, 57, 57]] [1, 64, 57, 57] 256
ReLU-20 [[1, 64, 57, 57]] [1, 64, 57, 57] 0
Conv2D-43 [[1, 64, 57, 57]] [1, 64, 57, 57] 36,864
BatchNorm2D-43 [[1, 64, 57, 57]] [1, 64, 57, 57] 256
BasicBlock-17 [[1, 64, 57, 57]] [1, 64, 57, 57] 0
Conv2D-44 [[1, 64, 57, 57]] [1, 64, 57, 57] 36,864
BatchNorm2D-44 [[1, 64, 57, 57]] [1, 64, 57, 57] 256
ReLU-21 [[1, 64, 57, 57]] [1, 64, 57, 57] 0
Conv2D-45 [[1, 64, 57, 57]] [1, 64, 57, 57] 36,864
BatchNorm2D-45 [[1, 64, 57, 57]] [1, 64, 57, 57] 256
BasicBlock-18 [[1, 64, 57, 57]] [1, 64, 57, 57] 0
Conv2D-47 [[1, 64, 57, 57]] [1, 128, 29, 29] 73,728
BatchNorm2D-47 [[1, 128, 29, 29]] [1, 128, 29, 29] 512
ReLU-22 [[1, 128, 29, 29]] [1, 128, 29, 29] 0
Conv2D-48 [[1, 128, 29, 29]] [1, 128, 29, 29] 147,456
BatchNorm2D-48 [[1, 128, 29, 29]] [1, 128, 29, 29] 512
Conv2D-46 [[1, 64, 57, 57]] [1, 128, 29, 29] 8,192
BatchNorm2D-46 [[1, 128, 29, 29]] [1, 128, 29, 29] 512
BasicBlock-19 [[1, 64, 57, 57]] [1, 128, 29, 29] 0
Conv2D-49 [[1, 128, 29, 29]] [1, 128, 29, 29] 147,456
BatchNorm2D-49 [[1, 128, 29, 29]] [1, 128, 29, 29] 512
ReLU-23 [[1, 128, 29, 29]] [1, 128, 29, 29] 0
Conv2D-50 [[1, 128, 29, 29]] [1, 128, 29, 29] 147,456
BatchNorm2D-50 [[1, 128, 29, 29]] [1, 128, 29, 29] 512
BasicBlock-20 [[1, 128, 29, 29]] [1, 128, 29, 29] 0
Conv2D-52 [[1, 128, 29, 29]] [1, 256, 15, 15] 294,912
BatchNorm2D-52 [[1, 256, 15, 15]] [1, 256, 15, 15] 1,024
ReLU-24 [[1, 256, 15, 15]] [1, 256, 15, 15] 0
Conv2D-53 [[1, 256, 15, 15]] [1, 256, 15, 15] 589,824
BatchNorm2D-53 [[1, 256, 15, 15]] [1, 256, 15, 15] 1,024
Conv2D-51 [[1, 128, 29, 29]] [1, 256, 15, 15] 32,768
BatchNorm2D-51 [[1, 256, 15, 15]] [1, 256, 15, 15] 1,024
BasicBlock-21 [[1, 128, 29, 29]] [1, 256, 15, 15] 0
Conv2D-54 [[1, 256, 15, 15]] [1, 256, 15, 15] 589,824
BatchNorm2D-54 [[1, 256, 15, 15]] [1, 256, 15, 15] 1,024
ReLU-25 [[1, 256, 15, 15]] [1, 256, 15, 15] 0
Conv2D-55 [[1, 256, 15, 15]] [1, 256, 15, 15] 589,824
BatchNorm2D-55 [[1, 256, 15, 15]] [1, 256, 15, 15] 1,024
BasicBlock-22 [[1, 256, 15, 15]] [1, 256, 15, 15] 0
Conv2D-57 [[1, 256, 15, 15]] [1, 512, 8, 8] 1,179,648
BatchNorm2D-57 [[1, 512, 8, 8]] [1, 512, 8, 8] 2,048
ReLU-26 [[1, 512, 8, 8]] [1, 512, 8, 8] 0
Conv2D-58 [[1, 512, 8, 8]] [1, 512, 8, 8] 2,359,296
BatchNorm2D-58 [[1, 512, 8, 8]] [1, 512, 8, 8] 2,048
Conv2D-56 [[1, 256, 15, 15]] [1, 512, 8, 8] 131,072
BatchNorm2D-56 [[1, 512, 8, 8]] [1, 512, 8, 8] 2,048
BasicBlock-23 [[1, 256, 15, 15]] [1, 512, 8, 8] 0
Conv2D-59 [[1, 512, 8, 8]] [1, 512, 8, 8] 2,359,296
BatchNorm2D-59 [[1, 512, 8, 8]] [1, 512, 8, 8] 2,048
ReLU-27 [[1, 512, 8, 8]] [1, 512, 8, 8] 0
Conv2D-60 [[1, 512, 8, 8]] [1, 512, 8, 8] 2,359,296
BatchNorm2D-60 [[1, 512, 8, 8]] [1, 512, 8, 8] 2,048
BasicBlock-24 [[1, 512, 8, 8]] [1, 512, 8, 8] 0
AdaptiveAvgPool2D-3 [[1, 512, 8, 8]] [1, 512, 1, 1] 0
Linear-4 [[1, 512]] [1, 12] 6,156
===============================================================================
Total params: 11,192,268
Trainable params: 11,173,068
Non-trainable params: 19,200
-------------------------------------------------------------------------------
Input size (MB): 0.59
Forward/backward pass size (MB): 60.82
Params size (MB): 42.70
Estimated Total Size (MB): 104.10
-------------------------------------------------------------------------------
当前学习率策略为: Momentum + CosineAnnealingDecay
Epoch 0: CosineAnnealingDecay set learning rate to 0.001.
c:\Users\Administrator\anaconda3\lib\site-packages\paddle\nn\layer\norm.py:653: UserWarning: When training, we now always track global mean and variance.
warnings.warn(
2022-10-10 09:33:07,377 - INFO: Epoch:1/10, batch:10, train_loss:[2.62182], acc_top1:[0.14062], acc_top5:[0.46875](10.70s)
2022-10-10 09:33:18,382 - INFO: Epoch:1/10, batch:20, train_loss:[2.47331], acc_top1:[0.14062], acc_top5:[0.60938](11.01s)
2022-10-10 09:33:27,666 - INFO: Epoch:1/10, batch:30, train_loss:[2.31975], acc_top1:[0.12500], acc_top5:[0.68750](9.28s)
2022-10-10 09:33:37,437 - INFO: Epoch:1/10, batch:40, train_loss:[2.27189], acc_top1:[0.15625], acc_top5:[0.70312](9.77s)
2022-10-10 09:33:47,142 - INFO: Epoch:1/10, batch:50, train_loss:[2.35997], acc_top1:[0.17188], acc_top5:[0.71875](9.71s)
2022-10-10 09:33:56,588 - INFO: Epoch:1/10, batch:60, train_loss:[2.23680], acc_top1:[0.28125], acc_top5:[0.68750](9.45s)
2022-10-10 09:34:06,656 - INFO: Epoch:1/10, batch:70, train_loss:[2.30795], acc_top1:[0.12500], acc_top5:[0.62500](10.07s)
2022-10-10 09:34:17,760 - INFO: Epoch:1/10, batch:80, train_loss:[2.22627], acc_top1:[0.25000], acc_top5:[0.68750](11.10s)
2022-10-10 09:34:27,791 - INFO: Epoch:1/10, batch:90, train_loss:[2.28876], acc_top1:[0.21875], acc_top5:[0.67188](10.03s)
2022-10-10 09:34:37,990 - INFO: Epoch:1/10, batch:100, train_loss:[2.15088], acc_top1:[0.25000], acc_top5:[0.68750](10.20s)
2022-10-10 09:34:46,954 - INFO: Epoch:1/10, batch:110, train_loss:[2.17612], acc_top1:[0.25000], acc_top5:[0.79688](8.96s)
2022-10-10 09:34:59,382 - INFO: [validation] Epoch:1/10, val_loss:[0.03495], val_top1:[0.29846], val_top5:[0.73538]
c:\Users\Administrator\anaconda3\lib\site-packages\paddle\fluid\layers\math_op_patch.py:336: UserWarning: c:\Users\Administrator\anaconda3\lib\site-packages\paddle\vision\models\resnet.py:105
The behavior of expression A + B has been unified with elementwise_add(X, Y, axis=-1) from Paddle 2.0. If your code works well in the older versions but crashes in this version, try to use elementwise_add(X, Y, axis=0) instead of A + B. This transitional warning will be dropped in the future.
warnings.warn(
2022-10-10 09:35:00,980 - INFO: 已保存当前测试模型(epoch=1)为最优模型:Zodiac_resnet18_final
2022-10-10 09:35:00,981 - INFO: 最优top1测试精度:0.29846 (epoch=1)
2022-10-10 09:35:09,360 - INFO: Epoch:2/10, batch:120, train_loss:[1.99228], acc_top1:[0.37500], acc_top5:[0.84375](22.41s)
2022-10-10 09:35:19,747 - INFO: Epoch:2/10, batch:130, train_loss:[1.99555], acc_top1:[0.29688], acc_top5:[0.84375](10.39s)
2022-10-10 09:35:29,926 - INFO: Epoch:2/10, batch:140, train_loss:[1.97639], acc_top1:[0.37500], acc_top5:[0.79688](10.18s)
2022-10-10 09:35:41,835 - INFO: Epoch:2/10, batch:150, train_loss:[2.20575], acc_top1:[0.34375], acc_top5:[0.70312](11.91s)
2022-10-10 09:35:51,589 - INFO: Epoch:2/10, batch:160, train_loss:[1.91067], acc_top1:[0.40625], acc_top5:[0.84375](9.75s)
2022-10-10 09:36:00,755 - INFO: Epoch:2/10, batch:170, train_loss:[2.01263], acc_top1:[0.45312], acc_top5:[0.79688](9.17s)
2022-10-10 09:36:10,021 - INFO: Epoch:2/10, batch:180, train_loss:[1.91599], acc_top1:[0.37500], acc_top5:[0.82812](9.27s)
2022-10-10 09:36:19,450 - INFO: Epoch:2/10, batch:190, train_loss:[2.05409], acc_top1:[0.31250], acc_top5:[0.81250](9.43s)
2022-10-10 09:36:27,774 - INFO: Epoch:2/10, batch:200, train_loss:[2.09913], acc_top1:[0.28125], acc_top5:[0.68750](8.32s)
2022-10-10 09:36:37,975 - INFO: Epoch:2/10, batch:210, train_loss:[2.15534], acc_top1:[0.29688], acc_top5:[0.78125](10.20s)
2022-10-10 09:36:47,931 - INFO: Epoch:2/10, batch:220, train_loss:[1.91374], acc_top1:[0.37500], acc_top5:[0.81250](9.96s)
2022-10-10 09:37:01,093 - INFO: [validation] Epoch:2/10, val_loss:[0.03286], val_top1:[0.32308], val_top5:[0.77231]
2022-10-10 09:37:02,394 - INFO: 已保存当前测试模型(epoch=2)为最优模型:Zodiac_resnet18_final
2022-10-10 09:37:02,395 - INFO: 最优top1测试精度:0.32308 (epoch=2)
2022-10-10 09:37:07,966 - INFO: Epoch:3/10, batch:230, train_loss:[1.78984], acc_top1:[0.39062], acc_top5:[0.89062](20.03s)
2022-10-10 09:37:17,102 - INFO: Epoch:3/10, batch:240, train_loss:[1.81982], acc_top1:[0.37500], acc_top5:[0.84375](9.14s)
2022-10-10 09:37:27,909 - INFO: Epoch:3/10, batch:250, train_loss:[1.84358], acc_top1:[0.43750], acc_top5:[0.78125](10.81s)
2022-10-10 09:37:37,375 - INFO: Epoch:3/10, batch:260, train_loss:[1.90934], acc_top1:[0.35938], acc_top5:[0.82812](9.47s)
2022-10-10 09:37:48,017 - INFO: Epoch:3/10, batch:270, train_loss:[2.01069], acc_top1:[0.42188], acc_top5:[0.81250](10.64s)
2022-10-10 09:37:56,512 - INFO: Epoch:3/10, batch:280, train_loss:[1.83405], acc_top1:[0.32812], acc_top5:[0.89062](8.50s)
2022-10-10 09:38:06,764 - INFO: Epoch:3/10, batch:290, train_loss:[1.87799], acc_top1:[0.37500], acc_top5:[0.79688](10.25s)
2022-10-10 09:38:17,114 - INFO: Epoch:3/10, batch:300, train_loss:[1.75982], acc_top1:[0.48438], acc_top5:[0.82812](10.35s)
2022-10-10 09:38:26,655 - INFO: Epoch:3/10, batch:310, train_loss:[1.80843], acc_top1:[0.43750], acc_top5:[0.85938](9.54s)
2022-10-10 09:38:36,028 - INFO: Epoch:3/10, batch:320, train_loss:[1.88918], acc_top1:[0.34375], acc_top5:[0.84375](9.37s)
2022-10-10 09:38:45,954 - INFO: Epoch:3/10, batch:330, train_loss:[1.96423], acc_top1:[0.34375], acc_top5:[0.82812](9.93s)
2022-10-10 09:39:02,120 - INFO: [validation] Epoch:3/10, val_loss:[0.03141], val_top1:[0.35846], val_top5:[0.80308]
2022-10-10 09:39:03,342 - INFO: 已保存当前测试模型(epoch=3)为最优模型:Zodiac_resnet18_final
2022-10-10 09:39:03,343 - INFO: 最优top1测试精度:0.35846 (epoch=3)
2022-10-10 09:39:06,975 - INFO: Epoch:4/10, batch:340, train_loss:[1.82064], acc_top1:[0.42188], acc_top5:[0.87500](21.02s)
2022-10-10 09:39:17,454 - INFO: Epoch:4/10, batch:350, train_loss:[1.81407], acc_top1:[0.40625], acc_top5:[0.89062](10.48s)
2022-10-10 09:39:26,684 - INFO: Epoch:4/10, batch:360, train_loss:[1.84759], acc_top1:[0.32812], acc_top5:[0.76562](9.23s)
2022-10-10 09:39:38,364 - INFO: Epoch:4/10, batch:370, train_loss:[1.73768], acc_top1:[0.51562], acc_top5:[0.79688](11.68s)
2022-10-10 09:39:47,857 - INFO: Epoch:4/10, batch:380, train_loss:[1.79312], acc_top1:[0.43750], acc_top5:[0.84375](9.49s)
2022-10-10 09:39:57,897 - INFO: Epoch:4/10, batch:390, train_loss:[1.71574], acc_top1:[0.40625], acc_top5:[0.84375](10.04s)
2022-10-10 09:40:06,645 - INFO: Epoch:4/10, batch:400, train_loss:[1.79745], acc_top1:[0.31250], acc_top5:[0.87500](8.75s)
2022-10-10 09:40:16,598 - INFO: Epoch:4/10, batch:410, train_loss:[1.62778], acc_top1:[0.48438], acc_top5:[0.92188](9.95s)
2022-10-10 09:40:26,833 - INFO: Epoch:4/10, batch:420, train_loss:[1.67016], acc_top1:[0.45312], acc_top5:[0.82812](10.24s)
2022-10-10 09:40:36,132 - INFO: Epoch:4/10, batch:430, train_loss:[1.92659], acc_top1:[0.39062], acc_top5:[0.79688](9.30s)
2022-10-10 09:40:45,942 - INFO: Epoch:4/10, batch:440, train_loss:[1.47205], acc_top1:[0.60938], acc_top5:[0.92188](9.81s)
2022-10-10 09:41:03,551 - INFO: [validation] Epoch:4/10, val_loss:[0.02891], val_top1:[0.40000], val_top5:[0.83385]
2022-10-10 09:41:04,933 - INFO: 已保存当前测试模型(epoch=4)为最优模型:Zodiac_resnet18_final
2022-10-10 09:41:04,934 - INFO: 最优top1测试精度:0.40000 (epoch=4)
2022-10-10 09:41:07,513 - INFO: Epoch:5/10, batch:450, train_loss:[1.75191], acc_top1:[0.43750], acc_top5:[0.79688](21.57s)
2022-10-10 09:41:15,710 - INFO: Epoch:5/10, batch:460, train_loss:[1.57214], acc_top1:[0.48438], acc_top5:[0.87500](8.20s)
2022-10-10 09:41:25,630 - INFO: Epoch:5/10, batch:470, train_loss:[1.72044], acc_top1:[0.50000], acc_top5:[0.82812](9.92s)
2022-10-10 09:41:35,481 - INFO: Epoch:5/10, batch:480, train_loss:[1.67988], acc_top1:[0.46875], acc_top5:[0.89062](9.85s)
2022-10-10 09:41:45,949 - INFO: Epoch:5/10, batch:490, train_loss:[1.68304], acc_top1:[0.42188], acc_top5:[0.89062](10.47s)
2022-10-10 09:41:56,891 - INFO: Epoch:5/10, batch:500, train_loss:[1.51196], acc_top1:[0.56250], acc_top5:[0.90625](10.94s)
2022-10-10 09:42:06,481 - INFO: Epoch:5/10, batch:510, train_loss:[1.75515], acc_top1:[0.40625], acc_top5:[0.85938](9.59s)
2022-10-10 09:42:16,723 - INFO: Epoch:5/10, batch:520, train_loss:[1.57904], acc_top1:[0.50000], acc_top5:[0.84375](10.24s)
2022-10-10 09:42:26,102 - INFO: Epoch:5/10, batch:530, train_loss:[1.58411], acc_top1:[0.50000], acc_top5:[0.92188](9.38s)
2022-10-10 09:42:35,917 - INFO: Epoch:5/10, batch:540, train_loss:[1.49479], acc_top1:[0.54688], acc_top5:[0.84375](9.81s)
2022-10-10 09:42:45,806 - INFO: Epoch:5/10, batch:550, train_loss:[1.55097], acc_top1:[0.46875], acc_top5:[0.93750](9.89s)
2022-10-10 09:42:55,286 - INFO: Epoch:5/10, batch:560, train_loss:[1.60862], acc_top1:[0.45312], acc_top5:[0.87500](9.48s)
2022-10-10 09:43:05,305 - INFO: [validation] Epoch:5/10, val_loss:[0.02872], val_top1:[0.39538], val_top5:[0.82000]
2022-10-10 09:43:05,305 - INFO: 最优top1测试精度:0.40000 (epoch=4)
2022-10-10 09:43:14,793 - INFO: Epoch:6/10, batch:570, train_loss:[1.41854], acc_top1:[0.54688], acc_top5:[0.89062](19.51s)
2022-10-10 09:43:25,200 - INFO: Epoch:6/10, batch:580, train_loss:[1.47781], acc_top1:[0.56250], acc_top5:[0.89062](10.41s)
2022-10-10 09:43:34,901 - INFO: Epoch:6/10, batch:590, train_loss:[1.58387], acc_top1:[0.45312], acc_top5:[0.95312](9.70s)
2022-10-10 09:43:44,716 - INFO: Epoch:6/10, batch:600, train_loss:[1.49727], acc_top1:[0.43750], acc_top5:[0.87500](9.81s)
2022-10-10 09:43:55,794 - INFO: Epoch:6/10, batch:610, train_loss:[1.47223], acc_top1:[0.50000], acc_top5:[0.89062](11.08s)
2022-10-10 09:44:07,181 - INFO: Epoch:6/10, batch:620, train_loss:[1.60012], acc_top1:[0.51562], acc_top5:[0.82812](11.39s)
2022-10-10 09:44:16,695 - INFO: Epoch:6/10, batch:630, train_loss:[1.34373], acc_top1:[0.53125], acc_top5:[0.87500](9.51s)
2022-10-10 09:44:26,149 - INFO: Epoch:6/10, batch:640, train_loss:[1.49899], acc_top1:[0.50000], acc_top5:[0.87500](9.45s)
2022-10-10 09:44:35,726 - INFO: Epoch:6/10, batch:650, train_loss:[1.39287], acc_top1:[0.51562], acc_top5:[0.90625](9.58s)
2022-10-10 09:44:44,566 - INFO: Epoch:6/10, batch:660, train_loss:[1.52073], acc_top1:[0.51562], acc_top5:[0.90625](8.84s)
2022-10-10 09:44:54,164 - INFO: Epoch:6/10, batch:670, train_loss:[1.32979], acc_top1:[0.60938], acc_top5:[0.96875](9.60s)
2022-10-10 09:45:06,350 - INFO: [validation] Epoch:6/10, val_loss:[0.02844], val_top1:[0.42154], val_top5:[0.82923]
2022-10-10 09:45:07,698 - INFO: 已保存当前测试模型(epoch=6)为最优模型:Zodiac_resnet18_final
2022-10-10 09:45:07,699 - INFO: 最优top1测试精度:0.42154 (epoch=6)
2022-10-10 09:45:15,148 - INFO: Epoch:7/10, batch:680, train_loss:[1.33640], acc_top1:[0.56250], acc_top5:[0.93750](20.98s)
2022-10-10 09:45:25,547 - INFO: Epoch:7/10, batch:690, train_loss:[1.51451], acc_top1:[0.53125], acc_top5:[0.90625](10.40s)
2022-10-10 09:45:33,852 - INFO: Epoch:7/10, batch:700, train_loss:[1.38514], acc_top1:[0.45312], acc_top5:[0.93750](8.31s)
2022-10-10 09:45:43,427 - INFO: Epoch:7/10, batch:710, train_loss:[1.65837], acc_top1:[0.40625], acc_top5:[0.87500](9.57s)
2022-10-10 09:45:53,844 - INFO: Epoch:7/10, batch:720, train_loss:[1.43991], acc_top1:[0.50000], acc_top5:[0.90625](10.42s)
2022-10-10 09:46:04,258 - INFO: Epoch:7/10, batch:730, train_loss:[1.43480], acc_top1:[0.64062], acc_top5:[0.92188](10.41s)
2022-10-10 09:46:13,399 - INFO: Epoch:7/10, batch:740, train_loss:[1.39011], acc_top1:[0.59375], acc_top5:[0.92188](9.14s)
2022-10-10 09:46:23,671 - INFO: Epoch:7/10, batch:750, train_loss:[1.23530], acc_top1:[0.59375], acc_top5:[0.93750](10.27s)
2022-10-10 09:46:32,175 - INFO: Epoch:7/10, batch:760, train_loss:[1.43894], acc_top1:[0.57812], acc_top5:[0.87500](8.50s)
2022-10-10 09:46:43,105 - INFO: Epoch:7/10, batch:770, train_loss:[1.28441], acc_top1:[0.53125], acc_top5:[0.90625](10.93s)
2022-10-10 09:46:53,738 - INFO: Epoch:7/10, batch:780, train_loss:[1.48798], acc_top1:[0.45312], acc_top5:[0.87500](10.63s)
2022-10-10 09:47:08,408 - INFO: [validation] Epoch:7/10, val_loss:[0.02718], val_top1:[0.42923], val_top5:[0.83231]
2022-10-10 09:47:09,724 - INFO: 已保存当前测试模型(epoch=7)为最优模型:Zodiac_resnet18_final
2022-10-10 09:47:09,725 - INFO: 最优top1测试精度:0.42923 (epoch=7)
2022-10-10 09:47:15,210 - INFO: Epoch:8/10, batch:790, train_loss:[1.33564], acc_top1:[0.59375], acc_top5:[0.89062](21.47s)
2022-10-10 09:47:25,240 - INFO: Epoch:8/10, batch:800, train_loss:[1.51294], acc_top1:[0.51562], acc_top5:[0.93750](10.03s)
2022-10-10 09:47:36,104 - INFO: Epoch:8/10, batch:810, train_loss:[1.15807], acc_top1:[0.67188], acc_top5:[0.95312](10.86s)
2022-10-10 09:47:47,170 - INFO: Epoch:8/10, batch:820, train_loss:[1.35702], acc_top1:[0.56250], acc_top5:[0.95312](11.07s)
2022-10-10 09:47:56,941 - INFO: Epoch:8/10, batch:830, train_loss:[1.15045], acc_top1:[0.65625], acc_top5:[0.95312](9.77s)
2022-10-10 09:48:07,027 - INFO: Epoch:8/10, batch:840, train_loss:[1.29139], acc_top1:[0.54688], acc_top5:[0.93750](10.09s)
2022-10-10 09:48:15,809 - INFO: Epoch:8/10, batch:850, train_loss:[1.09448], acc_top1:[0.65625], acc_top5:[0.98438](8.78s)
2022-10-10 09:48:25,680 - INFO: Epoch:8/10, batch:860, train_loss:[1.36041], acc_top1:[0.57812], acc_top5:[0.92188](9.87s)
2022-10-10 09:48:35,591 - INFO: Epoch:8/10, batch:870, train_loss:[1.19146], acc_top1:[0.60938], acc_top5:[0.95312](9.91s)
2022-10-10 09:48:44,523 - INFO: Epoch:8/10, batch:880, train_loss:[1.40162], acc_top1:[0.51562], acc_top5:[0.93750](8.93s)
2022-10-10 09:48:53,848 - INFO: Epoch:8/10, batch:890, train_loss:[1.30286], acc_top1:[0.65625], acc_top5:[0.92188](9.33s)
2022-10-10 09:49:10,057 - INFO: [validation] Epoch:8/10, val_loss:[0.02846], val_top1:[0.42615], val_top5:[0.82615]
2022-10-10 09:49:10,057 - INFO: 最优top1测试精度:0.42923 (epoch=7)
2022-10-10 09:49:14,252 - INFO: Epoch:9/10, batch:900, train_loss:[1.05535], acc_top1:[0.73438], acc_top5:[0.93750](20.40s)
2022-10-10 09:49:22,449 - INFO: Epoch:9/10, batch:910, train_loss:[1.09239], acc_top1:[0.68750], acc_top5:[0.93750](8.20s)
2022-10-10 09:49:32,646 - INFO: Epoch:9/10, batch:920, train_loss:[1.04044], acc_top1:[0.68750], acc_top5:[0.96875](10.20s)
2022-10-10 09:49:42,578 - INFO: Epoch:9/10, batch:930, train_loss:[1.11283], acc_top1:[0.70312], acc_top5:[0.96875](9.93s)
2022-10-10 09:49:51,947 - INFO: Epoch:9/10, batch:940, train_loss:[0.93646], acc_top1:[0.70312], acc_top5:[0.95312](9.37s)
2022-10-10 09:50:02,587 - INFO: Epoch:9/10, batch:950, train_loss:[1.15108], acc_top1:[0.64062], acc_top5:[0.96875](10.64s)
2022-10-10 09:50:12,101 - INFO: Epoch:9/10, batch:960, train_loss:[0.98588], acc_top1:[0.70312], acc_top5:[0.96875](9.51s)
2022-10-10 09:50:22,221 - INFO: Epoch:9/10, batch:970, train_loss:[1.15960], acc_top1:[0.60938], acc_top5:[0.95312](10.12s)
2022-10-10 09:50:31,349 - INFO: Epoch:9/10, batch:980, train_loss:[1.34767], acc_top1:[0.59375], acc_top5:[0.89062](9.13s)
2022-10-10 09:50:41,846 - INFO: Epoch:9/10, batch:990, train_loss:[1.15957], acc_top1:[0.65625], acc_top5:[0.96875](10.50s)
2022-10-10 09:50:53,485 - INFO: Epoch:9/10, batch:1000, train_loss:[1.27997], acc_top1:[0.57812], acc_top5:[0.95312](11.64s)
2022-10-10 09:51:10,705 - INFO: [validation] Epoch:9/10, val_loss:[0.02835], val_top1:[0.42462], val_top5:[0.84923]
2022-10-10 09:51:10,706 - INFO: 最优top1测试精度:0.42923 (epoch=7)
2022-10-10 09:51:12,503 - INFO: Epoch:10/10, batch:1010, train_loss:[0.95354], acc_top1:[0.70312], acc_top5:[1.00000](19.02s)
2022-10-10 09:51:21,849 - INFO: Epoch:10/10, batch:1020, train_loss:[0.94593], acc_top1:[0.76562], acc_top5:[0.98438](9.35s)
2022-10-10 09:51:31,641 - INFO: Epoch:10/10, batch:1030, train_loss:[1.02807], acc_top1:[0.62500], acc_top5:[1.00000](9.79s)
2022-10-10 09:51:42,326 - INFO: Epoch:10/10, batch:1040, train_loss:[0.88558], acc_top1:[0.73438], acc_top5:[0.98438](10.68s)
2022-10-10 09:51:51,474 - INFO: Epoch:10/10, batch:1050, train_loss:[0.99334], acc_top1:[0.78125], acc_top5:[0.96875](9.15s)
2022-10-10 09:52:02,095 - INFO: Epoch:10/10, batch:1060, train_loss:[0.98375], acc_top1:[0.68750], acc_top5:[0.98438](10.62s)
2022-10-10 09:52:12,074 - INFO: Epoch:10/10, batch:1070, train_loss:[0.91140], acc_top1:[0.73438], acc_top5:[0.98438](9.98s)
2022-10-10 09:52:22,908 - INFO: Epoch:10/10, batch:1080, train_loss:[0.87209], acc_top1:[0.78125], acc_top5:[0.98438](10.83s)
2022-10-10 09:52:31,984 - INFO: Epoch:10/10, batch:1090, train_loss:[0.98302], acc_top1:[0.59375], acc_top5:[1.00000](9.08s)
2022-10-10 09:52:41,795 - INFO: Epoch:10/10, batch:1100, train_loss:[1.10088], acc_top1:[0.65625], acc_top5:[0.93750](9.81s)
2022-10-10 09:52:53,725 - INFO: Epoch:10/10, batch:1110, train_loss:[0.96327], acc_top1:[0.75000], acc_top5:[0.98438](11.93s)
2022-10-10 09:53:03,224 - INFO: Epoch:10/10, batch:1120, train_loss:[1.05355], acc_top1:[0.68750], acc_top5:[0.96875](9.50s)
2022-10-10 09:53:13,253 - INFO: [validation] Epoch:10/10, val_loss:[0.02803], val_top1:[0.43231], val_top5:[0.85077]
2022-10-10 09:53:14,585 - INFO: 已保存当前测试模型(epoch=10)为最优模型:Zodiac_resnet18_final
2022-10-10 09:53:14,585 - INFO: 最优top1测试精度:0.43231 (epoch=10)
2022-10-10 09:53:14,586 - INFO: 训练完成,最终性能accuracy=0.43231(epoch=10), 总耗时1217.91s, 已将其保存为:Zodiac_resnet18_final
2022-10-10 09:53:14,586 - INFO: 训练完毕,结果路径D:\Workspace\ExpResults\Project012AlexNetZodiac.
2022-10-10 09:53:14,587 - INFO: Done.
训练完成后,建议将 ExpResults 文件夹的最终文件 copy 到 ExpDeployments 用于进行部署和应用。
3.5 离线测试的代码
from paddle.static import InputSpec
if __name__ == '__main__':
# 设置输入样本的维度
input_spec = InputSpec(shape=[None] + args['input_size'], dtype='float32', name='image')
label_spec = InputSpec(shape=[None, 1], dtype='int64', name='label')
# 载入模型
network = paddle.vision.models.resnet18(num_classes=12)
model = paddle.Model(network, input_spec, label_spec) # 模型实例化
model.load(deployment_checkpoint_path) # 载入调优模型的参数
model.prepare(loss=paddle.nn.CrossEntropyLoss(), # 设置loss
metrics=paddle.metric.Accuracy(topk=(1,5))) # 设置评价指标
# 执行评估函数,并输出验证集样本的损失和精度
print('开始评估...')
avg_loss, avg_acc_top1, avg_acc_top5 = eval(model, val_reader(), verbose=1)
print('\r [验证集] 损失: {:.5f}, top1精度:{:.5f}, top5精度为:{:.5f} \n'.format(avg_loss, avg_acc_top1, avg_acc_top5), end='')
avg_loss, avg_acc_top1, avg_acc_top5 = eval(model, test_reader(), verbose=1)
print('\r [测试集] 损失: {:.5f}, top1精度:{:.5f}, top5精度为:{:.5f}'.format(avg_loss, avg_acc_top1, avg_acc_top5), end='')
开始评估...
[验证集] 损失: 0.02803, top1精度:0.43231, top5精度为:0.85077
[测试集] 损失: 0.03046, top1精度:0.40758, top5精度为:0.85152
【结果分析】
需要注意的是此处的精度与训练过程中输出的测试精度是不相同的,因为训练过程中使用的是验证集, 而这里的离线测试使用的是测试集.
【实验四】 模型推理和预测(应用)
实验摘要: 对训练过的模型,我们通过测试集进行模型效果评估,并可以在实际场景中进行预测,查看模型的效果。
实验目的:
- 学会使用部署和推理模型进行测试
- 学会对测试样本使用
基本预处理方法和十重切割对样本进行预处理 - 对于测试样本,能够实现批量测试test()和单样本推理predict()
4.1 导入依赖库及全局参数配置
# 导入依赖库
import numpy as np
import random
import os
import cv2
import json
import matplotlib.pyplot as plt
import paddle
import paddle.nn.functional as F
args={
'project_name': 'Project026ResNetZodiac',
'dataset_name': 'Zodiac',
'architecture': 'ResNet18',
'input_size': [227, 227, 3],
'mean_value': [0.485, 0.456, 0.406], # Imagenet均值
'std_value': [0.229, 0.224, 0.225], # Imagenet标准差
'dataset_root_path': 'D:\\Workspace\\ExpDatasets\\',
'result_root_path': 'D:\\Workspace\\ExpResults\\',
'deployment_root_path': 'D:\\Workspace\\ExpDeployments\\',
}
model_name = args['dataset_name'] + '_' + args['architecture']
deployment_final_models_path = os.path.join(args['deployment_root_path'], args['project_name'], 'final_models', model_name + '_final')
dataset_root_path = os.path.join(args['dataset_root_path'], args['dataset_name'])
json_dataset_info = os.path.join(dataset_root_path, 'dataset_info.json')
4.2 定义推理时的预处理函数
import paddle
import paddle.vision.transforms as T
# 2. 用于测试的十重切割
def TenCrop(img, crop_size=args['input_size'][0]):
# input_data: Height x Width x Channel
img_size = 256
img = T.functional.resize(img, (img_size, img_size))
data = np.zeros([10, crop_size, crop_size, 3], dtype=np.uint8)
# 获取左上、右上、左下、右下、中央,及其对应的翻转,共计10个样本
data[0] = T.functional.crop(img,0,0,crop_size,crop_size)
data[1] = T.functional.crop(img,0,img_size-crop_size,crop_size,crop_size)
data[2] = T.functional.crop(img,img_size-crop_size,0,crop_size,crop_size)
data[3] = T.functional.crop(img,img_size-crop_size,img_size-crop_size,crop_size,crop_size)
data[4] = T.functional.center_crop(img, crop_size)
data[5] = T.functional.hflip(data[0, :, :, :])
data[6] = T.functional.hflip(data[1, :, :, :])
data[7] = T.functional.hflip(data[2, :, :, :])
data[8] = T.functional.hflip(data[3, :, :, :])
data[9] = T.functional.hflip(data[4, :, :, :])
return data
# 3. 对于单幅图片(十重切割)所使用的数据预处理,包括均值消除,尺度变换
def SimplePreprocessing(image, input_size = args['input_size'][0:2], isTenCrop = True):
image = cv2.resize(image, input_size)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
transform = T.Compose([
T.ToTensor(),
T.Normalize(mean=args['mean_value'], std=args['std_value'])
])
if isTenCrop:
fake_data = np.zeros([10, 3, input_size[0], input_size[1]], dtype=np.float32)
fake_blob = TenCrop(image)
for i in range(10):
fake_data[i] = transform(fake_blob[i]).numpy()
else:
fake_data = transform(image)
return fake_data
##############################################################
# 测试输入数据类:分别输出进行预处理和未进行预处理的数据形态和例图
if __name__ == "__main__":
img_path = 'D:\\Workspace\\ExpDatasets\\Zodiac\\test\\dragon\\00000039.jpg'
img0 = cv2.imread(img_path, 1)
img1 = SimplePreprocessing(img0, isTenCrop=False)
img2 = SimplePreprocessing(img0, isTenCrop=True)
print('原始图像的形态为: {}'.format(img0.shape))
print('简单预处理后(经过十重切割后): {}'.format(img1.shape))
print('简单预处理后(未经过十重切割后) {}'.format(img2.shape))
img1_show = img1.transpose((1, 2, 0))
img2_show = img2[0].transpose((1, 2, 0))
plt.figure(figsize=(18, 6))
ax0 = plt.subplot(1,3,1)
ax0.set_title('img0')
plt.imshow(img0)
ax1 = plt.subplot(1,3,2)
ax1.set_title('img1_show')
plt.imshow(img1_show)
ax2 = plt.subplot(1,3,3)
ax2.set_title('img2_show')
plt.imshow(img2_show)
plt.show()
原始图像的形态为: (563, 1000, 3)
简单预处理后(经过十重切割后): [3, 227, 227]
简单预处理后(未经过十重切割后) (10, 3, 227, 227)

#################################################
# 修改者: Xinyu Ou (http://ouxinyu.cn)
# 功能: 使用部署模型对测试集进行评估
# 基本功能:
# 1. 使用部署模型在测试集上进行批量预测,并输出预测结果
# 2. 使用部署模型在测试集上进行单样本预测,并对预测结果和真实结果进行对比
#################################################
# 1. 使用部署模型在测试集上进行准确度评估
def test(model, data_reader):
accs = []
n_total = 0
for batch_id, (image, label) in enumerate(data_reader):
n_batch = len(label)
n_total = n_total + n_batch
# 将label扩展为规定的np矩阵
label = paddle.unsqueeze(label, axis=1)
logits = model(image)
pred = F.softmax(logits)
acc = paddle.metric.accuracy(pred, label)
accs.append(acc.numpy()*n_batch)
avg_acc = np.sum(accs)/n_total
print('测试集的精确度: {:.5f}'.format(avg_acc))
# 2. 使用部署模型在测试集上进行单样本预测
def predict(model, image):
# Q6. 完成下列数据推理部分predic()函数的代码
# [Your codes 8]
isTenCrop = False
image = SimplePreprocessing(image, isTenCrop=isTenCrop)
print(image.shape)
if isTenCrop:
logits = model(image)
pred = F.softmax(logits)
pred = np.mean(pred.numpy(), axis=0)
else:
image = paddle.unsqueeze(image, axis=0)
logits = model(image)
pred = F.softmax(logits)
pred_id = np.argmax(pred)
return pred_id
##############################################################
if __name__ == '__main__':
# 0. 载入模型
model = paddle.jit.load(deployment_final_models_path)
# 1. 计算测试集的准确度
# test(model, test_reader())
# 2. 输出单个样本测试结果
# 2.1 获取待预测样本的标签信息
with open(json_dataset_info, 'r') as f_info:
dataset_info = json.load(f_info)
# 2.2 从测试列表中随机选择一副图像
test_list = os.path.join(dataset_root_path, 'test.txt')
with open(test_list, 'r') as f_test:
lines = f_test.readlines()
line = random.choice(lines)
img_path, label = line.split()
img_path = os.path.join(dataset_root_path, 'Data', img_path)
# img_path = 'D:\\Workspace\\ExpDatasets\\Butterfly\\Data\\zebra\\zeb033.jpg'
image = cv2.imread(img_path, 1)
# 2.4 给出待测样本的类别
pred_id = predict(model, image)
# # 将预测的label和ground_turth label转换为label name
label_name_gt = dataset_info['label_dict'][str(label)]
label_name_pred = dataset_info['label_dict'][str(pred_id)]
print('待测样本的类别为:{}, 预测类别为:{}'.format(label_name_gt, label_name_pred))
# 2.5 显示待预测样本
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
plt.imshow(image_rgb)
plt.show()
[3, 227, 227]
待测样本的类别为:dragon, 预测类别为:dragon
