【项目025】基于CNN的手势识别(学生版) 教学版 | 返回首页
作者:欧新宇(Xinyu OU)
当前版本:Release v2.0
开发平台:Paddle 2.5.2
运行环境:Intel Core i7-7700K CPU 4.2GHz, nVidia GeForce GTX 1080 Ti
本教案所涉及的数据集仅用于教学和交流使用,请勿用作商用。
最后更新:2024年6月2日
在当今科技日新月异的时代,人机交互(HCI)的方式正经历着从传统的键盘、鼠标向更加自然、直观的手势识别的转变。这一变革在虚拟现实(VR)、增强现实(AR)、智能家居、机器人控制等领域中显得尤为重要。在这样的背景下,基于卷积神经网络(CNN)的手势识别技术应运而生,成为推动人机交互技术发展的关键力量。手势识别技术旨在通过捕捉和分析人的手势动作,将其转化为计算机可理解的指令或信息。然而,由于手势的多样性、复杂性和实时性,传统的手势识别方法往往难以达到理想的识别效果和实时性能。而CNN作为一种深度学习方法,以其强大的特征提取和学习能力,为手势识别提供了新的解决方案。基于CNN的手势识别项目,旨在通过构建和优化深度神经网络模型,实现对复杂手势的高效、准确识别。虽然本项目仅给出了一个最简单版本的基于CNN的手势识别,但其代码框架是完整的,通过进一步扩展数据集的复杂性、增加更丰富的数据预处理方法、设计性能更好的深度学习模型,识别性能将直线上升。随着技术的不断进步和应用领域的不断拓展,相信基于CNN的手势识别技术将在未来发挥更加重要的作用。
【实验说明】
一. 实验目的
- 学会对下载的数据集进行初步整理,包括处理非法文件名、创建数据列表
- 学会将数据集划分为训练集、验证集和测试集
- 学会按照神经网络的设计要求创建神经网络类
- 学会使用mini-batch方法实现卷积神经网络的训练并进行预测
- 学会保存模型,并使用保存的模型进行预测(即应用模型到生产环境)
- 学会使用函数化编程方法完成卷积神经网络的训练和测试
- 学会在已有代码的基础上完成新任务的迭代
二. 实验要求
- 所有作业均在AIStudio上进行提交,提交时包含源代码s果
- Q1: 补全下列代码,实现将数据集按照7:1:2的比例分为训练集train, 验证集val 和测试集test(10分)
- Q2:完成数据集类定义的部分代码(10分)
- Q3: 根据拓扑结构图补全网络参数配置表(10分)
- Q4:根据Cifar10网络拓扑结构图和网络参数配置表完成神经Cifar10模型类定义(10分)
- Q5. 完成下列模型训练函数的主体部分(20分)
- Q6. 完成主函数的定义(10分)
- Q7. 完成离线测试的模型载入代码(10分)
- Q8:使用训练好的模型手势进行预测(20分)
- Q9:完成对真实世界的手势识别(+10分)
三. 思维导图
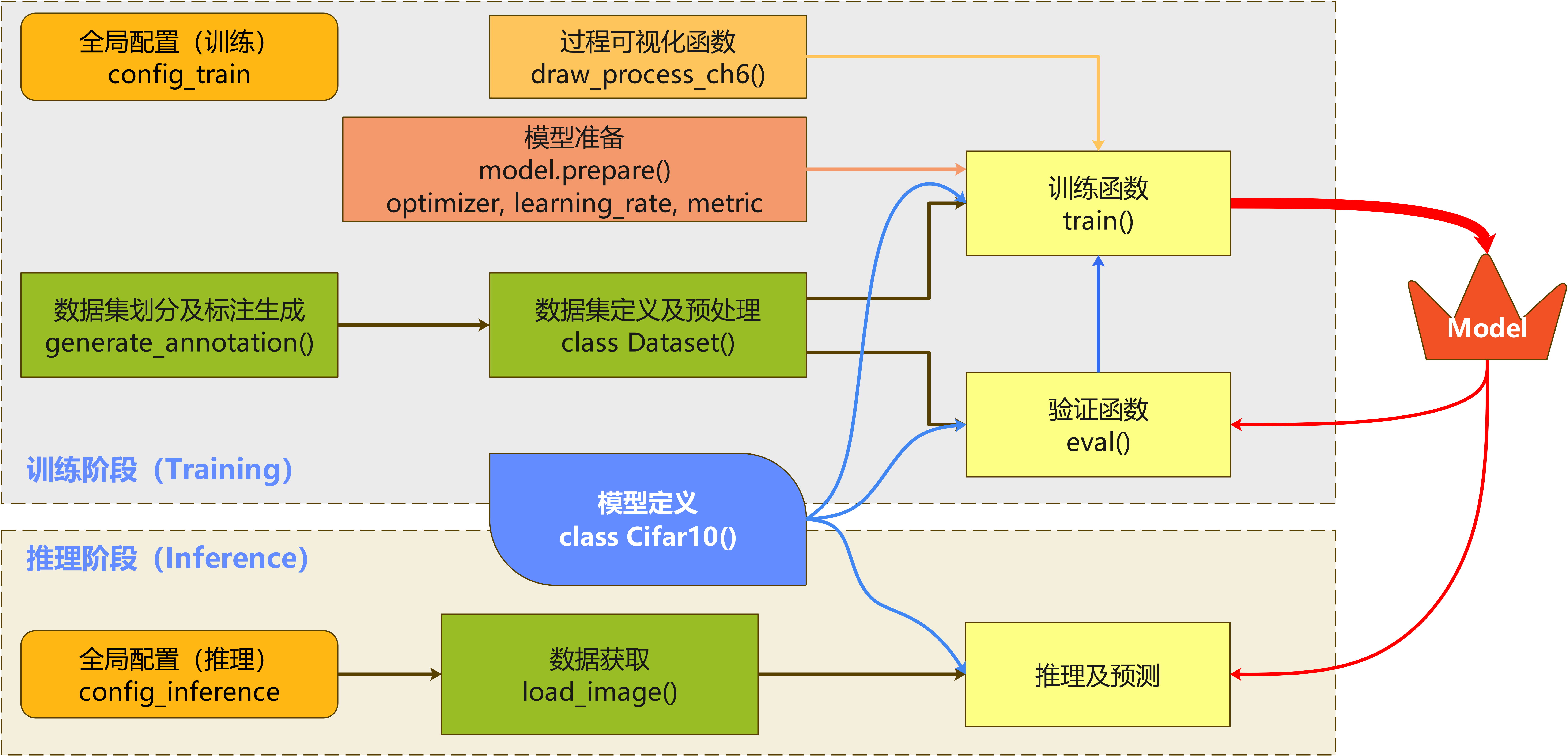
四. 目录结构
- 本项目目录结构说明(可根据实际情况进行修改)
- 数据集根目录:D:\WorkSpace\ExpDatasets\Gestures
- 模型保存目录:D:\WorkSpace\ExpResults\Project025CNNGestures
- 最终模型名称:final_model
【实验一】 数据集准备
实验摘要: 对于模型训练的任务,需要数据预处理,将数据整理成为适合给模型训练使用的格式。手势识别是一个简单的多分类的任务,数据集中有10个不同的手势,总共2062张图片,包含从0-9,A-Z,以及各省简称的图片。每个图片都是100×100的彩色图像,我们需要将图片读入,并按照7:1:2划分训练集、测试集和测试集。
实验目的:
- 学会观察数据集的文件,并实现基本的数据清理方法,包括删除无法读取的样本、处理冗长不合规范的文件命名等
- 能够按照训练集、验证集、训练验证集、测试集四种子集对数据集进行划分,并生成数据列表
- 能简单展示和预览数据的基本信息,包括数据量,规模,数据类型和位深度等
1.1 数据集介绍
手势识别 数据集是由土耳其一所中学制作,数据集由Data文件夹中的训练验证数据和Infer文件夹中的预测数据组成,包含0-9共10种数字的手势。以下为该数据集的官方描述:
This dataset is prepared by Turkey Ankara Ayrancı Anadolu high school students.
Image size: 100 x 100 pixels
Color space: RGB
Number of classes: 10 (Digits: 0-9)
Number of participant students: 218
Number of samples per student: 10
Dataset Url:https://github.com/ardamavi/Sign-Language-Digits-Dataset

数据集下载:https://aistudio.baidu.com/aistudio/datasetdetail/54000
1.2 生成数据列表
数据列表生成代码只需要执行一次,若已经实现分割好,则可跳过该部分代码。若官方数据集没有数据集的划分列表,或者数据集为自建数据集,则需要手动生成数据集的划分,一般包括训练集、验证集和测试集。要求在数据集文件夹内包含 train.txt, test.txt, val.txt, trainval.txt 和 dataset_info.json等五个文件。
值得注意的是,在进行数据划分的时候要注意类别的均衡性,处理的方法主要有两种。一是,对所有样本进行打乱,再进行划分;二是,顺序遍历不同类别的文件夹,然后均匀划分。下面的代码属于第二种。有兴趣的同学可以尝试第一种方法。例如在1.2.1节改名的时候,就收集文件名,并进行打乱。
Q1: 补全下列代码,实现将数据集按照7:1:2的比例分为训练集train, 验证集val 和测试集test(10分) ([Your codes 1~3])
##################################################################################
# 数据集预处理
# 作者: Xinyu Ou (http://ouxinyu.cn)
# 数据集名称:手势数据集Gestures
# 数据集简介: 数据集包含从0~9总共10种不同的手势的2062个样本.
# 本程序功能:
# 1. 将数据集按照7:1:2的比例划分为训练验证集、训练集、验证集、测试集
# 2. 代码将生成4个文件:训练验证集trainval.txt, 训练集列表train.txt, 验证集列表val.txt, 测试集列表test.txt, 数据集信息dataset_info.json
# 3. 代码输出信息:图像列表已生成, 其中训练验证集样本1642,训练集样本1432个, 验证集样本210个, 测试集样本420个, 共计2062个。
###################################################################################
import os
import json
import codecs
num_trainval = 0
num_train = 0
num_val = 0
num_test = 0
class_dim = 0
dataset_info = {
'dataset_name': '',
'num_trainval': -1,
'num_train': -1,
'num_val': -1,
'num_test': -1,
'class_dim': -1,
'label_dict': {}
}
# 本地运行时,需要修改数据集的名称和绝对路径,注意和文件夹名称一致
dataset_name = 'Gestures'
dataset_path = 'D:\\Workspace\\ExpDatasets\\'
dataset_root_path = os.path.join(dataset_path, dataset_name)
excluded_folder = ['.DS_Store', '.ipynb_checkpoints'] # 被排除的文件夹
# Q1-1: 补全下列代码实现数据集列表路径的路径定义和数据集信息文件的路径定义
# [Your codes 1]
# 检测数据集列表是否存在,如果存在则先删除。其中测试集列表是一次写入,因此可以通过'w'参数进行覆盖写入,而不用进行手动删除。
if os.path.exists(trainval_list):
os.remove(trainval_list)
if os.path.exists(train_list):
os.remove(train_list)
if os.path.exists(val_list):
os.remove(val_list)
if os.path.exists(test_list):
os.remove(test_list)
# Q1-2:不全下列代码,按照7:2:1的比例将数据集划分为训练集train、验证集val、测试集test和训练验证集trainval
# [Your codes 2]
# Q1-3: 将程序运行的相关结果保存到数据集信息json文件中
# [Your codes 3]
dataset_info['dataset_name'] =
dataset_info['num_trainval'] =
dataset_info['num_train'] =
dataset_info['num_val'] =
dataset_info['num_test'] =
dataset_info['class_dim'] =
with codecs.open(dataset_info_list, 'w', encoding='utf-8') as f_dataset_info:
json.dump(dataset_info, f_dataset_info, ensure_ascii=False, indent=4, separators=(',', ':')) # 格式化字典格式的参数列表
print("图像列表已生成, 其中训练验证集样本{},训练集样本{}个, 验证集样本{}个, 测试集样本{}个, 共计{}个。".format(num_trainval, num_train, num_val, num_test, num_train+num_val+num_test))
图像列表已生成, 其中训练验证集样本1642,训练集样本1432个, 验证集样本210个, 测试集样本420个, 共计2062个。
【实验二】 全局参数设置及数据准备
实验摘要: 基于CNN的彩色图片识别是一种多分类问题,本项目使用CIFAR-10网络作为CNN模型对手势识别图片进行分类。实验二通过PaddlePaddle构造一个CIFAR10卷积神经的网络,最后一层采用Softmax概率归一化函数完成分类任务。
实验目的:
- 学会使用配置文件定义全局参数
- 学会设置和载入数据集
- 学会对输入样本进行基本的预处理
- 学会定义可视化函数,可视化训练过程
2.1 导入依赖及全局参数设置
# 1. 导入依赖库
import os
import cv2
import codecs
import json
import numpy as np
import time # 载入time时间库,用于计算训练时间
import paddle # 载入PaddlePaddle基本库
import matplotlib.pyplot as plt # 载入matplotlib绘图库
import warnings
warnings.filterwarnings("ignore", category=UserWarning)
# 2. 全局参数配置
# 2.1 定义项目基本情况和数据集路径
dataset_name = 'Gestures'
project_name = 'Project025CNNGestures'
architecture = 'CIFAR10'
dataset_path = 'D:\\Workspace\\ExpDatasets\\'
dataset_root_path = os.path.join(dataset_path, dataset_name)
# 2.2 定义结果输出路径
result_root_path = 'D:\\Workspace\\ExpResults\\'
result_root_path = os.path.join(result_root_path, project_name) # 定义结果保存路径
final_models_path = os.path.join(result_root_path, 'final_models', 'best_model') # 定义模型的保存的路径
final_figures_path = os.path.join(result_root_path, 'final_figures') # 定义可视化图的输出路径
# 2.3 定义图像基本信息
img_size = [32, 32, 3] # 此处图像的尺寸为模型的尺寸,而不是图像的真实尺寸
# 2.3 训练参数定义
total_epoch = 20 # 总迭代次数, 代码调试好后考虑Epochs_num = 50
log_interval = 10
eval_interval = 1 # 设置在训练过程中,每隔一定的周期进行一次测试
learning_rate = 0.001 # 学习率
momentum = 0.9 # 动量
BATCH_SIZE = 64 # 设置每个批次的数据大小,同时对训练提供器和测试提供器有效
2.2 定义数据集类
通过集成飞桨内置的 paddle.io.Dataset 实现数据集类的定义,包括数据列表读取和数据预处理。
Q2:完成数据集类定义的部分代码(10分) ([Your codes 4~7])
要求:
1. 使用opencv库实现相关功能
2. 注意在本项目中,原始数据的尺度为100×100×3,为了适配本例的CIFAR模型,需要在数据预处理时,将样本压缩至模型输入的尺寸,例如Cifar的32×32。在后续的其他模型中,也需要压缩到模型规定的尺寸,例如:AlexNet为224×224。
3. 将图像数据类型转换为32位浮点型
4. 调整数据为paddle默认格式[C,H,W]
5. 将像素归一化到[0,1]之间
import paddle.vision.transforms as T
from paddle.io import DataLoader
# 1. 定义数据集
class Dataset(paddle.io.Dataset): # 继承 paddle.io.Dataset 类
def __init__(self, dataset_root_path, mode='test'):
# 初始化数据集,将样本和标签映射到列表中
assert mode in ['train', 'val', 'test', 'trainval']
self.data = [] # 创建空列表文件,用于保存数据的路径和标签
# Q1-1 读取数据集列表文件,并将路径路径和标签进行拆分,其中测试集若不存在标签则复制为"-1"
# [Your codes 1]
# Q1-2 使用transform接口定义数据预处理,本例需要规范图像尺度为[20,20], 并将图像转换为Paddle要求的Tensor
# [Your codes 5]
# 传入定义好的数据处理方法,作为自定义数据集类的一个属性
# 根据索引获取单个样本
def __getitem__(self, index):
# Q2-3: 对self.data变量进行拆分,划分为图像路径及标签,并按照路径进行图像载入
# [Your codes 6]
# 1. 根据索引,从列表中取出一个图像,并将数据拆分成路径和列表
# 2. 使用cv2进行数据读取可以强制将的图像转化为彩色模式,其中0为灰度模式,1为彩色模式
# 3. 将图像数据类型转化为float32(Paddle默认的内部数据格式)
# 4. 将像素值归一化到[0, 1]之间,仅在MLP中使用
# 5. 调整数据形状paddle默认张量格式
# 6. CrossEntropyLoss要求label格式为int,将Label格式转换为 int
return img, label
# Q2-4 获取样本总数
# 步骤四:实现 __len__ 函数,返回数据集的样本总数
# [Your codes 7]
2.3 设置训练和测试数据提供器
对于要使用的所有数据均需要设置数据提供器,本例我们给出基于训练集、验证集和测试集和训练验证集划分的设置。
# 1. 实例化数据类
dataset_train = Dataset(dataset_root_path, mode='train')
dataset_val = Dataset(dataset_root_path, mode='val')
dataset_trainval = Dataset(dataset_root_path, mode='trainval')
dataset_test = Dataset(dataset_root_path, mode='test')
# 2. 创建迭代读取器
# 使用paddle.io.DataLoader 定义DataLoader对象用于加载Python生成器产生的数据,
# DataLoader 返回的是一个批次数据迭代器,并且是异步的。
train_reader = DataLoader(dataset_train, batch_size=64, shuffle=True, drop_last=True)
val_reader = DataLoader(dataset_val, batch_size=64, shuffle=False, drop_last=False)
trainval_reader = DataLoader(dataset_trainval, batch_size=64, shuffle=True, drop_last=True)
test_reader = DataLoader(dataset_test, batch_size=64, shuffle=False, drop_last=False)
#####################################################################################################
# 数据迭代器测试
# 1. 输出数据集的基本情况
print('数据集包含训练数据{}个,验证数据{}个,训练验证集{}个,测试数据{}个。'.format(len(dataset_train),len(dataset_val),len(dataset_trainval),len(dataset_test)))
print('数据的形态为:{}'.format(dataset_val[0][0].shape))
# 2. 迭代的读取数据并打印数据的形状
for i, (img, label) in enumerate(val_reader()):
if i > 2:
break
print('验证集batch_{}的图像形态:{}, 标签形态:{}'.format(i, img.shape, label.shape))
数据集包含训练数据1432个,验证数据210个,训练验证集292个,测试数据420个。
数据的形态为:[3, 32, 32]
验证集batch_0的图像形态:[64, 3, 32, 32], 标签形态:[64]
验证集batch_1的图像形态:[64, 3, 32, 32], 标签形态:[64]
验证集batch_2的图像形态:[64, 3, 32, 32], 标签形态:[64]
2.4 定义过程可视化函数
定义训练过程中用到的可视化方法, 包括训练损失, 训练集批准确率, 测试集准确率. 根据具体的需求,可以在训练后展示这些数据和迭代次数的关系。值得注意的是, 训练过程中可以每个epoch绘制一个数据点,也可以每个batch绘制一个数据点,也可以每个n个batch或n个epoch绘制一个数据点.
def draw_process_ch6(visualization_log, show_top5=False, figure_path=final_figures_path, figurename='visualization_log', isShow=True):
"""绘制训练过程中的训练误差、训练精度、验证误差和验证精度四个重要输出"""
train_losses = visualization_log['train_losses'] # 训练集的损失值
train_accs_top1 = visualization_log['train_accs_top1'] # 训练集的top1精确度
train_accs_top5 = visualization_log['train_accs_top5'] # 训练集的top5精确度
val_losses = visualization_log['val_losses'] # 验证集的损失值
val_accs_top1 = visualization_log['val_accs_top1'] # 验证集的精确度
val_accs_top5 = visualization_log['val_accs_top5'] # 验证集的精确度
epoch_iters = visualization_log['epoch_iters'] # 周期epoch迭代次数
batch_iters = visualization_log['batch_iters'] # 批次batch迭代次数
# 第一组坐标轴 Loss
_, ax1 = plt.subplots()
ax1.plot(batch_iters, train_losses, color='orange', linestyle='--', label='train_loss')
ax1.plot(epoch_iters, val_losses, color='cyan', linestyle='--', label='val_loss')
ax1.set_xlabel('Iters', fontsize=16)
ax1.set_ylabel('Loss', fontsize=16)
max_loss = max(max(train_losses), max(val_losses))
ax1.set_ylim(0, max_loss*1.2)
# 第二组坐标轴 accuracy
ax2 = ax1.twinx()
ax2.plot(epoch_iters, train_accs_top1, 'o-', color='red', markersize=3, label='train_accuracy(top1)')
ax2.plot(epoch_iters, val_accs_top1, 'o-', color='blue', markersize=3, label='val_accuracy(top1)')
if show_top5==True:
ax2.plot(epoch_iters, train_accs_top5, 'o-', color='magenta', markersize=3, label='train_accuracy(top5)')
ax2.plot(epoch_iters, val_accs_top5, 'o-', color='pink', markersize=3, label='val_accuracy(top5)')
ax2.set_ylabel('Accuracy', fontsize=16)
max_accs = max(max(train_accs_top1), max(train_accs_top5), max(val_accs_top1), max(val_accs_top5))
ax2.set_ylim(0, max_accs*1.2)
# 3.配置图例
plt.title('Training and Validation Results', fontsize=18)
handles1, labels1 = ax1.get_legend_handles_labels() # 图例1
handles2, labels2 = ax2.get_legend_handles_labels() # 图例2
plt.legend(handles1+handles2, labels1+labels2, loc='best')
plt.grid()
# 4.将绘图结果保存到 final_figures 目录
plt.savefig(os.path.join(figure_path, figurename + '.png'))
# 5.显示绘图结果
if isShow is True:
plt.show()
### 测试可视化函数 ###################################################
if __name__ == '__main__':
try:
log_file = json.loads(open(os.path.join(final_figures_path, 'visualization_log.json'), 'r', encoding='utf-8').read())
draw_process_ch6(log_file, show_top5=True)
except:
print('数据不存在,无法进行绘制')

【实验三】 模型训练与评估
实验摘要: 基于CNN的彩色图片识别是一种多分类问题,本项目使用CIFAR-10网络作为CNN模型对手势识别图片进行分类。实验二通过PaddlePaddle构造一个CIFAR10卷积神经的网络,最后一层采用Softmax激活函数完成分类任务。
实验目的:
- 掌握卷积神经网络的构建和基本原理
- 深刻理解训练集、验证集、训练验证集及测试集在模型训练中的作用
- 学会在线测试和离线测试两种测试方法
3.1 配置网络
3.1.1 网络拓扑结构图

3.1.2 网络参数配置表
Q3: 根据拓扑结构图补全网络参数配置表(10分)
| Layer | Input | Kernels_num | Kernels_size | Stride | Padding | PoolingType | Output | Parameters |
|---|---|---|---|---|---|---|---|---|
| Input | 3×32×32 | - | - | - | - | - | - | 3×32×32 |
| Conv1 | 3×32×32 | 32 | 3×5×5 | 1 | 0 | - | 32×28×28 | (3×5×5+1)×32=2432 |
| Pool1 | 32×28×28 | 32 | 32×2×2 | 2 | 0 | Max | 32×14×14 | 0 |
| Conv2 | 32×14×14 | 32 | 32×5×5 | 1 | 0 | - | 32×10×10 | (32×5×5+1)×32=25632 |
| Pool2 | 32×10×10 | 32 | 32×2×2 | 2 | 0 | Avg | 32×5×5 | 0 |
| Conv3 | 32×5×5 | 64 | 32×4×4 | 1 | 0 | - | 64×2×2 | (32×4×4+1)×64=32832 |
| Pool3 | 64×2×2 | 64 | 64×2×2 | 2 | 0 | Avg | 64×1×1 | 0 |
| FC1 | (64×1×1)×1- | - | - | - | - | - | 64×1 | (64+1)×64=4160 |
| FC2 | 64×1 | - | - | - | - | - | 64×10 | (64+1)×10=650 |
| Output | - | - | - | - | - | - | 10×1 | - |
| - | - | - | - | - | - | - | - | Total = 65706 |
3.1.3 定义神经网络类
Q4:根据Cifar10网络拓扑结构图和网络参数配置表完成神经Cifar10模型类定义(10分)([Your codes 8~10])
from paddle.nn import Sequential, Conv2D, MaxPool2D, AvgPool2D, Linear, Dropout, ReLU
# 定义多层感知机(CNN)
class Cifar10(paddle.nn.Layer):
def __init__(self, num_classes=10): # 初始化CIFAR类,并为CIFAR增加对象self.x
super(Cifar10, self).__init__()
# Q3-1: 根据Cifar10拓扑结构图和网络参数配置表完成下列Cifar10模型的类定义
# 各层超参数定义: [Your codes 8]
self.features = Sequential(
)
self.fc = Sequential(
Linear(in_features=64*1*1, out_features=64),
Linear(in_features=64, out_features=num_classes),
)
# Q3-2: 根据Cifar10拓扑结构图和网络参数配置表完成下列Cifar10模型的类定义
# 定义前向传输过程: [Your codes 8]
######输出网络结构和超参数########################################################
# 模型测试
if __name__ == '__main__':
# Q3-3:完成模型测试代码的定义
# [Your codes 10]
---------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===========================================================================
Conv2D-7 [[10, 3, 32, 32]] [10, 32, 28, 28] 2,432
ReLU-7 [[10, 32, 28, 28]] [10, 32, 28, 28] 0
MaxPool2D-3 [[10, 32, 28, 28]] [10, 32, 14, 14] 0
Conv2D-8 [[10, 32, 14, 14]] [10, 32, 10, 10] 25,632
ReLU-8 [[10, 32, 10, 10]] [10, 32, 10, 10] 0
AvgPool2D-5 [[10, 32, 10, 10]] [10, 32, 5, 5] 0
Conv2D-9 [[10, 32, 5, 5]] [10, 64, 2, 2] 32,832
ReLU-9 [[10, 64, 2, 2]] [10, 64, 2, 2] 0
AvgPool2D-6 [[10, 64, 2, 2]] [10, 64, 1, 1] 0
Linear-5 [[10, 64]] [10, 64] 4,160
Linear-6 [[10, 64]] [10, 10] 650
===========================================================================
Total params: 65,706
Trainable params: 65,706
Non-trainable params: 0
---------------------------------------------------------------------------
Input size (MB): 0.12
Forward/backward pass size (MB): 4.91
Params size (MB): 0.25
Estimated Total Size (MB): 5.27
---------------------------------------------------------------------------
3.2 模型训练及评估
3.2.1 定义测试函数
在飞桨2.0+的环境中,模型验证/测试使用 model.eval_batch() 方法实现,一般包含如下几个步骤:
- 定义输入数据的维度。输入数据的来源包含两种,一种是通过数据集类获取,此时不需要再次显示定义维度;一种是从外部获取数据,此时需要再次显示定义数据维度,Paddle中可以使用InputSpec来实现。图像输入维度 [None, channel, Width, Height],标签输入维度 [batch, 1],其中None用于匹配batch信息。
- 实例化模型,并载入参数。若需要输出损失值或评价指标,则还需要为模型配置损失函数和Metric函数。并且,模型需要以调优模式进行载入,而不是推理模型。
- 调用
model.eval_batch()方法,并载入[image]和[label]作为输入执行前向出传输。模型的输出为model.prepare()方法所指定的评价指标,一般包括损失值、top1和top5精度。 - 累加批次输出的结果,计算平均精度和平均损失。
此外,在定义eval()函数的时候,我们需要为其指定两个参数:model是测试的模型,data_reader是迭代的数据读取器,取值为val_reader(), test_reader(),分别对验证集和测试集。此处验证集和测试集数据的测试过程是相同的,只是所使用的数据不同。
from paddle.static import InputSpec
def eval(model, data_reader, verbose=0):
acc_top1 = []
acc_top5 = []
losses = []
n_total = 0
for batch_id, (image, label) in enumerate(data_reader):#测试集
n_batch = len(label)
n_total = n_total + n_batch
label = paddle.unsqueeze(label, axis=1) # 将图像转换为4D张量
loss, acc = model.eval_batch([image], [label])
losses.append(loss[0]*n_batch)
acc_top1.append(acc[0][0]*n_batch)
acc_top5.append(acc[0][1]*n_batch)
avg_loss = np.sum(losses)/n_total # loss 记录的是当前batch的累积值
avg_acc_top1 = np.sum(acc_top1)/n_total # metric 是当前batch的平均值
avg_acc_top5 = np.sum(acc_top5)/n_total
return avg_loss, avg_acc_top1, avg_acc_top5
##############################################################
if __name__ == '__main__':
try:
# 设置输入样本的维度
input_spec = InputSpec(shape=[None, img_size[2], img_size[0], img_size[1]], dtype='float32', name='image')
label_spec = InputSpec(shape=[None, 1], dtype='int64', name='label')
# 载入模型
network = Cifar10()
model = paddle.Model(network, input_spec, label_spec) # 模型实例化
model.load(final_models_path) # 载入调优模型的参数
model.prepare(loss=paddle.nn.CrossEntropyLoss(), # 设置loss
metrics=paddle.metric.Accuracy(topk=(1,5))) # 设置评价指标
# 执行评估函数,并输出验证集样本的损失和精度
print('开始评估...')
avg_loss, avg_acc_top1, avg_acc_top5 = eval(model, val_reader(), verbose=1)
print('\r [验证集] 损失: {:.5f}, top1精度:{:.5f}, top5精度为:{:.5f} \n'.format(avg_loss, avg_acc_top1, avg_acc_top5), end='')
avg_loss, avg_acc_top1, avg_acc_top5 = eval(model, test_reader(), verbose=1)
print('\r [测试集] 损失: {:.5f}, top1精度:{:.5f}, top5精度为:{:.5f}'.format(avg_loss, avg_acc_top1, avg_acc_top5), end='')
except:
print('数据不存在跳过测试')
开始评估...
[验证集] 损失: 0.00506, top1精度:0.90952, top5精度为:1.0000
[测试集] 损失: 0.00404, top1精度:0.93333, top5精度为:0.99286
3.2.2 定义训练函数
在飞桨2.0+中,动态图模式是默认模式,所有的训练和测试代码都需要基于动态图进行创建。由于是默认模式,因此不需要再像1.8版本中一样使用守护进程进行启用。
训练部分的具体流程,与验证部分大体相同,主要包括如下几个部分:
- 定义输入数据的维度。输入数据的来源包含两种,一种是通过数据集类获取,此时不需要再次显示定义维度;一种是从外部获取数据,此时需要再次显示定义数据维度,Paddle中可以使用InputSpec来实现。图像输入维度 [None, channel, Width, Height],标签输入维度 [batch, 1],其中None用于匹配batch信息。
- 实例化模型,并载入参数。在训练中除了损失函数和Metric函数是必须定义的,还需要定义优化器算法。此时,我们可以通过
model.prepare()实现定义。 - 调用
model.train_batch()方法,并载入[image]和[label]作为输入执行前向出传输。在飞桨2.0+中,反向求导部分不需要进行显示定义,train_batch()会自动执行。 - 累加批次输出的结果,计算平均精度和平均损失。
此外,在训练过程中,我们可以每个一定的周期调用一次验证函数 eval(),来对验证集进行测试。一般来说,每个epoch都可以进行一次验证。另外,可视化也训练和验证的loss和accuracy也是训练中常用的模型选择方法。在训练过程中,可以将周期,批次,损失及精度等信息打印到屏幕。
在本项目中,我们在训练中,每100个batch之后会输出一次平均训练误差和准确率;每一轮训练之后,使用测试集进行一次测试,在每轮测试中,均打输出一次平均测试误差和准确率。
【注意】注意在下列的代码中,我们每个epoch都会判断当前的模型是否是最优模型,如果是最优模型,我们会进行一次模型保存,并将其名命名为 best_model。对于复杂的模型和大型数据集上,我们通常还会在每个周期训练结束后都保存一个 checkpoint_model。这种经常性的模型保存,有利于我们执行EarlyStopping策略,并回退到任意一个时间节点。也便于当我们发现运行曲线不再继续收敛时,就可以结束训练。
Q5. 完成下列模型训练函数的主体部分(20分) ([Your codes 11~13])
from paddle.static import InputSpec
import paddle.optimizer as optimizer
# 初始化绘图列表
visualization_log = { # 初始化状态字典
'train_losses': [], # 训练损失值
'train_accs_top1': [], # 训练top1精度
'train_accs_top5': [], # 训练top5精度
'val_losses': [], # 验证损失值
'val_accs_top1': [], # 验证top1精度
'val_accs_top5': [], # 验证top5精度
'batch_iters': [], # 批次batch迭代次数
'epoch_iters': [], # 周期epoch迭代次数
}
def train(model):
print('启动训练...')
start = time.perf_counter()
num_batch = 0
best_result = 0
best_result_id = 0
elapsed =0
for epoch in range(1, total_epoch+1):
for batch_id, (image, label) in enumerate(train_reader()):
num_batch += 1
# Q5-1. 调用model.train_batch方法进行训练,注意需要对label的尺度进行规范化
# [Your codes 11]
if num_batch % log_interval == 0: # 每10个batch显示一次日志,适合大数据集
# Q5-2. 从训练的输出中获取损失值,top1精度和top5精度
# [Your codes 12]
elapsed_step = time.perf_counter() - elapsed - start
elapsed = time.perf_counter() - start
print('Epoch:{}/{}, batch:{}, train_loss:[{:.5f}], acc_top1:[{:.5f}], acc_top5:[{:.5f}]({:.2f}s)'
.format(epoch, total_epoch, num_batch, loss[0], acc[0][0], acc[0][1], elapsed_step))
# 记录训练过程,用于可视化训练过程中的loss和accuracy
visualization_log['train_losses'].append(float(avg_loss))
visualization_log['batch_iters'].append(num_batch)
# 每隔一定周期进行一次测试
if epoch % eval_interval == 0 or epoch == total_epoch:
# 模型校验
val_loss, val_acc_top1, val_acc_top5 = eval(model, val_reader())
print('[validation] Epoch:{}/{}, val_loss:[{:.5f}], val_top1:[{:.5f}], val_top5:[{:.5f}]'.format(epoch, total_epoch, val_loss, val_acc_top1, val_acc_top5))
# 记录测试过程,用于可视化训练过程中的loss和accuracy
visualization_log['epoch_iters'].append(num_batch)
visualization_log['train_accs_top1'].append(float(acc_top1))
visualization_log['train_accs_top5'].append(float(acc_top5))
visualization_log['val_losses'].append(float(val_loss))
visualization_log['val_accs_top1'].append(float(val_acc_top1))
visualization_log['val_accs_top5'].append(float(val_acc_top5))
# Q5-3. 将性能最好的模型保存为final模型,注意同时保存调优模型和推理模型
# model.save(<path>, training=False|True),True:调优模型 | False:推理模型
# [Your codes 13]
# 输出训练过程数据,将日志字典保存为json格式,绘图数据可以在训练结束后自动显示,也可以在训练中手动执行以显示结果
if not os.path.exists(final_figures_path):
os.makedirs(final_figures_path)
with codecs.open(os.path.join(final_figures_path, 'visualization_log.json'), 'w', encoding='utf-8') as f_log:
json.dump(visualization_log, f_log, ensure_ascii=False, indent=4, separators=(',', ':'))
print('训练完成,最终性能accuracy={:.5f}(epoch={}), 总耗时{:.2f}s, 已将其保存为:best_model'.format(best_result, best_result_id, time.perf_counter() - start))
3.2.3 训练主函数
Q6. 完成主函数的定义(10分) ([Your codes 14])
要求:
1. 对Cifar10模型进行实例化
2. 执行训练函数
import paddle.optimizer as optimizer
#### 训练主函数 ########################################################3
if __name__ == '__main__':
# [Your codes 14]
# 1. 设置输入样本的维度
input_spec =
label_spec =
# # 2. 载入设计好的网络,并实例化model变量
network =
model =
# 3. 设置学习率、优化器、损失函数和评价指标
# optimizer = optimizer.Momentum(learning_rate=learning_rate, momentum=momentum, parameters=model.parameters())
optimizer =
# 4. 启动训练过程
print('训练完毕,结果路径{}.'.format(result_root_path))
# 5. 输出训练过程图
draw_process_ch6(visualization_log)
启动训练...
Epoch:1/20, batch:10, train_loss:[2.34113], acc_top1:[0.12500], acc_top5:[0.42188](4.98s)
Epoch:1/20, batch:20, train_loss:[2.28099], acc_top1:[0.23438], acc_top5:[0.56250](5.30s)
[validation] Epoch:1/20, val_loss:[2.29014], val_top1:[0.16190], val_top5:[0.50000]
Epoch:2/20, batch:30, train_loss:[2.27073], acc_top1:[0.17188], acc_top5:[0.67188](1.70s)
Epoch:2/20, batch:40, train_loss:[2.22113], acc_top1:[0.39062], acc_top5:[0.75000](0.44s)
[validation] Epoch:2/20, val_loss:[2.20791], val_top1:[0.18095], val_top5:[0.69524]
Epoch:3/20, batch:50, train_loss:[2.17924], acc_top1:[0.26562], acc_top5:[0.73438](0.51s)
Epoch:3/20, batch:60, train_loss:[1.96632], acc_top1:[0.29688], acc_top5:[0.84375](0.17s)
[validation] Epoch:3/20, val_loss:[1.91257], val_top1:[0.35238], val_top5:[0.84762]
Epoch:4/20, batch:70, train_loss:[1.94465], acc_top1:[0.32812], acc_top5:[0.73438](0.38s)
Epoch:4/20, batch:80, train_loss:[1.78853], acc_top1:[0.40625], acc_top5:[0.82812](0.27s)
[validation] Epoch:4/20, val_loss:[1.63450], val_top1:[0.44286], val_top5:[0.90000]
Epoch:5/20, batch:90, train_loss:[1.76625], acc_top1:[0.35938], acc_top5:[0.90625](0.48s)
Epoch:5/20, batch:100, train_loss:[1.52346], acc_top1:[0.45312], acc_top5:[0.92188](0.37s)
Epoch:5/20, batch:110, train_loss:[1.48752], acc_top1:[0.54688], acc_top5:[0.96875](0.30s)
[validation] Epoch:5/20, val_loss:[1.31831], val_top1:[0.60000], val_top5:[0.93333]
Epoch:6/20, batch:120, train_loss:[1.17448], acc_top1:[0.65625], acc_top5:[0.96875](0.37s)
Epoch:6/20, batch:130, train_loss:[1.26488], acc_top1:[0.59375], acc_top5:[0.96875](0.51s)
[validation] Epoch:6/20, val_loss:[1.19671], val_top1:[0.58571], val_top5:[0.93810]
Epoch:7/20, batch:140, train_loss:[0.97217], acc_top1:[0.64062], acc_top5:[0.98438](0.37s)
Epoch:7/20, batch:150, train_loss:[1.21293], acc_top1:[0.51562], acc_top5:[1.00000](0.41s)
[validation] Epoch:7/20, val_loss:[1.00827], val_top1:[0.64286], val_top5:[0.95714]
Epoch:8/20, batch:160, train_loss:[0.77509], acc_top1:[0.78125], acc_top5:[0.98438](0.33s)
Epoch:8/20, batch:170, train_loss:[0.88844], acc_top1:[0.62500], acc_top5:[0.96875](0.52s)
[validation] Epoch:8/20, val_loss:[0.89138], val_top1:[0.73810], val_top5:[0.97143]
Epoch:9/20, batch:180, train_loss:[0.86490], acc_top1:[0.65625], acc_top5:[1.00000](0.32s)
Epoch:9/20, batch:190, train_loss:[0.83492], acc_top1:[0.68750], acc_top5:[1.00000](0.41s)
[validation] Epoch:9/20, val_loss:[0.76048], val_top1:[0.75714], val_top5:[0.97619]
Epoch:10/20, batch:200, train_loss:[0.62832], acc_top1:[0.85938], acc_top5:[0.98438](0.42s)
Epoch:10/20, batch:210, train_loss:[0.41041], acc_top1:[0.89062], acc_top5:[1.00000](0.31s)
Epoch:10/20, batch:220, train_loss:[0.61866], acc_top1:[0.84375], acc_top5:[0.96875](0.41s)
[validation] Epoch:10/20, val_loss:[0.73755], val_top1:[0.77619], val_top5:[0.97143]
Epoch:11/20, batch:230, train_loss:[0.78192], acc_top1:[0.68750], acc_top5:[1.00000](0.43s)
Epoch:11/20, batch:240, train_loss:[0.51627], acc_top1:[0.85938], acc_top5:[0.96875](0.41s)
[validation] Epoch:11/20, val_loss:[0.66870], val_top1:[0.78571], val_top5:[0.97619]
Epoch:12/20, batch:250, train_loss:[0.45307], acc_top1:[0.87500], acc_top5:[0.98438](0.32s)
Epoch:12/20, batch:260, train_loss:[0.54342], acc_top1:[0.84375], acc_top5:[1.00000](0.31s)
[validation] Epoch:12/20, val_loss:[0.61597], val_top1:[0.79048], val_top5:[0.97143]
Epoch:13/20, batch:270, train_loss:[0.75462], acc_top1:[0.71875], acc_top5:[0.98438](0.62s)
Epoch:13/20, batch:280, train_loss:[0.37084], acc_top1:[0.87500], acc_top5:[1.00000](0.21s)
[validation] Epoch:13/20, val_loss:[0.57569], val_top1:[0.84286], val_top5:[0.97619]
Epoch:14/20, batch:290, train_loss:[0.61580], acc_top1:[0.81250], acc_top5:[0.98438](0.52s)
Epoch:14/20, batch:300, train_loss:[0.51743], acc_top1:[0.81250], acc_top5:[1.00000](0.50s)
[validation] Epoch:14/20, val_loss:[0.59291], val_top1:[0.79048], val_top5:[0.97619]
Epoch:15/20, batch:310, train_loss:[0.52604], acc_top1:[0.84375], acc_top5:[0.96875](0.26s)
Epoch:15/20, batch:320, train_loss:[0.38679], acc_top1:[0.90625], acc_top5:[1.00000](0.20s)
Epoch:15/20, batch:330, train_loss:[0.35038], acc_top1:[0.85938], acc_top5:[1.00000](0.51s)
[validation] Epoch:15/20, val_loss:[0.57616], val_top1:[0.80000], val_top5:[0.98571]
Epoch:16/20, batch:340, train_loss:[0.34495], acc_top1:[0.87500], acc_top5:[1.00000](0.28s)
Epoch:16/20, batch:350, train_loss:[0.34320], acc_top1:[0.89062], acc_top5:[1.00000](0.50s)
[validation] Epoch:16/20, val_loss:[0.62722], val_top1:[0.80000], val_top5:[0.98095]
Epoch:17/20, batch:360, train_loss:[0.47768], acc_top1:[0.84375], acc_top5:[0.98438](0.47s)
Epoch:17/20, batch:370, train_loss:[0.30824], acc_top1:[0.89062], acc_top5:[1.00000](0.31s)
[validation] Epoch:17/20, val_loss:[0.52038], val_top1:[0.83810], val_top5:[0.99048]
Epoch:18/20, batch:380, train_loss:[0.22572], acc_top1:[0.98438], acc_top5:[1.00000](0.27s)
Epoch:18/20, batch:390, train_loss:[0.22397], acc_top1:[0.96875], acc_top5:[1.00000](0.41s)
[validation] Epoch:18/20, val_loss:[0.45530], val_top1:[0.85238], val_top5:[0.99048]
Epoch:19/20, batch:400, train_loss:[0.38200], acc_top1:[0.85938], acc_top5:[1.00000](0.41s)
Epoch:19/20, batch:410, train_loss:[0.23595], acc_top1:[0.93750], acc_top5:[1.00000](0.41s)
[validation] Epoch:19/20, val_loss:[0.48755], val_top1:[0.84286], val_top5:[0.99524]
Epoch:20/20, batch:420, train_loss:[0.21530], acc_top1:[0.95312], acc_top5:[1.00000](0.47s)
Epoch:20/20, batch:430, train_loss:[0.30855], acc_top1:[0.87500], acc_top5:[0.98438](0.41s)
Epoch:20/20, batch:440, train_loss:[0.24997], acc_top1:[0.93750], acc_top5:[1.00000](0.20s)
[validation] Epoch:20/20, val_loss:[0.44147], val_top1:[0.87619], val_top5:[0.98095]
训练完成,最终性能accuracy=0.87619(epoch=20), 总耗时27.79s, 已将其保存为:best_model
训练完毕,结果路径D:\Workspace\ExpResults\Project025CNNGestures.
3.2.4 离线测试
离线测试与验证几乎相同,直接调用 eval() 方法即可,唯一的区别是离线测试通常是先读取保存的模型,再进行测试。
Q7. 完成离线测试的模型载入代码(10分) ([Your codes 15])
# [Your codes 15]
# 1. 设置输入样本的维度
input_spec =
label_spec =
# 2. 载入模型
# 3. 执行评估函数,并输出验证集样本的损失和精度
print('开始评估...')
print('\r [验证集] 损失: {:.5f}, top1精度:{:.5f}, top5精度为:{:.5f} \n'.format(avg_loss, avg_acc_top1, avg_acc_top5), end='')
print('\r [测试集] 损失: {:.5f}, top1精度:{:.5f}, top5精度为:{:.5f}'.format(avg_loss, avg_acc_top1, avg_acc_top5), end='')
开始评估...
[验证集] 损失: 0.00506, top1精度:0.90952, top5精度为:1.00000
[测试集] 损失: 0.00404, top1精度:0.93333, top5精度为:0.99286
结果分析
需要注意的是此处的精度与训练过程中输出的测试精度是不相同的,因为训练过程中使用的是验证集, 而这里的离线测试使用的是测试集.
【实验四】 模型预测(应用)
实验摘要: 对训练过的模型,使用测试数据进行推理和评估,查看模型的效果。
实验目的:
- 掌握模型推理和应用
- 能够根据任务设计代码逻辑
Q8:使用训练好的模型对给定的车牌进行预测,尽力而为地获得最优的预测结果(20分)([Your codes 16~18])
4.1 导入依赖库及全局参数配置
# 导入依赖库
import os
import cv2
import json
import numpy as np
import paddle # 载入PaddlePaddle基本库
import matplotlib.pyplot as plt # 载入python的第三方图像处理库
import paddle.vision.transforms as T
# Q8-1:定义全局路径,包括项目名称、结果路径、模型路径等
# [Your codes 16]
project_name =
dataset_name =
architecture =
img_size =
result_root_path =
final_models_path =
4.2 获取待预测数据及数据预处理
在预测之前,通常需要对图像进行预处理。此处的预处理包含两部分,一部分是常规的预处理,一部分是针对数据集的特殊预处理。
- 常规预处理包括将每个字符进行二次预处理,包括缩放至训练样本的尺度(20×20),数据格式规范为paddle要求的浮点型数据,且形态为[C,H,W],数值归一化到[0~1] 等操作,这部分操作,要求和训练时的预处理方案,完全一致。我们使用函数
load_image()进行定义。 - 针对数据集的特殊预处理。此处也包括两个步骤:
1). 将所有样本转换为灰度图,并通过阈值变换将其转换为二值图像。其中黑色部分为背景,白色部分为字符,函数color2bin()对该功能进行定义。
2). 将二值图像按照字符进行分割,每个字符构成一个子文件。本例中使用比较粗糙的方法(等间隔)进行拆分,函数Segmentation()对该功能进行定义。有兴趣的同学可以扩展该函数,以实现更好的字符分割。
值得注意的是,二值化灰度图有利于提高系统的识别性能,是灰度图像预处理的一个重要步骤,在允许的情况下,尽量执行该操作。但选择二值分割阈值是一件经验性的数据驱动型工作,需要慎重选择。
# Q8-2:定义数据读取函数,包括读入数据,将数据转换为float32,尺度规范为[20,20],格式转换为Tesnsor并转置为4D形态
# [Your codes 17]
def load_image(img_path):
return img
4.3 载入模型并开始进行推理
Q7. 完成模型推理的代码(10分) ([Your codes 8])
要求:
1. 对 cifar10 进行实例化
2. 载入保存的模型参数
3. 设置模型运行模式为评估模式
4. 载入样本,并进行预处理
5. 将处理后的样本进行前向传输,输出结果
### Q8-3: 载入模型并实现手势识别预测
# [Your codes 18]
import random
i = random.randint(0,9)
img_path = 'D:\\Workspace\\ExpDatasets\\Gestures\\Infer\\infer_' + str(i) + '.jpg' # 从预先准备的推理图像文件中随机抽取一幅图像,该文件夹中包含0-9共10个示例图片
# 1. 载入模型并进行实例化
model = # 载入推理模型
# 2. 载入待预测图像
img = # 载入图像,并对图像进行一定的预处理
# 3. 预测并输出结果
logits = )
pred =
print('手势文件 {} 的标签为: {}, 预测结果为: {}'.format(os.path.basename(img_path), os.path.basename(img_path)[-5], pred))
# 4. 输出图像文件
image =
image =
plt.imshow(image)
手势文件 infer_0.jpg 的标签为: 0, 预测结果为: 0
<matplotlib.image.AxesImage at 0x22b6ea61040>

【实验五】 扩展应用——真实世界的手势识别
实验摘要: 使用训练好的模型对真实世界(摄像头拍摄)的手势进行推理和验证。
实验目的:
- 掌握模型推理和应用
- 能够根据任务设计代码逻辑
- 尝试对真实场景数据进行获取和使用的方法
实验建议:
- 实验的基本流程大体上和实验四是相同,但推理部分编写为predict()函数方便调用
- 单独撰写一个数据采集和预测的主函数,以获摄像头的照片采集结果
5.1 导入依赖库和全局参数
# 导入依赖库
import os
import cv2
import json
import numpy as np
import paddle # 载入PaddlePaddle基本库
import matplotlib.pyplot as plt # 载入python的第三方图像处理库
import paddle.vision.transforms as T
project_name =
dataset_name =
architecture =
img_size =
result_root_path =
final_models_path =
5.2 数据预处理
数据预处理应该和训练过程完全一致,包括图像尺度的缩放,数据格式转换和像素值归一化。此外,为了匹配Paddle框架,还需要将数据转换为4D的Tensor形态。
#读取预测图像并进行预处理
def load_image(img):
return img
5.3 定义预测函数
def predict(image, model_path = final_models_path):
#构建预测动态图过程
model =
# 输出测评结果
img =
logits =
pred =
print('手势文件的预测结果为: {}'.format(pred))
image =
plt.imshow(image)
5.4 调用摄像头,并生成预测结果
import cv2
# 1. 打开摄像头
cap = cv2.VideoCapture(0)
# 2. 执行数据采取并进行预测
while(1):
# 2.1 开启摄像头,并获取数据流
ret, frame = cap.read()
# 2.2 摄像头获取的帧,载入到opencv窗口
cv2.imshow("capture", frame)
# 2.3 根据键盘指示,获取数据流中的一帧
if cv2.waitKey(1) & 0xFF == ord('q'): # 如果按下 q 就截图保存并调用预测函数进行预测
predict(frame)
break
# 3. 释放摄像头
cap.release() # 释放摄像头
cv2.destroyAllWindows() # 关闭数据采集窗口
手势文件的预测结果为: 8

注意
在真实场景拍摄的时候,由于本项目并没有做分割、过多的图像预处理和图像增广,因此对场景和样本的要求较高:
- 背景尽量干净,最好是纯白色背景;
- 手势的拍摄尽量光线充足,若光线不足,可使用手机/手电进行补光;
- 由于Gestures数据集是右手数据集,因此拍摄时请使用右手进行拍摄。若需要使用左手拍摄,请取消
load_image()函数中的T.RandomHorizontalFlip(1),的注释,实现手动水平翻转。