【项目024】基于前馈神经网络的手写字体识别(静态图)
作者:欧新宇(Xinyu OU)
开发平台:Paddle 2.1
运行环境:Intel Core i7-7700K CPU 4.2GHz, nVidia GeForce GTX 1080 Ti
特别注意:本案例使用Paddle 2.1进行开发,但所使用的静态图库函数为Paddle 1.8,这些API将在未来的版本中被废弃。
特别注意:鉴于Paddle推荐使用动态图模式,本项目于此次更新后停止更新。
本教案所涉及的数据集仅用于教学和交流使用,请勿用作商用。
最后更新:2021年8月12日
【实验目的】
- 熟悉神经网络的基本结构,包括层(输入、输出、隐层)、损失函数、激活函数、优化方法等
- 学会使用mini-batch方法实现深度神经网络的训练并进行预测
- 学会保存模型,并使用保存的模型进行预测(即应用模型到生产环境)
- 学会使用PaddlePaddle构建多层感知机
- 学会使用静态图模式Static设计和训练神经网络
PS: 查看显卡利用率
- 打开命令提示行, 并进入文件夹: C:\Program Files\NVIDIA Corporation\NVSMI
- 执行命令: nvidia-smi, 观察Memory-Usage的值. 例如: 1857MiB / 11264MiB, 前者表示当前正在使用的显存量, 后者表示显卡总显存量.
【实验一】 数据准备
实验目的:
- 理解训练集、验证集、训练验证集及测试集在模型训练中的作用
- 学会图像列表的构建和数据读取器的定义
- 学会图像的基本预处理方法,包括尺寸缩放、归一化和格式规范
- 学会切换CPU和GPU两种训练模式
1.0 导入依赖及全局参数设置
在Paddle 2.0版本之后,动态图成为默认工作模式,因此需要使用静态图进行训练时,需要使用paddle.enable_static()手动设置Paddle的工作模式为静态图。
# 1. 导入依赖库 import os import cv2 import time from random import randint # 导入随机数生成函数 import numpy as np import matplotlib.pyplot as plt import paddle import paddle.fluid as fluid from paddle.fluid.dygraph import Linear from multiprocessing import cpu_count paddle.enable_static() # 设置Paddle工作模式为静态图模式 # 2. 全局参数配置 # 定义使用CPU还是GPU,使用CPU时use_cuda = False,使用GPU时use_cuda = True use_cuda = True # True, False 如果设备有GPU,怎么我们可以启用GPU进行快速训练 PLACE = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace() # 定义数据集列表文件路径 dataset_name = 'MNIST' architecture = 'MLP' result_root_path = 'D:\\Workspace\\ExpResults\\' final_models_path = os.path.join(result_root_path, 'Project02FeedforwardNetworkStatic', dataset_name + '_' + architecture) # 定义训练参数 total_epoch = 10 # 迭代次数, 代码调试好后考虑Epochs_num = 500-600 eval_interval = 1 # 设置在训练过程中,每隔一定的周期进行一次测试 log_interval = 100 # 训练日志显示间隔 learning_rate = 0.01 # 学习率 # 定义输出参数 np.set_printoptions(precision=5, suppress=True) # 设置numpy的精度,用于打印输出
1.1 数据准备
1.1.1 数据集简介
MNIST数据集包含60000个训练集和10000测试数据集。分为图片和标签,图片是28*28的像素矩阵,标签为0~9共10个数字。
1.1.2 观察和展示数据
该步骤是非必须的必要步骤。非必须指它并不是训练和展示数据所必须的步骤;必要步骤是因为观察数据集有利于我们更好地选择合适的方法进行数据预处理。
和很多基础数据集一样,mnist数据集已经是paddlepaddle的内置数据集,所以可以通过 paddle.dataset.mnist.train()类来直接获取train_data训练数据集。
此外,我们还可以使用next(train_data())来顺序遍历train_data中的数据并保存到样例数据变量sampledata中。该数据包含两个元素,可以直接使用image,label=sampledata来获取. 之后,可以考虑输入image和label,以及他们的形态来对其进行观察。
# 用于打印,查看mnist数据,数据以元组tuple类型进行保存 train_data = paddle.dataset.mnist.train() sampledata = next(train_data()) image, label = sampledata print('样本数据维度为: {}, 数据类型为: {}'.format(len(sampledata), type(sampledata))) print('图像维度为:{}'.format(image.shape)) print('图像标签为:{}'.format(label))
样本数据维度为: 2, 数据类型为:
<class 'tuple'>
图像维度为:(784,)
图像标签为:5
1.1.3 定义数据读取器获取数据
由于MNIST是paddle内置的toy数据集,因此可以使用paddle.dataset.mnist.train()和paddle.dataset.mnist.test()从直接从库中获取数量为BATCH_SIZE的数据,该接口在载入数据的同时,实现了对样本的灰度化、归一化和居中等预处理。以下为关键函数介绍:
image_reader = paddle.batch(paddle.reader.shuffle([dataset|reader=data_reader(data_list)], buf_size={Int}), batch_size=[Int], drop_last=[True|False]) # paddle.dataset.mnist.train()和test():分别用于获取mnist训练集和测试集 # paddle.reader.shuffle():表示每次缓存BUF_SIZE个数据项,并进行打乱。适当载入缓存,有利于提高数据读取的速度。 # paddle.batch():表示每BATCH_SIZE组成一个batch # drop_last: 用于设置在分配batch时,最后一个批量和前面数量不同的时候,是否丢弃
BUF_SIZE = 256 # 设置存储数据的缓存大小 BATCH_SIZE = 128 # 设置每个批次的数据大小,同时对训练提供器和测试提供器有效 # 用于训练/测试的数据提供器,每次从缓存中随机读取批次大小的数据 train_reader = paddle.batch(paddle.reader.shuffle(paddle.dataset.mnist.train(), buf_size=BUF_SIZE), batch_size=BATCH_SIZE, drop_last=False) test_reader = paddle.batch(paddle.reader.shuffle(paddle.dataset.mnist.test(), buf_size=BUF_SIZE), batch_size=BATCH_SIZE, drop_last=False)
第一次运行以上代码,会自动去下载mnist数据集,提示信息如下:
Cache file C:\Users\Administrator\.cache\paddle\dataset\mnist\t10k-images-idx3-ubyte.gz not found, downloading https://dataset.bj.bcebos.com/mnist/t10k-images-idx3-ubyte.gz
Begin to download
Download finished
Cache file C:\Users\Administrator\.cache\paddle\dataset\mnist\t10k-labels-idx1-ubyte.gz not found, downloading https://dataset.bj.bcebos.com/mnist/t10k-labels-idx1-ubyte.gz
Begin to download
..
Download finished
# 测试:输出第0个batch的数据形态 for batch_id, data in enumerate(train_reader()): print(data[0][0].shape) break
(784,)
【实验二】 模型配置和训练
实验目的:
- 理解训练集、验证集、训练验证集及测试集在模型训练中的作用
- 掌握基于静态图的前馈神经网络的构建、训练方法
- 学会可视化训练过程
- 学会在线测试和离线测试两种方法
2.1 配置网络
在Paddle的静态图模式中,深度神经网络的配置主要包括以下几个方面:
- 网络结构的定义
- 输入层的定义
- 分类器及损失函数、准确率函数的定义
- 优化方法的定义
- Exector执行器定义
2.1.1 网络结构的定义
在本范例中使用一个4层的前馈神经网络(多层感知机)对MNIST数据集进行建模。其中第一层为输入层,后面紧跟两个大小为100的隐层和一个大小为10的输出层。其中,输出层的每个神经元对应于MNIST的类别数,即0-9的10个数字。最后使用交叉熵函数求损失,并用Softmax分类器输出类别。
- 输入层:MNIST数据集中的每个样本都为分辨率为像素的二维图片,根据前馈神经网络的结构,需要将其拉伸为784维的向量,即。
+1代表该层的偏置参数,值为1。 - 隐藏层:100个节点的全连接层,激活函数为ReLU。
- 隐藏层:100个节点的全连接层,激活函数为ReLU。
- 输出层:10个节点的全连接层,对应于MNIST数据集的10个类别。所有的输出节点组成一个N=10维的向量,经过Softmax分类器后,将归一化为N个的实数,其值为该样本属于这N个类别的概率,并且有,即所有类别概率的和为1。
以下为该前馈神经网络(多层感知机)的网络构建函数。
def model_name(input): # 函数的输入input,一般来说表示的是样本的张量,例如image # 以下可以逐层定义模型,对于前馈神经网络来说,只有一种层类型,全连接层,使用如下方式定义 # input: 定义层的输入 # size: 神经元的数量 # act: 激活函数 [layer_name] = fluid.layers.fc(input=[input], size=[int], act=[relu|sigmoid|linear]) return the_last_layer # 函数的返回值,通常为最后一个层的名字
# 定义多层感知机(MLP) def MLP(input): # 第一个全连接层,激活函数为ReLU hidden1 = fluid.layers.fc(input=input, size=100, act='relu') # 第二个全连接层,激活函数为ReLU hidden2 = fluid.layers.fc(input=hidden1, size=100, act='relu') # 以softmax为激活函数的全连接输出层,输出层的大小必须为数字的个数10 digits = fluid.layers.fc(input=hidden2, size=10) return digits
2.1.2 输入层的定义
在本例中,我们输入的是图像数据,因此每个图像I都是一个元组,包含图像和标签,。其中,图像是的灰度图,所以输入的形状是,如果图像是的彩色图,那么输入的形状是,因为灰度图只有一个通道,而彩色图有RGB三个通道。此外,理论上还应该有一个维度表示BatchSize,但在Paddle中,已经封装到训练过程中,因此,此处只需要关注样本本身的维度。对于标签label,它是一个一维的标量,对应于图像的类别。与图像类似,它默认也有一个BatchSize的维度被包含在训练过程中。
下面的代码主要包含三部分,定义样本、标签,以及数据提供器的feeder。
- 首先,使用
fluid.layers.data()分别定义image和label,其中image是形态为[1,28,28]的3D浮点型数据, labels是一个一维的int64整型标量 - 接下来,将设备,输入数据列表组合在一起作为输入的feeder
[image|label] = fluid.layers.data(name='image|label', shape=[数据的形态],dtype=['float32'|'int64']) feeder = fluid.DataFeeder(place=PLACE, feed_lisit=[image, label])
# 输入的原始图像数据,大小为1*28*28 image = fluid.layers.data(name='image', shape=[1, 28, 28], dtype='float32') #单通道,28*28像素值,使用32bit的浮点型数据进行保存 label = fluid.layers.data(name='label', shape=[1], dtype='int64') #图片标签,对应输入图片的类别标签,使用整型数据保存 # 定义前向传播时的输入,包括数据和设备,其中数据又feed_list进行定义,设备由place进行定义 feeder = fluid.DataFeeder(place=PLACE, feed_list=[image, label]) # 定义数据的维度
2.1.3 分类器及损失函数、准确率函数的定义
- 首先创建一个分类器,例如此处的多层感知机(前馈神经网络),简单的说是将模型类实例化。
- 使用分类任务中经常用到的交叉熵损失函数
fluid.layers.cross_entropy(),其损失由模型的输出input=predict和真实的标签label=[]计算获得。由于该损失函数是针对整个Batch的,因此还需要对其求平均值才能获得模型的损失(相当于单个样本的损失),求损失的基本思路是Loss=总损失TotalLoss/批大小BatchSize。此处可以直接调用Paddle的函数fluid.layers.mean(loss)。 - 最后,还可以定义一个准确率函数
fluid.layers.accuracy(),用于衡量训练时输出分类的准确率,其输入依然是模型的输出input=predict和真实的标签label=[]。
# 定义输出层 loss+accuracy # 预测结果 = softmax(预测概率),模型的输出是预测概率 # 损失loss = cross_entropy(预测结果 与 label 之间的距离) # 精度acc = accuracy(预测结果 与 label之间的距离) digits = MLP(image) # 输出率,输入针对每个类别的评分 predict = fluid.layers.softmax(digits) # 预测结果 = softmax(输出概率) loss = fluid.layers.cross_entropy(input=predict, label=label) avg_loss = fluid.layers.mean(loss)#获取loss值 acc = fluid.layers.accuracy(input=predict, label=label)#计算精度
2.1.4 优化方法的定义
定义优化方法,此处使用一种常用的优化方法——Adam优化方法,同时指定学习率为0.001.
# 定义训练及测试程序 train_program = fluid.default_main_program() test_program = fluid.default_main_program().clone(for_test=True) # 定义优化函数Adam对梯度进行优化,learning_rate为学习率,它影响网络训练的收敛速度 optimizer = fluid.optimizer.AdamOptimizer(learning_rate=learning_rate) opts = optimizer.minimize(avg_loss)
在上述模型配置完毕后,得到三个fluid.Program:fluid.default_startup_program(),fluid.default_main_program(),及test_program。
- 所有的参数初始化操作都会被写入fluid.default_startup_program()
- fluid.default_main_program()用于获取默认或全局main program(主程序)。该主程序用于训练和测试模型。fluid.layers 中的所有layer函数可以向 default_main_program 中添加算子和变量。default_main_program 是fluid的许多编程接口(API)的Program参数的缺省值。例如,当用户program没有传入的时候,Executor.run() 会默认执行 default_main_program。
- fluid.defult_main_program有一个默认参数for_test=False,当其处于默认值False时,fluid.default_main_program用于训练,当其处于True时,fluid.default_main_program用于测试。此处,使用fluid.default_main_program().clone()操作实现了对初始配置的完全克隆。
之后需要定义一个优化器,并使用最小化的方式,依据平均损失进行优化,并得到输出:
optimizer = fluid.optimizer.优化器方法(learning_rate=[int]) opts = optimizer.minimize(avg_cost)
其中optimizer能调用的优化器非常多,常见的包括Adam, Momentum, SGD, Adagrad等。具体可以参考paddle官网,fluid.optimizer
2.1.5 Executor执行器的定义
首先定义执行训练的设备,默认情况下Paddle支持CPU和GPU两种模式。当设置fluid.CPUPlace()和 fluid.CUDAPlace(0)时,分别表示调用CPU和GPU进行训练。下面通过设置是否使用cuda来进行自动判断,并将设备信息保存到全局变量PLACE中. Executor接收传入的program,通过run()方法运行program。
use_cuda = True # True, False 如果设备有GPU,怎么我们可以启用GPU进行快速训练 PLACE = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
exe = fluid.Executor(PLACE) exe.run(fluid.default_startup_program())
2.2 定义过程可视化函数
定义训练过程中用到的可视化方法, 包括训练损失, 训练集批准确率, 测试集准确率. 根据具体的需求,可以在训练后展示这些数据和迭代次数的关系. 值得注意的是, 训练过程中可以每个epoch绘制一个数据点,也可以每个batch绘制一个数据点,也可以每隔n个batch或n个epoch绘制一个数据点.
# 绘制训练batch精度和平均loss def draw_process(title, loss_label, accuracy_label, iters, losses, accuracies): # 第一组坐标轴 Loss _, ax1 = plt.subplots() # plt.subplots(figsize=(14,6)) ax1.plot(iters, losses, color='red', label=loss_label) ax1.set_xlabel('Iters', fontsize=20) ax1.set_ylabel(loss_label, fontsize=20) max_loss = max(losses) ax1.set_ylim(0, max_loss*1.2) # 第二组坐标轴 accuracy ax2 = ax1.twinx() ax2.plot(iters, accuracies, color='blue', label=accuracy_label) ax2.set_ylabel(accuracy_label, fontsize=20) max_acc = max(accuracies) ax2.set_ylim(0, max_acc*1.2) plt.title(title, fontsize=24) # 图例 handles1, labels1 = ax1.get_legend_handles_labels() handles2, labels2 = ax2.get_legend_handles_labels() plt.legend(handles1+handles2, labels1+labels2, loc='best') plt.grid()
2.3 模型训练及评估
训练需要有一个训练程序和一些必要参数,并构建了一个获取训练过程中测试误差的函数。必要参数有executor,program,reader,feeder,fetch_list。
- executor表示之前创建的执行器
- program表示执行器所执行的program,是之前创建的program,如果该项参数没有给定的话则默认使用defalut_main_program
- reader表示读取到的数据
- feed表示前向输入的变量,即神经网络的输入
- fetch_list表示用户想得到的变量,即神经网络的输出
在Executor的run方法中,feed代表以字典形式定义的数据,通过fluid.DataFeeder函数的执行,会生成一个data的字典数据,其中data[0]和data[1]分别表示image和label。
值得注意的是,在每一轮的训练中,每100个batch之后会输出一次平均训练误差和准确率。每一轮训练之后,使用测试集进行一次测试,在每轮测试中,均打输出一次平均测试误差和准确率。
【注意】
在下列的代码中,我们每个TEST_EPOCH个周期都执行一次模型保存,这种方式一般应用在复杂的模型和大型数据集上。这种经常性的模型保存,有利于我们执行EarlyStopping策略,当我们发现运行曲线不再继续收敛时,就可以结束训练,并选择之前保存的最好的一个模型作为最终的模型。FinalModel (对于绘图程序矩阵,也可以进行定期保存,以便训练仍然在继续的时候,进行可视化操作,或者一定周期的训练后进行一次可视化.)
2.3.1 定义测试函数
模型测试一般包含两个类型,分别是:
- 在线测试,在线测试通常是针对验证集进行,并在训练过程中,每隔一定的周期输出一次精度和损失值
- 离线测试,指在模型训练结束之后,使用测试集进行的评估。
两种测试模式,在代码上基本上是一致的,只是所使用的数据不同。因此,我们可以定义一个eval()函数来实现代码复用,在进行评估时,分别调用val_reader()和test_reader()的即可。注意,本例中只存在测试集,不存在验证集。
def eval(): losses = [] accs = [] # 每训练TEST_EPOCH, 进行一次测试 for batch_id, data in enumerate(test_reader()): test_loss, test_acc = exe.run(program=test_program, feed=feeder.feed(data), fetch_list=[avg_loss, acc]) #fetch 误差、准确率 losses.append(test_loss[0]) accs.append(test_acc[0]) #每个batch的准确率 avg_test_loss = np.mean(losses) avg_test_acc = np.mean(accs) return avg_test_loss, avg_test_acc
2.3.2 定义训练函数
def train(): # 启动训练和在线测试 start = time.perf_counter() print('启动训练...') num_batch = 0 best_result = 0 best_result_id = 0 elapsed = 0 for epoch in range(1, total_epoch+1): # 进行训练 for batch_id, data in enumerate(train_reader()): #enumerate用于遍历train_reader,它会同时返回枚举数据及其索引值。enumerate可以用来遍历数组、列表及字符串等元素 num_batch += 1 # exe.run(主程序,数据,输出结果) train_loss, train_acc = exe.run(program=train_program, feed=feeder.feed(data), fetch_list=[avg_loss, acc]) if num_batch % log_interval == 0: # 每100个batch打印一次信息 误差、准确率 elapsed_step = time.perf_counter() - elapsed - start elapsed = time.perf_counter() - start print("Epoch:{}/{}, batch:{}, train_loss:{:.5f}, train_accuracy:{:.5f} ({:.2f}s)". format(epoch,total_epoch,num_batch,train_loss[0],train_acc[0],elapsed_step)) all_train_iters.append(num_batch) all_train_losses.append(train_loss[0]) all_train_accs.append(train_acc[0]) # 每隔一定周期进行一次测试 if epoch % eval_interval == 0 or epoch == total_epoch: # 在TEST_EPOCH周期后和训练结束时,均进行一次测试 avg_test_loss, avg_test_acc = eval() print('[validation] Epoch:{}/{}, test_loss:[{:.5f}], test_accuracy:[{:.5f}]'.format(epoch, total_epoch, avg_test_loss, avg_test_acc)) # 将性能最好的模型保存为final模型 if avg_test_acc > best_result: best_result = avg_test_acc best_result_id = epoch # 保存模型(推理模型的路径,输入的数据,输出的结果,执行器) fluid.io.save_inference_model(os.path.join(final_models_path, 'best_model'), ['image'], [predict], exe) print('当前性能最好的模型 epoch_{} 的精度: {:.5f}, 已将其赋值为:best_model'.format(best_result_id, best_result)) all_test_iters.append(epoch) all_test_losses.append(avg_test_loss) all_test_accs.append(avg_test_acc) # 可视化训练结果,输出训练损失和精度 # 保存最终模型 fluid.io.save_inference_model(os.path.join(final_models_path, 'model_final'), ['image'], [predict], exe) print('训练完成,最终性能accuracy={:.5f}(epoch={}), 总耗时{:.2f}s, 已将其保存为:best_model'.format(best_result, best_result_id, time.perf_counter() - start)) draw_process("Training Process", 'Train Loss', 'Train Accuracy', all_train_iters, all_train_losses, all_train_accs) draw_process("Validation Results", 'Validation Loss', 'Validation Accuracy', all_test_iters, all_test_losses, all_test_accs)
2.3.3 模型训练及在线测试
if __name__ == '__main__': # 初始化绘图列表 all_train_iters = [] all_train_losses = [] all_train_accs = [] all_test_losses = [] all_test_iters = [] all_test_accs = [] # 启动训练过程 train()
启动训练...
Epoch:1/10, batch:100, train_loss:0.57320, train_accuracy:0.85156 (1.48s)
Epoch:1/10, batch:200, train_loss:0.27187, train_accuracy:0.92969 (1.36s)
Epoch:1/10, batch:300, train_loss:0.38993, train_accuracy:0.86719 (1.29s)
Epoch:1/10, batch:400, train_loss:0.23332, train_accuracy:0.91406 (1.25s)
[validation] Epoch:1/10, test_loss:[0.32376], test_accuracy:[0.90289]
当前性能最好的模型 epoch_1 的精度: 0.90289, 已将其赋值为:best_model
Epoch:2/10, batch:500, train_loss:0.18745, train_accuracy:0.93750 (2.51s)
Epoch:2/10, batch:600, train_loss:0.36463, train_accuracy:0.88281 (1.36s)
Epoch:2/10, batch:700, train_loss:0.20271, train_accuracy:0.94531 (1.30s)
Epoch:2/10, batch:800, train_loss:0.33895, train_accuracy:0.91406 (1.27s)
Epoch:2/10, batch:900, train_loss:0.23529, train_accuracy:0.92969 (1.28s)
[validation] Epoch:2/10, test_loss:[0.38837], test_accuracy:[0.88904]
当前性能最好的模型 epoch_1 的精度: 0.90289, 已将其赋值为:best_model
Epoch:3/10, batch:1000, train_loss:0.26524, train_accuracy:0.91406 (2.48s)
Epoch:3/10, batch:1100, train_loss:0.20147, train_accuracy:0.94531 (1.34s)
Epoch:3/10, batch:1200, train_loss:0.33332, train_accuracy:0.90625 (1.30s)
Epoch:3/10, batch:1300, train_loss:0.30047, train_accuracy:0.91406 (1.30s)
Epoch:3/10, batch:1400, train_loss:0.07438, train_accuracy:0.97656 (1.30s)
[validation] Epoch:3/10, test_loss:[0.22708], test_accuracy:[0.93236]
当前性能最好的模型 epoch_3 的精度: 0.93236, 已将其赋值为:best_model
Epoch:4/10, batch:1500, train_loss:0.24671, train_accuracy:0.90625 (2.48s)
Epoch:4/10, batch:1600, train_loss:0.52399, train_accuracy:0.89844 (1.33s)
Epoch:4/10, batch:1700, train_loss:0.39057, train_accuracy:0.89062 (1.27s)
Epoch:4/10, batch:1800, train_loss:0.36346, train_accuracy:0.89844 (1.31s)
[validation] Epoch:4/10, test_loss:[0.21248], test_accuracy:[0.93532]
当前性能最好的模型 epoch_4 的精度: 0.93532, 已将其赋值为:best_model
Epoch:5/10, batch:1900, train_loss:0.19993, train_accuracy:0.93750 (2.48s)
Epoch:5/10, batch:2000, train_loss:0.22591, train_accuracy:0.93750 (1.27s)
Epoch:5/10, batch:2100, train_loss:0.33149, train_accuracy:0.92188 (1.30s)
Epoch:5/10, batch:2200, train_loss:0.46031, train_accuracy:0.89062 (1.32s)
Epoch:5/10, batch:2300, train_loss:0.08333, train_accuracy:0.97656 (1.28s)
[validation] Epoch:5/10, test_loss:[0.23497], test_accuracy:[0.93256]
当前性能最好的模型 epoch_4 的精度: 0.93532, 已将其赋值为:best_model
Epoch:6/10, batch:2400, train_loss:0.14996, train_accuracy:0.95312 (2.39s)
Epoch:6/10, batch:2500, train_loss:0.17879, train_accuracy:0.93750 (1.31s)
Epoch:6/10, batch:2600, train_loss:0.20504, train_accuracy:0.96094 (1.30s)
Epoch:6/10, batch:2700, train_loss:0.28247, train_accuracy:0.91406 (1.32s)
Epoch:6/10, batch:2800, train_loss:0.11950, train_accuracy:0.95312 (1.27s)
[validation] Epoch:6/10, test_loss:[0.25390], test_accuracy:[0.93404]
当前性能最好的模型 epoch_4 的精度: 0.93532, 已将其赋值为:best_model
Epoch:7/10, batch:2900, train_loss:0.17612, train_accuracy:0.93750 (2.37s)
Epoch:7/10, batch:3000, train_loss:0.20931, train_accuracy:0.92969 (1.26s)
Epoch:7/10, batch:3100, train_loss:0.20691, train_accuracy:0.93750 (1.30s)
Epoch:7/10, batch:3200, train_loss:0.21404, train_accuracy:0.93750 (1.31s)
[validation] Epoch:7/10, test_loss:[0.22686], test_accuracy:[0.94027]
当前性能最好的模型 epoch_7 的精度: 0.94027, 已将其赋值为:best_model
Epoch:8/10, batch:3300, train_loss:0.11711, train_accuracy:0.96094 (2.55s)
Epoch:8/10, batch:3400, train_loss:0.10025, train_accuracy:0.97656 (1.38s)
Epoch:8/10, batch:3500, train_loss:0.35743, train_accuracy:0.92188 (1.29s)
Epoch:8/10, batch:3600, train_loss:0.33144, train_accuracy:0.94531 (1.32s)
Epoch:8/10, batch:3700, train_loss:0.13708, train_accuracy:0.95312 (1.37s)
[validation] Epoch:8/10, test_loss:[0.23359], test_accuracy:[0.93859]
当前性能最好的模型 epoch_7 的精度: 0.94027, 已将其赋值为:best_model
Epoch:9/10, batch:3800, train_loss:0.13208, train_accuracy:0.94531 (2.36s)
Epoch:9/10, batch:3900, train_loss:0.11053, train_accuracy:0.95312 (1.35s)
Epoch:9/10, batch:4000, train_loss:0.32722, train_accuracy:0.90625 (1.38s)
Epoch:9/10, batch:4100, train_loss:0.15500, train_accuracy:0.94531 (1.37s)
Epoch:9/10, batch:4200, train_loss:0.16808, train_accuracy:0.94531 (1.34s)
[validation] Epoch:9/10, test_loss:[0.26442], test_accuracy:[0.93107]
当前性能最好的模型 epoch_7 的精度: 0.94027, 已将其赋值为:best_model
Epoch:10/10, batch:4300, train_loss:0.23700, train_accuracy:0.92188 (2.63s)
Epoch:10/10, batch:4400, train_loss:0.16415, train_accuracy:0.96094 (1.34s)
Epoch:10/10, batch:4500, train_loss:0.20306, train_accuracy:0.94531 (1.41s)
Epoch:10/10, batch:4600, train_loss:0.19550, train_accuracy:0.93750 (1.38s)
[validation] Epoch:10/10, test_loss:[0.23378], test_accuracy:[0.94037]
当前性能最好的模型 epoch_10 的精度: 0.94037, 已将其赋值为:best_model
训练完成,最终性能accuracy=0.94037(epoch=10), 总耗时73.47s, 已将其保存为:best_model

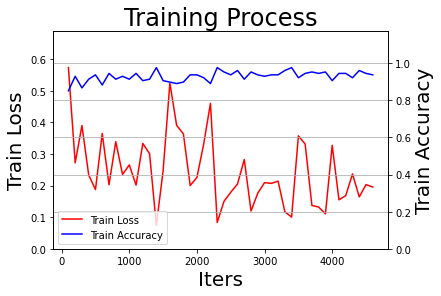
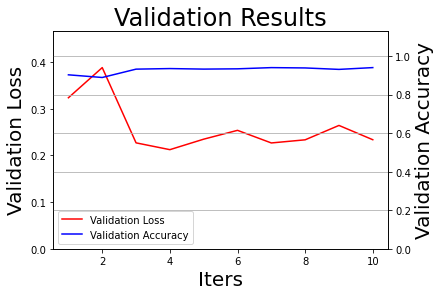
2.3.4 离线测试
离线测试与在线测试基本一致,不同的是离线测试需要使用load_inference_model()先读取事先保存的模型。
with fluid.scope_guard(fluid.core.Scope()): [inference_program, feed_target_names, fetch_targets] = fluid.io.load_inference_model(os.path.join(final_models_path, 'best_model'), exe) avg_test_loss, avg_test_acc = eval() print('测试集精度为:{:.5f}'.format(avg_test_acc))
测试集精度为:0.94037
【实验三】 模型评估与推理(应用)
实验目的:
- 学会载入已训练好的模型
- 掌握静态图中模型的验证与推理方法
在实际应用中,下面的工作可以视作是生产环境的具体应用。在研究中,也可以当作最终的结果对比。模型预测包含三个部分:
- 导入依赖库及全局参数配置
- 获取待预测数据
- 创建预测用执行器
- 载入模型并开始进行预测
- 输出结果
3.1 导入依赖库及全局参数配置
# 导入依赖库 import os import numpy as np import paddle # 载入PaddlePaddle基本库 import paddle.fluid as fluid # 载入基于fluid框架的paddle import matplotlib.pyplot as plt # 载入python的第三方图像处理库 dataset_name = 'MNIST' architecture = 'MLP' result_root_path = 'D:\\Workspace\\ExpResults\\' final_model_path = os.path.join(result_root_path, 'Project02FeedforwardNetworkStatic', dataset_name + '_' + architecture)
3.2 获取待预测数据
获取待测数据包含两个步骤: 1.获取图像路径和标签; 2. 根据图像路径读取图像并进行预处理。
我们可以通过data_reader()来从测试集列表中随机获取一个测试样本, 并使用line.split()函数拆分成路径和标签。但是,在实际使用中, 也可以直接指定(或从其他应用程序直接获得)待测样本。下面,我们以手动指定样本为例,对输入的图像进行预测。
load_image(), 从指定位置读取待测图像, 并对该图像进行预处理。此处的预处理方案和训练模型时所使用的预处理方案必须是一致的。
- 使用cv2.imread(imgPath, 0)读取图像,并通过第二个参数指定使用灰度模式进行读取
- 首先需要将所有样本都resize到同样的尺度,MNIST数据集为28*28.
- 将图像数据转换为
numpy.array格式,并转换为一维向量, 32bit浮点数据类型(float32) - 将像素值的取值范围调整为:0-1, 原始范围为:0-255
def load_image(img_path): img = cv2.imread(img_path, 0) # cv2.imread(path, 0|1),其中0表示灰度模式,1表示彩色模式 img = cv2.resize(img, (28, 28)) # resize image with high-quality 图像大小为28*28 img = np.array(img).reshape(1,1*28*28).astype('float32') # 返回新形状的数组,把它变成一个 numpy 数组以匹配数据馈送格式。 img = img/255.0 # 将数据归一化到[0~1]之间,也可以归一化为[-1,1]之间, img = img/255.0*2.0-1.0 return img
3.3 创建预测用的Executer
通过fluid.io.load_inference_model,预测器会从params_dirname中读取已经训练好的模型,来对从未遇见过的数据进行预测。
infer_exe = fluid.Executor() # 在推理阶段调用和训练时一样的执行器(设备)进行运算 infer_exe.run(fluid.default_startup_program()) inference_scope = fluid.core.Scope()
3.4 载入模型并开始进行预测
通过fluid.io.load_inference_model,预测器会从params_dirname中读取已经训练好的模型,来对从未遇见过的数据进行预测。
img_path = 'D:\\Workspace\\ExpDatasets\\MNIST\\Infer\\infer_8.png' # 载入图片{infer_x: 1,3,4,6,7,8} best_model = os.path.join(final_model_path, 'best_model') # 加载数据并开始预测 with fluid.scope_guard(inference_scope): # inference_program:从指定目录中加载训练好的模型,用于推理(inference model) # feed_target_names:推理Program, 是一个str列表,它包含需要在推理 Program 中提供数据的变量的名称。 # fetch_targets:是一个 Variable 列表,从中我们可以得到推断结果。 # MODEL_DIR:模型保存的路径 # infer_exe: 运行 inference model的 executor [inference_program, feed_target_names, fetch_targets] = fluid.io.load_inference_model(best_model, infer_exe) img = load_image(img_path) # program: 运行推测程序 # feed: 喂入要预测的img,与训练和测试时相似,feed也是一个字典数据类型,索引为feed_target_names=image,其值为img,其返回值是load_image获得的图像。 # fetch_list:得到推测结果 results = infer_exe.run(program=inference_program, feed={feed_target_names[0]: img}, fetch_list=fetch_targets) # 输出图像文件 image = cv2.imread(img_path, 1) image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) plt.imshow(image) # display(Image.open(img_path)) # 显示图像 print("该图片的预测结果为: {}".format(np.argmax(results))) # argmax函数返回数组中最大值的索引值
该图片的预测结果为: 8
