【项目013】基于迁移学习十二生肖识别(教学版) 学生版 | 返回首页
作者:欧新宇(Xinyu OU)
当前版本:Release v1.1
开发平台:Paddle 2.3.2
运行环境:Intel Core i7-7700K CPU 4.2GHz, nVidia GeForce GTX 1080 Ti
本教案所涉及的数据集仅用于教学和交流使用,请勿用作商用。
最后更新:2022年10月16日
【实验目的】
- 学会调用paddle.vision.models库实现内置模型的调用,并能够实现预训练模型的载入
- 熟练使用各种不同的模型(AlexNet, ResNet, VGG, MobileNet等)进行训练、验证和推理
- 熟练使用logging函数进行日志输出和保存,熟练保存运行结果图,并能够反复调用输出
- 能够快速更改优化
【实验要求】
- 所有作业均在AIStudio上进行提交,提交时包含源代码和运行结果
- 补充完成下列AlexNet, ResNet50, ResNet18, Mobilenetv2, VGG16四个模型的结果统计表(至少完成三对模型的评估)
- 对下列结果进行总结和分析
下面我们将在ResNet50, ResNet18, Mobilenetv2, VGG16四个模型对十二生肖数据集进行评估,所有模型设置batch_size=64。
数据集包含样本8500个,其中训练验证集样本7840个,训练集样本7190个, 验证集样本650个, 测试集样本660个, 共计8500个。
【实验一】 数据集准备
实验摘要: 对于模型训练的任务,需要数据预处理,将数据整理成为适合给模型训练使用的格式。十二生肖识别数据集是一个包含有12个不同种类8500个样本的数据集,不同种类的样本按照十二种不同的物种类别各自放到了相应的文件夹。不同的样本具有不同的尺度。
实验目的:
- 学会观察数据集的文件结构,考虑是否需要进行数据清理,包括删除无法读取的样本、处理冗长不合规范的文件命名等。
data_clean.py - 能够按照训练集、验证集、训练验证集、测试集四种子集对数据集进行划分,并生成数据列表。
generate_annotation.py - 能够根据数据划分结果和样本的类别,生成包含数据集摘要信息下数据集信息文件
dataset_info.json - 能简单展示和预览数据的基本信息,包括数据量,规模,数据类型和位深度等
1.0 处理数据集中样本命名的非法字符
# !python "D:\WorkSpace\ExpDatasets\Zodiac\data_clean.py"
1.1 生产图像列表及类别标签
# !python "D:\WorkSpace\ExpDatasets\Zodiac\generate_annotation.py"
【实验二】 全局参数设置及数据基本处理
实验摘要: 蝴蝶种类识别是一个多分类问题,我们通过卷积神经网络来完成。这部分通过PaddlePaddle手动构造一个Alexnet卷积神经的网络来实现识别功能。本实验主要实现训练前的一些准备工作,包括:全局参数定义,数据集载入,数据预处理,可视化函数定义,日志输出函数定义。
实验目的:
- 学会使用配置文件定义全局参数
- 学会设置和载入数据集
- 学会对输入样本进行基本的预处理
- 学会定义可视化函数,可视化训练过程,同时输出可视化结果图和数据
- 学会使用logging定义日志输出函数,用于训练过程中的日志保持
2.1 导入依赖及全局参数配置
#################导入依赖库################################################## import os import sys import json import codecs import numpy as np import time # 载入time时间库,用于计算训练时间 import matplotlib.pyplot as plt # 载入python的第三方图像处理库 from pprint import pprint # 载入格式化的print工具 import paddle from paddle.static import InputSpec from paddle.io import DataLoader sys.path.append(r'D:\WorkSpace\DeepLearning\WebsiteV2') # 导入自定义函数保存位置 from utils.getSystemInfo import getSystemInfo # 载入自定义系统信息函数 from utils.getVisualization import draw_process # 载入自定义可视化绘图函数 from utils.getOptimizer import learning_rate_setting, optimizer_setting # 载入自定义优化函数 from utils.getLogging import init_log_config # 载入自定义日志保存函数 from utils.datasets.Zodiac import ZodiacDataset # 载入Butterfly数据集 from utils.evaluate import evaluate # 载入验证评估函数 from utils.train import train # 载入验证训练函数 ################全局参数配置################################################### #### 1. 训练超参数定义 args = { 'project_name': 'Project013TransferLearningZodiac', 'dataset_name': 'Zodiac', 'architecture': 'mobilenet_v2', # alexnet, mobilenet_v2, vgg16, resnet18, resnet50 'training_data': 'train', 'starting_time': time.strftime("%Y%m%d%H%M", time.localtime()), # 全局启动时间 'input_size': [3, 227, 227], # 输入样本的尺度 'mean_value': [0.485, 0.456, 0.406], # Imagenet均值 'std_value': [0.229, 0.224, 0.225], # Imagenet标准差 'num_trainval': -1, 'num_train': -1, 'num_val': -1, 'num_test': -1, 'class_dim': -1, 'label_dict': {}, 'total_epoch': 10, # 总迭代次数, 代码调试好后考虑 'batch_size': 64, # 设置每个批次的数据大小,同时对训练提供器和测试 'log_interval': 10, # 设置训练过程中,每隔多少个batch显示一次 'eval_interval': 1, # 设置每个多少个epoch测试一次 'checkpointed': False, # 是否保存checkpoint模型 'checkpoint_train': False, # 是否接着上一次保存的参数接着训练,优先级高于预训练模型 'checkpoint_model':'Butterfly_Mobilenetv2', # 设置恢复训练时载入的模型参数 'checkpoint_time': '202102182058', # 恢复训练时所指向的指定时间戳 'pretrained': True, # 是否使用预训练的模型 'pretrained_model':'API', # 设置预训练模型, API|Butterflies_AlexNet_final 'dataset_root_path': 'D:\\Workspace\\ExpDatasets\\', 'result_root_path': 'D:\\Workspace\\ExpResults\\', 'deployment_root_path': 'D:\\Workspace\\ExpDeployments\\', 'useGPU': True, # True | Flase 'learning_strategy': { # 学习率和优化器相关参数 'optimizer_strategy': 'Momentum', # 优化器:Momentum, RMS, SGD, Adam 'learning_rate_strategy': 'CosineAnnealingDecay', # 学习率策略: 固定fixed, 分段衰减PiecewiseDecay, 余弦退火CosineAnnealingDecay, 指数ExponentialDecay, 多项式PolynomialDecay 'learning_rate': 0.001, # 固定学习率 'momentum': 0.9, # 动量 'Piecewise_boundaries': [60, 80, 90], # 分段衰减:变换边界,每当运行到epoch时调整一次 'Piecewise_values': [0.01, 0.001, 0.0001, 0.00001], # 分段衰减:步进学习率,每次调节的具体值 'Exponential_gamma': 0.9, # 指数衰减:衰减指数 'Polynomial_decay_steps': 10, # 多项式衰减:衰减周期,每个多少个epoch衰减一次 'verbose': False }, 'results_path': { 'checkpoint_models_path': None, # 迭代训练模型保存路径 'final_figures_path': None, # 训练过程曲线图 'final_models_path': None, # 最终用于部署和推理的模型 'logs_path': None, # 训练过程日志 }, 'deployments_path':{ 'deployment_root_path': None, 'deployment_checkpoint_model': None, 'deployment_final_model': None, 'deployment_final_figures_path ': None, 'deployment_logs_path': None, 'deployment_pretrained_model': None, } } #### 2. 设置简化参数名 if not args['pretrained']: args['model_name'] = args['dataset_name'] + '_' + args['architecture'] + '_withoutPretrained' else: args['model_name'] = args['dataset_name'] + '_' + args['architecture'] #### 3. 定义设备工作模式 [GPU|CPU] # 定义使用CPU还是GPU,使用CPU时use_cuda = False,使用GPU时use_cuda = True def init_device(useGPU=args['useGPU']): paddle.set_device('gpu:0') if useGPU else paddle.set_device('cpu') init_device() #### 4.定义各种路径:模型、训练、日志结果图 # 4.1 数据集路径 args['dataset_root_path'] = os.path.join(args['dataset_root_path'], args['dataset_name']) # 4.2 训练过程涉及的相关路径 result_root_path = os.path.join(args['result_root_path'], args['project_name']) args['results_path']['checkpoint_models_path'] = os.path.join(result_root_path, 'checkpoint_models') # 迭代训练模型保存路径 args['results_path']['final_figures_path'] = os.path.join(result_root_path, 'final_figures') # 训练过程曲线图 args['results_path']['final_models_path'] = os.path.join(result_root_path, 'final_models') # 最终用于部署和推理的模型 args['results_path']['logs_path'] = os.path.join(result_root_path, 'logs') # 训练过程日志 # 4.3 验证和测试时的相关路径(文件) deployment_root_path = os.path.join(args['deployment_root_path'], args['project_name']) args['deployments_path']['deployment_checkpoint_model'] = os.path.join(deployment_root_path, 'checkpoint_models', args['model_name'] + '_final') args['deployments_path']['deployment_final_model'] = os.path.join(deployment_root_path, 'final_models', args['model_name'] + '_final') args['deployments_path']['deployment_final_figures_path'] = os.path.join(deployment_root_path, 'final_figures') args['deployments_path']['deployment_logs_path'] = os.path.join(deployment_root_path, 'logs') args['deployments_path']['deployment_pretrained_model'] = os.path.join(deployment_root_path, 'pretrained_dir', args['pretrained_model']) # 4.4 初始化结果目录 def init_result_path(): if not os.path.exists(args['results_path']['final_models_path']): os.makedirs(args['results_path']['final_models_path']) if not os.path.exists(args['results_path']['final_figures_path']): os.makedirs(args['results_path']['final_figures_path']) if not os.path.exists(args['results_path']['logs_path']): os.makedirs(args['results_path']['logs_path']) if not os.path.exists(args['results_path']['checkpoint_models_path']): os.makedirs(args['results_path']['checkpoint_models_path']) init_result_path() #### 5. 初始化参数 def init_train_parameters(): dataset_info = json.loads(open(os.path.join(args['dataset_root_path'] , 'dataset_info.json'), 'r', encoding='utf-8').read()) args['num_trainval'] = dataset_info['num_trainval'] args['num_train'] = dataset_info['num_train'] args['num_val'] = dataset_info['num_val'] args['num_test'] = dataset_info['num_test'] args['class_dim'] = dataset_info['class_dim'] args['label_dict'] = dataset_info['label_dict'] init_train_parameters() #### 6. 初始化日志方法 logger = init_log_config(logs_path=args['results_path']['logs_path'], model_name=args['model_name']) # 输出训练参数 train_parameters # if __name__ == '__main__': # pprint(args)
2.2 数据集定义及数据预处理
在Paddle 2.0+ 中,对数据的获取包含两个步骤,一是创建数据集类,二是创建数据迭代读取器。
- 使用
paddle.io构造数据集类。数据类能够实现从本地获取数据列表,并对样本进行数据预处理。全新的paddle.vision.transforms可以轻松的实现样本的多种预处理功能,而不用手动去写数据预处理的函数,这大简化了代码的复杂性。对于用于训练训练集(训练验证集),我们可以按照一定的比例进行数据增广,并进行标准的数据预处理;对于验证集和测试集则只需要进行标准的数据预处理即可。 - 结合
paddle.io.DataLoader工具包,可以将读入的数据进行batch划分,确定是否进行随机打乱和是否丢弃最后的冗余样本。- 一般来说,对于训练样本(包括train和trainvl),我们需要进行随机打乱,让每次输入到网络中的样本处于不同的组合形式,防止过拟合的产生;对于验证数据和测试数据,由于每次测试都需要对所有样本进行一次完整的遍历,并计算最终的平均值,因此是否进行打乱,并不影响最终的结果。
- 由于在最终输出的loss和accuracy的平均值时,会事先进行一次批内的平均,因此如果最后一个batch的数据并不能构成完整的一批,即实际样本数量小于batch_size,会导致最终计算精度产生一定的偏差。所以,当样本数较多的时候,可以考虑在训练时丢弃最后一个batch的数据。但值得注意的是,验证集和测试集不能进行丢弃,否则会有一部分样本无法进行测试。
- 载入数据库类模块
模块调用方法
-
源代码:Zodiac.py
-
调用方法:
sys.path.append(r'D:\WorkSpace\DeepLearning\WebsiteV2 # 定义模块保存位置 from datasets.Zodiac import ZodiacDataset # 导入数据集模块
- 创建数据迭代器
# 1. 从数据集库中获取数据 dataset_trainval = ZodiacDataset(args['dataset_root_path'], mode='trainval') dataset_train = ZodiacDataset(args['dataset_root_path'], mode='train') dataset_val = ZodiacDataset(args['dataset_root_path'], mode='val') dataset_test = ZodiacDataset(args['dataset_root_path'], mode='test') # 2. 创建读取器 trainval_reader = DataLoader(dataset_trainval, batch_size=args['batch_size'], shuffle=True, drop_last=True) train_reader = DataLoader(dataset_train, batch_size=args['batch_size'], shuffle=True, drop_last=True) val_reader = DataLoader(dataset_val, batch_size=args['batch_size'], shuffle=False, drop_last=False) test_reader = DataLoader(dataset_test, batch_size=args['batch_size'], shuffle=False, drop_last=False) #################################################################################################################### # 3.测试读取器 if __name__ == "__main__": for i, (image, label) in enumerate(val_reader()): print('验证集batch_{}的图像形态:{}, 标签形态:{}'.format(i, image.shape, label.shape)) break
验证集batch_0的图像形态:[64, 3, 227, 227], 标签形态:[64]
2.3 定义过程可视化函数 (无需事先执行)
定义训练过程中用到的可视化方法, 包括训练损失, 训练集批准确率, 测试集损失,测试机准确率等。 根据具体的需求,可以在训练后展示这些数据和迭代次数的关系. 值得注意的是, 训练过程中可以每个epoch绘制一个数据点,也可以每个batch绘制一个数据点,也可以每个n个batch或n个epoch绘制一个数据点。可视化代码除了实现训练后自动可视化的函数,同时实现将可视化的图片和数据进行保存,保存的文件夹由 final_figures_path 指定。
- 模块调用方法
-
调用方法:
sys.path.append(r'D:\WorkSpace\DeepLearning\WebsiteV2 # 定义模块保存位置 from utils.getVisualization import draw_process # 导入数据集模块 draw_process('Training', 'loss', 'accuracy', iters=train_log[0], losses=train_log[1], accuracies=train_log[2], final_figures_path=final_figures_path, figurename='train', isShow=True) # 模块调用方法
# 以下代码为可视化函数的测试代码,仅供演示和测试,本项目的运行无需事先执行。 if __name__ == '__main__': try: train_log = np.load(os.path.join(args['results_path']['final_figures_path'], 'train.npy')) print('训练数据可视化结果:') draw_process('Training', 'loss', 'accuracy', iters=train_log[0], losses=train_log[1], accuracies=train_log[2], final_figures_path=final_figures_path, figurename='train', isShow=True) except: print('以下图例为测试数据。') draw_process('Training', 'loss', 'accuracy', figurename='default', isShow=True)
以下图例为测试数据。
2.4 定义日志输出函数 (无需事先执行)
logging是一个专业的日志输出库,可以用于在屏幕上打印运行结果(和print()函数一致),也可以实现将这些运行结果保存到指定的文件夹中,用于后续的研究。
- 模块调用方法
-
源代码:getLogging.py
-
调用方法:
sys.path.append(r'D:\WorkSpace\DeepLearning\WebsiteV2 # 定义模块保存位置 from utils.getLogging import init_log_config # 导入日志模块 logger = init_log_config(logs_path=logs_path, model_name=model_name) # 初始化日志模块,配置日志输出路径和模型名称 logger.info('系统基本信息:') # logger模块调用方法
# 以下代码为日志输出测试代码,仅供演示和测试,本项目的运行无需事先执行。 if __name__ == "__main__": logger.info('测试一下, 模型名称: {}'.format(args['model_name'])) system_info = json.dumps(getSystemInfo(), indent=4, ensure_ascii=False, sort_keys=False, separators=(',', ':')) logger.info('系统基本信息:') logger.info(system_info)
2022-10-15 21:37:02,798 - INFO: 测试一下, 模型名称: Zodiac_mobilenet_v2
2022-10-15 21:37:03,866 - INFO: 系统基本信息:
2022-10-15 21:37:03,867 - INFO: {
"操作系统":"Windows-10-10.0.22000-SP0",
"CPU":"Intel(R) Core(TM) i7-9700 CPU @ 3.00GHz",
"内存":"7.96G/15.88G (50.10%)",
"GPU":"b'GeForce RTX 2080' 1.25G/8.00G (0.16%)",
"CUDA/cuDNN":"10.2 / 7.6.5",
"Paddle":"2.3.2"
}
【实验三】 模型训练与评估
实验摘要: 十二生肖识别是一个多分类问题,我们通过卷积神经网络来完成。
实验目的:
- 掌握卷积神经网络的构建和基本原理
- 深刻理解训练集、验证集、训练验证集及测试集在模型训练中的作用
- 学会按照网络拓扑结构图定义神经网络类 (Paddle 2.0+)
- 学会在线测试和离线测试两种测试方法
- 学会定义多种优化方法,并在全局参数中进行定义选择
3.1 配置网络模型 (无需事先执行)
从Alexnet开始,包括VGG,GoogLeNet,Resnet等模型都是层次较深的模型,如果按照逐层的方式进行设计,代码会变得非常繁琐。因此,我们可以考虑将相同结构的模型进行汇总和合成,例如Alexnet中,卷积层+激活+池化层就是一个完整的结构体。
如果使用的是标准的网络结构,我们可以直接从Paddle的模型库中进行下载,并启用预训练模型,载入Imagenet预训练参数。再实际应用中,预训练(迁移学习)是非常有效的提高性能和缩减训练时间的方法。在载入Paddle模型库的时候,我们不需要手动设计模型,只需要按照下面的方法来直接调用即可。当然,如果是自己设计的模型,还是需要手动进行模型类的创建。
在飞桨中,Paddle.vision.models 类内置了很多标准模型库,包括LeNet, alexnet, mobilenet_v1, mobilenet_v2, resnet18(34, 50, 101, 152), vgg16, googlenet等,更多的模型请参考:paddle.vision
# 以下代码为模型测试代码,仅供演示和测试,本项目的运行无需事先执行。 import paddle from paddle.static import InputSpec # 1. 设置输入样本的维度 input_spec = InputSpec(shape=[None] + args['input_size'], dtype='float32', name='image') label_spec = InputSpec(shape=[None, 1], dtype='int64', name='label') # 2. 载入官方标准模型,若不存在则会自动进行下载,pretrained=True|False控制是否使用Imagenet预训练参数 network = exec("paddle.vision.models." + args['architecture'] + "(num_classes=args['class_dim'], pretrained=args['pretrained'])") # 3. 初始化模型并输出基本信息 model = paddle.Model(network, input_spec, label_spec) logger.info('模型参数信息:') logger.info(model.summary()) # 是否显示神经网络的具体信息
2022-10-15 21:37:03,993 - INFO: unique_endpoints {''}
2022-10-15 21:37:03,994 - INFO: File C:\Users\Administrator/.cache/paddle/hapi/weights\mobilenet_v2_x1.0.pdparams md5 checking...
2022-10-15 21:37:04,042 - INFO: Found C:\Users\Administrator/.cache/paddle/hapi/weights\mobilenet_v2_x1.0.pdparams
c:\Users\Administrator\anaconda3\lib\site-packages\paddle\fluid\dygraph\layers.py:1492: UserWarning: Skip loading for classifier.1.weight. classifier.1.weight receives a shape [1280, 1000], but the expected shape is [1280, 12].
warnings.warn(("Skip loading for {}. ".format(key) + str(err)))
c:\Users\Administrator\anaconda3\lib\site-packages\paddle\fluid\dygraph\layers.py:1492: UserWarning: Skip loading for classifier.1.bias. classifier.1.bias receives a shape [1000], but the expected shape is [12].
warnings.warn(("Skip loading for {}. ".format(key) + str(err)))
2022-10-15 21:37:04,192 - INFO: 模型参数信息:
2022-10-15 21:37:05,656 - INFO: {'total_params': 2273356, 'trainable_params': 2205132}
-------------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===============================================================================
Conv2D-1 [[1, 3, 227, 227]] [1, 32, 114, 114] 864
BatchNorm2D-1 [[1, 32, 114, 114]] [1, 32, 114, 114] 128
ReLU6-1 [[1, 32, 114, 114]] [1, 32, 114, 114] 0
Conv2D-2 [[1, 32, 114, 114]] [1, 32, 114, 114] 288
BatchNorm2D-2 [[1, 32, 114, 114]] [1, 32, 114, 114] 128
ReLU6-2 [[1, 32, 114, 114]] [1, 32, 114, 114] 0
Conv2D-3 [[1, 32, 114, 114]] [1, 16, 114, 114] 512
BatchNorm2D-3 [[1, 16, 114, 114]] [1, 16, 114, 114] 64
InvertedResidual-1 [[1, 32, 114, 114]] [1, 16, 114, 114] 0
Conv2D-4 [[1, 16, 114, 114]] [1, 96, 114, 114] 1,536
BatchNorm2D-4 [[1, 96, 114, 114]] [1, 96, 114, 114] 384
ReLU6-3 [[1, 96, 114, 114]] [1, 96, 114, 114] 0
Conv2D-5 [[1, 96, 114, 114]] [1, 96, 57, 57] 864
BatchNorm2D-5 [[1, 96, 57, 57]] [1, 96, 57, 57] 384
ReLU6-4 [[1, 96, 57, 57]] [1, 96, 57, 57] 0
Conv2D-6 [[1, 96, 57, 57]] [1, 24, 57, 57] 2,304
BatchNorm2D-6 [[1, 24, 57, 57]] [1, 24, 57, 57] 96
InvertedResidual-2 [[1, 16, 114, 114]] [1, 24, 57, 57] 0
Conv2D-7 [[1, 24, 57, 57]] [1, 144, 57, 57] 3,456
BatchNorm2D-7 [[1, 144, 57, 57]] [1, 144, 57, 57] 576
ReLU6-5 [[1, 144, 57, 57]] [1, 144, 57, 57] 0
Conv2D-8 [[1, 144, 57, 57]] [1, 144, 57, 57] 1,296
BatchNorm2D-8 [[1, 144, 57, 57]] [1, 144, 57, 57] 576
ReLU6-6 [[1, 144, 57, 57]] [1, 144, 57, 57] 0
Conv2D-9 [[1, 144, 57, 57]] [1, 24, 57, 57] 3,456
BatchNorm2D-9 [[1, 24, 57, 57]] [1, 24, 57, 57] 96
InvertedResidual-3 [[1, 24, 57, 57]] [1, 24, 57, 57] 0
Conv2D-10 [[1, 24, 57, 57]] [1, 144, 57, 57] 3,456
BatchNorm2D-10 [[1, 144, 57, 57]] [1, 144, 57, 57] 576
ReLU6-7 [[1, 144, 57, 57]] [1, 144, 57, 57] 0
Conv2D-11 [[1, 144, 57, 57]] [1, 144, 29, 29] 1,296
BatchNorm2D-11 [[1, 144, 29, 29]] [1, 144, 29, 29] 576
ReLU6-8 [[1, 144, 29, 29]] [1, 144, 29, 29] 0
Conv2D-12 [[1, 144, 29, 29]] [1, 32, 29, 29] 4,608
BatchNorm2D-12 [[1, 32, 29, 29]] [1, 32, 29, 29] 128
InvertedResidual-4 [[1, 24, 57, 57]] [1, 32, 29, 29] 0
Conv2D-13 [[1, 32, 29, 29]] [1, 192, 29, 29] 6,144
BatchNorm2D-13 [[1, 192, 29, 29]] [1, 192, 29, 29] 768
ReLU6-9 [[1, 192, 29, 29]] [1, 192, 29, 29] 0
Conv2D-14 [[1, 192, 29, 29]] [1, 192, 29, 29] 1,728
BatchNorm2D-14 [[1, 192, 29, 29]] [1, 192, 29, 29] 768
ReLU6-10 [[1, 192, 29, 29]] [1, 192, 29, 29] 0
Conv2D-15 [[1, 192, 29, 29]] [1, 32, 29, 29] 6,144
BatchNorm2D-15 [[1, 32, 29, 29]] [1, 32, 29, 29] 128
InvertedResidual-5 [[1, 32, 29, 29]] [1, 32, 29, 29] 0
Conv2D-16 [[1, 32, 29, 29]] [1, 192, 29, 29] 6,144
BatchNorm2D-16 [[1, 192, 29, 29]] [1, 192, 29, 29] 768
ReLU6-11 [[1, 192, 29, 29]] [1, 192, 29, 29] 0
Conv2D-17 [[1, 192, 29, 29]] [1, 192, 29, 29] 1,728
BatchNorm2D-17 [[1, 192, 29, 29]] [1, 192, 29, 29] 768
ReLU6-12 [[1, 192, 29, 29]] [1, 192, 29, 29] 0
Conv2D-18 [[1, 192, 29, 29]] [1, 32, 29, 29] 6,144
BatchNorm2D-18 [[1, 32, 29, 29]] [1, 32, 29, 29] 128
InvertedResidual-6 [[1, 32, 29, 29]] [1, 32, 29, 29] 0
Conv2D-19 [[1, 32, 29, 29]] [1, 192, 29, 29] 6,144
BatchNorm2D-19 [[1, 192, 29, 29]] [1, 192, 29, 29] 768
ReLU6-13 [[1, 192, 29, 29]] [1, 192, 29, 29] 0
Conv2D-20 [[1, 192, 29, 29]] [1, 192, 15, 15] 1,728
BatchNorm2D-20 [[1, 192, 15, 15]] [1, 192, 15, 15] 768
ReLU6-14 [[1, 192, 15, 15]] [1, 192, 15, 15] 0
Conv2D-21 [[1, 192, 15, 15]] [1, 64, 15, 15] 12,288
BatchNorm2D-21 [[1, 64, 15, 15]] [1, 64, 15, 15] 256
InvertedResidual-7 [[1, 32, 29, 29]] [1, 64, 15, 15] 0
Conv2D-22 [[1, 64, 15, 15]] [1, 384, 15, 15] 24,576
BatchNorm2D-22 [[1, 384, 15, 15]] [1, 384, 15, 15] 1,536
ReLU6-15 [[1, 384, 15, 15]] [1, 384, 15, 15] 0
Conv2D-23 [[1, 384, 15, 15]] [1, 384, 15, 15] 3,456
BatchNorm2D-23 [[1, 384, 15, 15]] [1, 384, 15, 15] 1,536
ReLU6-16 [[1, 384, 15, 15]] [1, 384, 15, 15] 0
Conv2D-24 [[1, 384, 15, 15]] [1, 64, 15, 15] 24,576
BatchNorm2D-24 [[1, 64, 15, 15]] [1, 64, 15, 15] 256
InvertedResidual-8 [[1, 64, 15, 15]] [1, 64, 15, 15] 0
Conv2D-25 [[1, 64, 15, 15]] [1, 384, 15, 15] 24,576
BatchNorm2D-25 [[1, 384, 15, 15]] [1, 384, 15, 15] 1,536
ReLU6-17 [[1, 384, 15, 15]] [1, 384, 15, 15] 0
Conv2D-26 [[1, 384, 15, 15]] [1, 384, 15, 15] 3,456
BatchNorm2D-26 [[1, 384, 15, 15]] [1, 384, 15, 15] 1,536
ReLU6-18 [[1, 384, 15, 15]] [1, 384, 15, 15] 0
Conv2D-27 [[1, 384, 15, 15]] [1, 64, 15, 15] 24,576
BatchNorm2D-27 [[1, 64, 15, 15]] [1, 64, 15, 15] 256
InvertedResidual-9 [[1, 64, 15, 15]] [1, 64, 15, 15] 0
Conv2D-28 [[1, 64, 15, 15]] [1, 384, 15, 15] 24,576
BatchNorm2D-28 [[1, 384, 15, 15]] [1, 384, 15, 15] 1,536
ReLU6-19 [[1, 384, 15, 15]] [1, 384, 15, 15] 0
Conv2D-29 [[1, 384, 15, 15]] [1, 384, 15, 15] 3,456
BatchNorm2D-29 [[1, 384, 15, 15]] [1, 384, 15, 15] 1,536
ReLU6-20 [[1, 384, 15, 15]] [1, 384, 15, 15] 0
Conv2D-30 [[1, 384, 15, 15]] [1, 64, 15, 15] 24,576
BatchNorm2D-30 [[1, 64, 15, 15]] [1, 64, 15, 15] 256
InvertedResidual-10 [[1, 64, 15, 15]] [1, 64, 15, 15] 0
Conv2D-31 [[1, 64, 15, 15]] [1, 384, 15, 15] 24,576
BatchNorm2D-31 [[1, 384, 15, 15]] [1, 384, 15, 15] 1,536
ReLU6-21 [[1, 384, 15, 15]] [1, 384, 15, 15] 0
Conv2D-32 [[1, 384, 15, 15]] [1, 384, 15, 15] 3,456
BatchNorm2D-32 [[1, 384, 15, 15]] [1, 384, 15, 15] 1,536
ReLU6-22 [[1, 384, 15, 15]] [1, 384, 15, 15] 0
Conv2D-33 [[1, 384, 15, 15]] [1, 96, 15, 15] 36,864
BatchNorm2D-33 [[1, 96, 15, 15]] [1, 96, 15, 15] 384
InvertedResidual-11 [[1, 64, 15, 15]] [1, 96, 15, 15] 0
Conv2D-34 [[1, 96, 15, 15]] [1, 576, 15, 15] 55,296
BatchNorm2D-34 [[1, 576, 15, 15]] [1, 576, 15, 15] 2,304
ReLU6-23 [[1, 576, 15, 15]] [1, 576, 15, 15] 0
Conv2D-35 [[1, 576, 15, 15]] [1, 576, 15, 15] 5,184
BatchNorm2D-35 [[1, 576, 15, 15]] [1, 576, 15, 15] 2,304
ReLU6-24 [[1, 576, 15, 15]] [1, 576, 15, 15] 0
Conv2D-36 [[1, 576, 15, 15]] [1, 96, 15, 15] 55,296
BatchNorm2D-36 [[1, 96, 15, 15]] [1, 96, 15, 15] 384
InvertedResidual-12 [[1, 96, 15, 15]] [1, 96, 15, 15] 0
Conv2D-37 [[1, 96, 15, 15]] [1, 576, 15, 15] 55,296
BatchNorm2D-37 [[1, 576, 15, 15]] [1, 576, 15, 15] 2,304
ReLU6-25 [[1, 576, 15, 15]] [1, 576, 15, 15] 0
Conv2D-38 [[1, 576, 15, 15]] [1, 576, 15, 15] 5,184
BatchNorm2D-38 [[1, 576, 15, 15]] [1, 576, 15, 15] 2,304
ReLU6-26 [[1, 576, 15, 15]] [1, 576, 15, 15] 0
Conv2D-39 [[1, 576, 15, 15]] [1, 96, 15, 15] 55,296
BatchNorm2D-39 [[1, 96, 15, 15]] [1, 96, 15, 15] 384
InvertedResidual-13 [[1, 96, 15, 15]] [1, 96, 15, 15] 0
Conv2D-40 [[1, 96, 15, 15]] [1, 576, 15, 15] 55,296
BatchNorm2D-40 [[1, 576, 15, 15]] [1, 576, 15, 15] 2,304
ReLU6-27 [[1, 576, 15, 15]] [1, 576, 15, 15] 0
Conv2D-41 [[1, 576, 15, 15]] [1, 576, 8, 8] 5,184
BatchNorm2D-41 [[1, 576, 8, 8]] [1, 576, 8, 8] 2,304
ReLU6-28 [[1, 576, 8, 8]] [1, 576, 8, 8] 0
Conv2D-42 [[1, 576, 8, 8]] [1, 160, 8, 8] 92,160
BatchNorm2D-42 [[1, 160, 8, 8]] [1, 160, 8, 8] 640
InvertedResidual-14 [[1, 96, 15, 15]] [1, 160, 8, 8] 0
Conv2D-43 [[1, 160, 8, 8]] [1, 960, 8, 8] 153,600
BatchNorm2D-43 [[1, 960, 8, 8]] [1, 960, 8, 8] 3,840
ReLU6-29 [[1, 960, 8, 8]] [1, 960, 8, 8] 0
Conv2D-44 [[1, 960, 8, 8]] [1, 960, 8, 8] 8,640
BatchNorm2D-44 [[1, 960, 8, 8]] [1, 960, 8, 8] 3,840
ReLU6-30 [[1, 960, 8, 8]] [1, 960, 8, 8] 0
Conv2D-45 [[1, 960, 8, 8]] [1, 160, 8, 8] 153,600
BatchNorm2D-45 [[1, 160, 8, 8]] [1, 160, 8, 8] 640
InvertedResidual-15 [[1, 160, 8, 8]] [1, 160, 8, 8] 0
Conv2D-46 [[1, 160, 8, 8]] [1, 960, 8, 8] 153,600
BatchNorm2D-46 [[1, 960, 8, 8]] [1, 960, 8, 8] 3,840
ReLU6-31 [[1, 960, 8, 8]] [1, 960, 8, 8] 0
Conv2D-47 [[1, 960, 8, 8]] [1, 960, 8, 8] 8,640
BatchNorm2D-47 [[1, 960, 8, 8]] [1, 960, 8, 8] 3,840
ReLU6-32 [[1, 960, 8, 8]] [1, 960, 8, 8] 0
Conv2D-48 [[1, 960, 8, 8]] [1, 160, 8, 8] 153,600
BatchNorm2D-48 [[1, 160, 8, 8]] [1, 160, 8, 8] 640
InvertedResidual-16 [[1, 160, 8, 8]] [1, 160, 8, 8] 0
Conv2D-49 [[1, 160, 8, 8]] [1, 960, 8, 8] 153,600
BatchNorm2D-49 [[1, 960, 8, 8]] [1, 960, 8, 8] 3,840
ReLU6-33 [[1, 960, 8, 8]] [1, 960, 8, 8] 0
Conv2D-50 [[1, 960, 8, 8]] [1, 960, 8, 8] 8,640
BatchNorm2D-50 [[1, 960, 8, 8]] [1, 960, 8, 8] 3,840
ReLU6-34 [[1, 960, 8, 8]] [1, 960, 8, 8] 0
Conv2D-51 [[1, 960, 8, 8]] [1, 320, 8, 8] 307,200
BatchNorm2D-51 [[1, 320, 8, 8]] [1, 320, 8, 8] 1,280
InvertedResidual-17 [[1, 160, 8, 8]] [1, 320, 8, 8] 0
Conv2D-52 [[1, 320, 8, 8]] [1, 1280, 8, 8] 409,600
BatchNorm2D-52 [[1, 1280, 8, 8]] [1, 1280, 8, 8] 5,120
ReLU6-35 [[1, 1280, 8, 8]] [1, 1280, 8, 8] 0
AdaptiveAvgPool2D-1 [[1, 1280, 8, 8]] [1, 1280, 1, 1] 0
Dropout-1 [[1, 1280]] [1, 1280] 0
Linear-1 [[1, 1280]] [1, 12] 15,372
===============================================================================
Total params: 2,273,356
Trainable params: 2,205,132
Non-trainable params: 68,224
-------------------------------------------------------------------------------
Input size (MB): 0.59
Forward/backward pass size (MB): 165.07
Params size (MB): 8.67
Estimated Total Size (MB): 174.34
-------------------------------------------------------------------------------
3.2 定义优化方法 (无需事先执行)
学习率策略和优化方法是两个密不可分的模块,学习率策略定义了学习率的变化方法,常见的包括固定学习率、分段学习率、余弦退火学习率、指数学习率和多项式学习率等;优化策略是如何进行学习率的学习和变化,常见的包括动量SGD、RMS、SGD和Adam等。
- 模块调用方法
-
源代码:getOptimizer.py
-
调用方法:
sys.path.append(r'D:\WorkSpace\DeepLearning\WebsiteV2 # 定义模块保存位置 from utils.getOptimizer import learning_rate_setting, optimizer_setting # 导入优化器模块 lr = learning_rate_setting(args=args, argsO=args['learning_strategy']) # 调用学习率函数配置学习率 optimizer = optimizer_setting(linear, lr, argsO=args['learning_strategy']) # 调用优化器函数配置优化器
# 以下代码为优化器测试代码,仅供演示和测试,本项目的运行无需事先执行。 if __name__ == '__main__': linear = paddle.nn.Linear(10, 10) lr = learning_rate_setting(args=args, argsO=args['learning_strategy']) optimizer = optimizer_setting(linear, lr, argsO=args['learning_strategy']) if args['learning_strategy']['optimizer_strategy'] == 'fixed': print('learning = {}'.format(args['learning_strategy']['learning_rate'])) else: for epoch in range(10): for batch_id in range(10): x = paddle.uniform([10, 10]) out = linear(x) loss = paddle.mean(out) loss.backward() optimizer.step() optimizer.clear_gradients() # lr.step() # 按照batch进行学习率更新 lr.step() # 按照epoch进行学习率更新
当前学习率策略为: Momentum + CosineAnnealingDecay, 初始学习率为:0.001.
3.3 定义验证函数 (无需事先执行)
验证函数有两个功能,一是在训练过程中实时地对验证集进行测试(在线测试),二是在训练结束后对测试集进行测试(离线测试)。
验证函数的具体流程包括:
- 初始化输出变量,包括top1精度,top5精度和损失
- 基于批次batch的结构进行循环测试,具体包括:
1). 定义输入层(image,label),图像输入维度 [batch, channel, Width, Height] (-1,imgChannel,imgSize,imgSize),标签输入维度 [batch, 1] (-1,1)
2). 定义输出层:在paddle2.0+中,我们使用model.eval_batch([image],[label])进行评估验证,该函数可以直接输出精度和损失,但在运行前需要使用model.prepare()进行配置。值得注意的,在计算测试集精度的时候,需要对每个批次的精度/损失求取平均值。
在定义evaluate()函数的时候,我们需要为其指定两个必要参数:model是测试的模型,data_reader是迭代的数据读取器,取值为val_reader(), test_reader(),分别对验证集和测试集。此处验证集和测试集数据的测试过程是相同的,只是所使用的数据不同;此外,可选参数verbose用于定义是否在测试的时候输出过程
- 模块调用方法
-
源代码:evaluate.py
-
调用方法:
sys.path.append(r'D:\WorkSpace\DeepLearning\WebsiteV2 # 定义模块保存位置 from utils.evaluate import evaluate # 导入优化器模块 avg_loss, avg_acc_top1, avg_acc_top5 = evaluate(model, val_reader(), verbose=0) # 调用方法
# 以下代码为优化器测试代码,仅供演示和测试,本项目的运行无需事先执行。 # 开启本项目的验证测试需要在模型完成一次训练后,并将生成的模型拷贝至ExpDeployments目录;或使用如下Project011的运行结果进行测试 if __name__ == '__main__': deployment_checkpoint_model = r'D:\Workspace\ExpDeployments\Project011AlexNetButterfly\checkpoint_models\Butterfly_Alexnet_final' from utils.models.AlexNet import AlexNet # 载入自定义AlexNet模型 try: # 设置输入样本的维度 input_spec = InputSpec(shape=[None] + args['input_size'], dtype='float32', name='image') label_spec = InputSpec(shape=[None, 1], dtype='int64', name='label') # 载入模型 network = eval("paddle.vision.models." + args['architecture'] + "(num_classes=args['class_dim'])") # network = AlexNet(num_classes=args['class_dim']) # network = paddle.vision.models.mobilenet_v2(num_classes=args['class_dim']) model = paddle.Model(network, input_spec, label_spec) # 模型实例化 model.load(deployment_checkpoint_model) # 载入调优模型的参数 model.prepare(loss=paddle.nn.CrossEntropyLoss(), # 设置loss metrics=paddle.metric.Accuracy(topk=(1,5))) # 设置评价指标 # 执行评估函数,并输出验证集样本的损失和精度 print('开始评估...') avg_loss, avg_acc_top1, avg_acc_top5 = evaluate(model, val_reader(), verbose=1) print('\r[验证集] 损失: {:.5f}, top1精度:{:.5f}, top5精度为:{:.5f}\n'.format(avg_loss, avg_acc_top1, avg_acc_top5), end='') except: print('数据不存在, 跳过测试')
数据不存在, 跳过测试
3.4 模型训练及在线测试
在Paddle 2.0+动态图模式下,动态图模式被作为默认进程,同时动态图守护进程 fluid.dygraph.guard(PLACE) 被取消。
训练部分的具体流程包括:
- 定义输入层(image, label): 图像输入维度 [batch, channel, Width, Height] (-1,imgChannel,imgSize,imgSize),标签输入维度 [batch, 1] (-1,1)
- 实例化网络模型: model = Alexnet()
- 定义学习率策略和优化算法
- 定义输出层,即模型准备函数model.prepare()
- 基于"周期-批次"两层循环进行训练
- 记录训练过程的结果,并定期输出模型。此处,我们分别保存用于调优和恢复训练的checkpoint_model模型和用于部署与预测的final_model模型
- 模块调用方法
-
源代码:train.py
-
调用方法:
sys.path.append(r'D:\WorkSpace\DeepLearning\WebsiteV2 # 定义模块保存位置 from utils.train import train # 导入训练模块 # 各参数的详细调用请参考源代码 visualization_log = train(model, args=args, train_reader=train_reader, val_reader=val_reader, logger=logger) # 调用方法
#### 训练主函数 ########################################################3 if __name__ == '__main__': from paddle.static import InputSpec ##### 1. 输出相关提示语,准备开启训练进程 ############################ # 1.1 输出系统硬件信息 logger.info('系统基本信息:') logger.info(system_info) # 1.2 输出训练的超参数信息 data = json.dumps(args, indent=4, ensure_ascii=False, sort_keys=False, separators=(',', ':')) # 格式化字典格式的参数列表 logger.info(data) # 1.3 载入官方标准模型,若不存在则会自动进行下载,pretrained=True|False控制是否使用Imagenet预训练参数 if args['pretrained'] == True: logger.info('载入Imagenet-{}预训练模型完毕,开始微调训练(fine-tune)。'.format(args['architecture'])) elif args['pretrained'] == False: logger.info('载入{}模型完毕,从初始状态开始训练。'.format(args['architecture'])) # 1.4 提示语:启动训练过程 logger.info('训练参数保存完毕,使用{}模型, 训练{}数据, 训练集{}, 启动训练...'.format(args['architecture'],args['dataset_name'],args['training_data'])) ##### 2. 启动训练进程 ################# # 2.1 根据配置文件,自动设置训练数据来源,使用trainval时只进行训练,不输出验证结果 if args['training_data'] == 'trainval': train_reader = trainval_reader elif args['training_data'] == 'train': train_reader = train_reader # 2.2 设置输入样本的维度 input_spec = InputSpec(shape=[None, 3, 227, 227], dtype='float32', name='image') label_spec = InputSpec(shape=[None, 1], dtype='int64', name='label') # 2.3 初始化模型 network = eval("paddle.vision.models." + args['architecture'] + "(num_classes=args['class_dim'], pretrained=args['pretrained'])") model = paddle.Model(network, input_spec, label_spec) logger.info('模型参数信息:') logger.info(model.summary()) # 是否显示神经网络的具体信息 # 2.4 设置学习率、优化器、损失函数和评价指标 lr = learning_rate_setting(args=args) optimizer = optimizer_setting(model, lr) model.prepare(optimizer, paddle.nn.CrossEntropyLoss(), paddle.metric.Accuracy(topk=(1,5))) # 2.5 启动训练过程 visualization_log = train(model, args=args, train_reader=train_reader, val_reader=val_reader, logger=logger) print('训练完毕,结果路径{}.'.format(args['results_path']['final_models_path'])) ##### 3. 输出训练结果 ######################### # 输出训练过程图 draw_process('Training Process', 'Train Loss', 'Train Accuracy', iters=visualization_log['all_train_iters'], losses=visualization_log['all_train_losses'], accuracies=visualization_log['all_train_accs_top1'], final_figures_path=args['results_path']['final_figures_path'], figurename=args['model_name'] + '_train', isShow=True) if args['training_data'] != 'trainval': draw_process('Validation Results', 'Validation Loss', 'Validation Accuracy', iters=visualization_log['all_test_iters'], losses=visualization_log['all_test_losses'], accuracies=visualization_log['all_test_accs_top1'], final_figures_path=args['results_path']['final_figures_path'], figurename=args['model_name'] + '_test', isShow=True) logger.info('Done.')
2022-10-15 21:37:07,440 - INFO: 系统基本信息:
2022-10-15 21:37:07,441 - INFO: {
"操作系统":"Windows-10-10.0.22000-SP0",
"CPU":"Intel(R) Core(TM) i7-9700 CPU @ 3.00GHz",
"内存":"7.96G/15.88G (50.10%)",
"GPU":"b'GeForce RTX 2080' 1.25G/8.00G (0.16%)",
"CUDA/cuDNN":"10.2 / 7.6.5",
"Paddle":"2.3.2"
}
2022-10-15 21:37:07,442 - INFO: {
"project_name":"Project013TransferLearningZodiac",
"dataset_name":"Zodiac",
"architecture":"mobilenet_v2",
"training_data":"train",
"starting_time":"202210152137",
"input_size":[
3,
227,
227
],
"mean_value":[
0.485,
0.456,
0.406
],
"std_value":[
0.229,
0.224,
0.225
],
"num_trainval":7840,
"num_train":7190,
"num_val":650,
"num_test":660,
"class_dim":12,
"label_dict":{
"0":"dog",
"1":"dragon",
"2":"goat",
"3":"horse",
"4":"monkey",
"5":"ox",
"6":"pig",
"7":"rabbit",
"8":"ratt",
"9":"rooster",
"10":"snake",
"11":"tiger"
},
"total_epoch":10,
"batch_size":64,
"log_interval":10,
"eval_interval":1,
"checkpointed":false,
"checkpoint_train":false,
"checkpoint_model":"Butterfly_Mobilenetv2",
"checkpoint_time":"202102182058",
"pretrained":true,
"pretrained_model":"API",
"dataset_root_path":"D:\\Workspace\\ExpDatasets\\Zodiac",
"result_root_path":"D:\\Workspace\\ExpResults\\",
"deployment_root_path":"D:\\Workspace\\ExpDeployments\\",
"useGPU":true,
"learning_strategy":{
"optimizer_strategy":"Momentum",
"learning_rate_strategy":"CosineAnnealingDecay",
"learning_rate":0.001,
"momentum":0.9,
"Piecewise_boundaries":[
60,
80,
90
],
"Piecewise_values":[
0.01,
0.001,
0.0001,
1e-05
],
"Exponential_gamma":0.9,
"Polynomial_decay_steps":10,
"verbose":false
},
"results_path":{
"checkpoint_models_path":"D:\\Workspace\\ExpResults\\Project013TransferLearningZodiac\\checkpoint_models",
"final_figures_path":"D:\\Workspace\\ExpResults\\Project013TransferLearningZodiac\\final_figures",
"final_models_path":"D:\\Workspace\\ExpResults\\Project013TransferLearningZodiac\\final_models",
"logs_path":"D:\\Workspace\\ExpResults\\Project013TransferLearningZodiac\\logs"
},
"deployments_path":{
"deployment_root_path":null,
"deployment_checkpoint_model":"D:\\Workspace\\ExpDeployments\\Project013TransferLearningZodiac\\checkpoint_models\\Zodiac_mobilenet_v2_final",
"deployment_final_model":"D:\\Workspace\\ExpDeployments\\Project013TransferLearningZodiac\\final_models\\Zodiac_mobilenet_v2_final",
"deployment_final_figures_path ":null,
"deployment_logs_path":"D:\\Workspace\\ExpDeployments\\Project013TransferLearningZodiac\\logs",
"deployment_pretrained_model":"D:\\Workspace\\ExpDeployments\\Project013TransferLearningZodiac\\pretrained_dir\\API",
"deployment_final_figures_path":"D:\\Workspace\\ExpDeployments\\Project013TransferLearningZodiac\\final_figures"
},
"model_name":"Zodiac_mobilenet_v2"
}
2022-10-15 21:37:07,443 - INFO: 载入Imagenet-mobilenet_v2预训练模型完毕,开始微调训练(fine-tune)。
2022-10-15 21:37:07,443 - INFO: 训练参数保存完毕,使用mobilenet_v2模型, 训练Zodiac数据, 训练集train, 启动训练...
2022-10-15 21:37:07,524 - INFO: unique_endpoints {''}
2022-10-15 21:37:07,525 - INFO: File C:\Users\Administrator/.cache/paddle/hapi/weights\mobilenet_v2_x1.0.pdparams md5 checking...
2022-10-15 21:37:07,570 - INFO: Found C:\Users\Administrator/.cache/paddle/hapi/weights\mobilenet_v2_x1.0.pdparams
2022-10-15 21:37:07,756 - INFO: 模型参数信息:
2022-10-15 21:37:07,796 - INFO: {'total_params': 2273356, 'trainable_params': 2205132}
-------------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===============================================================================
Conv2D-105 [[1, 3, 227, 227]] [1, 32, 114, 114] 864
BatchNorm2D-105 [[1, 32, 114, 114]] [1, 32, 114, 114] 128
ReLU6-71 [[1, 32, 114, 114]] [1, 32, 114, 114] 0
Conv2D-106 [[1, 32, 114, 114]] [1, 32, 114, 114] 288
BatchNorm2D-106 [[1, 32, 114, 114]] [1, 32, 114, 114] 128
ReLU6-72 [[1, 32, 114, 114]] [1, 32, 114, 114] 0
Conv2D-107 [[1, 32, 114, 114]] [1, 16, 114, 114] 512
BatchNorm2D-107 [[1, 16, 114, 114]] [1, 16, 114, 114] 64
InvertedResidual-35 [[1, 32, 114, 114]] [1, 16, 114, 114] 0
Conv2D-108 [[1, 16, 114, 114]] [1, 96, 114, 114] 1,536
BatchNorm2D-108 [[1, 96, 114, 114]] [1, 96, 114, 114] 384
ReLU6-73 [[1, 96, 114, 114]] [1, 96, 114, 114] 0
Conv2D-109 [[1, 96, 114, 114]] [1, 96, 57, 57] 864
BatchNorm2D-109 [[1, 96, 57, 57]] [1, 96, 57, 57] 384
ReLU6-74 [[1, 96, 57, 57]] [1, 96, 57, 57] 0
Conv2D-110 [[1, 96, 57, 57]] [1, 24, 57, 57] 2,304
BatchNorm2D-110 [[1, 24, 57, 57]] [1, 24, 57, 57] 96
InvertedResidual-36 [[1, 16, 114, 114]] [1, 24, 57, 57] 0
Conv2D-111 [[1, 24, 57, 57]] [1, 144, 57, 57] 3,456
BatchNorm2D-111 [[1, 144, 57, 57]] [1, 144, 57, 57] 576
ReLU6-75 [[1, 144, 57, 57]] [1, 144, 57, 57] 0
Conv2D-112 [[1, 144, 57, 57]] [1, 144, 57, 57] 1,296
BatchNorm2D-112 [[1, 144, 57, 57]] [1, 144, 57, 57] 576
ReLU6-76 [[1, 144, 57, 57]] [1, 144, 57, 57] 0
Conv2D-113 [[1, 144, 57, 57]] [1, 24, 57, 57] 3,456
BatchNorm2D-113 [[1, 24, 57, 57]] [1, 24, 57, 57] 96
InvertedResidual-37 [[1, 24, 57, 57]] [1, 24, 57, 57] 0
Conv2D-114 [[1, 24, 57, 57]] [1, 144, 57, 57] 3,456
BatchNorm2D-114 [[1, 144, 57, 57]] [1, 144, 57, 57] 576
ReLU6-77 [[1, 144, 57, 57]] [1, 144, 57, 57] 0
Conv2D-115 [[1, 144, 57, 57]] [1, 144, 29, 29] 1,296
BatchNorm2D-115 [[1, 144, 29, 29]] [1, 144, 29, 29] 576
ReLU6-78 [[1, 144, 29, 29]] [1, 144, 29, 29] 0
Conv2D-116 [[1, 144, 29, 29]] [1, 32, 29, 29] 4,608
BatchNorm2D-116 [[1, 32, 29, 29]] [1, 32, 29, 29] 128
InvertedResidual-38 [[1, 24, 57, 57]] [1, 32, 29, 29] 0
Conv2D-117 [[1, 32, 29, 29]] [1, 192, 29, 29] 6,144
BatchNorm2D-117 [[1, 192, 29, 29]] [1, 192, 29, 29] 768
ReLU6-79 [[1, 192, 29, 29]] [1, 192, 29, 29] 0
Conv2D-118 [[1, 192, 29, 29]] [1, 192, 29, 29] 1,728
BatchNorm2D-118 [[1, 192, 29, 29]] [1, 192, 29, 29] 768
ReLU6-80 [[1, 192, 29, 29]] [1, 192, 29, 29] 0
Conv2D-119 [[1, 192, 29, 29]] [1, 32, 29, 29] 6,144
BatchNorm2D-119 [[1, 32, 29, 29]] [1, 32, 29, 29] 128
InvertedResidual-39 [[1, 32, 29, 29]] [1, 32, 29, 29] 0
Conv2D-120 [[1, 32, 29, 29]] [1, 192, 29, 29] 6,144
BatchNorm2D-120 [[1, 192, 29, 29]] [1, 192, 29, 29] 768
ReLU6-81 [[1, 192, 29, 29]] [1, 192, 29, 29] 0
Conv2D-121 [[1, 192, 29, 29]] [1, 192, 29, 29] 1,728
BatchNorm2D-121 [[1, 192, 29, 29]] [1, 192, 29, 29] 768
ReLU6-82 [[1, 192, 29, 29]] [1, 192, 29, 29] 0
Conv2D-122 [[1, 192, 29, 29]] [1, 32, 29, 29] 6,144
BatchNorm2D-122 [[1, 32, 29, 29]] [1, 32, 29, 29] 128
InvertedResidual-40 [[1, 32, 29, 29]] [1, 32, 29, 29] 0
Conv2D-123 [[1, 32, 29, 29]] [1, 192, 29, 29] 6,144
BatchNorm2D-123 [[1, 192, 29, 29]] [1, 192, 29, 29] 768
ReLU6-83 [[1, 192, 29, 29]] [1, 192, 29, 29] 0
Conv2D-124 [[1, 192, 29, 29]] [1, 192, 15, 15] 1,728
BatchNorm2D-124 [[1, 192, 15, 15]] [1, 192, 15, 15] 768
ReLU6-84 [[1, 192, 15, 15]] [1, 192, 15, 15] 0
Conv2D-125 [[1, 192, 15, 15]] [1, 64, 15, 15] 12,288
BatchNorm2D-125 [[1, 64, 15, 15]] [1, 64, 15, 15] 256
InvertedResidual-41 [[1, 32, 29, 29]] [1, 64, 15, 15] 0
Conv2D-126 [[1, 64, 15, 15]] [1, 384, 15, 15] 24,576
BatchNorm2D-126 [[1, 384, 15, 15]] [1, 384, 15, 15] 1,536
ReLU6-85 [[1, 384, 15, 15]] [1, 384, 15, 15] 0
Conv2D-127 [[1, 384, 15, 15]] [1, 384, 15, 15] 3,456
BatchNorm2D-127 [[1, 384, 15, 15]] [1, 384, 15, 15] 1,536
ReLU6-86 [[1, 384, 15, 15]] [1, 384, 15, 15] 0
Conv2D-128 [[1, 384, 15, 15]] [1, 64, 15, 15] 24,576
BatchNorm2D-128 [[1, 64, 15, 15]] [1, 64, 15, 15] 256
InvertedResidual-42 [[1, 64, 15, 15]] [1, 64, 15, 15] 0
Conv2D-129 [[1, 64, 15, 15]] [1, 384, 15, 15] 24,576
BatchNorm2D-129 [[1, 384, 15, 15]] [1, 384, 15, 15] 1,536
ReLU6-87 [[1, 384, 15, 15]] [1, 384, 15, 15] 0
Conv2D-130 [[1, 384, 15, 15]] [1, 384, 15, 15] 3,456
BatchNorm2D-130 [[1, 384, 15, 15]] [1, 384, 15, 15] 1,536
ReLU6-88 [[1, 384, 15, 15]] [1, 384, 15, 15] 0
Conv2D-131 [[1, 384, 15, 15]] [1, 64, 15, 15] 24,576
BatchNorm2D-131 [[1, 64, 15, 15]] [1, 64, 15, 15] 256
InvertedResidual-43 [[1, 64, 15, 15]] [1, 64, 15, 15] 0
Conv2D-132 [[1, 64, 15, 15]] [1, 384, 15, 15] 24,576
BatchNorm2D-132 [[1, 384, 15, 15]] [1, 384, 15, 15] 1,536
ReLU6-89 [[1, 384, 15, 15]] [1, 384, 15, 15] 0
Conv2D-133 [[1, 384, 15, 15]] [1, 384, 15, 15] 3,456
BatchNorm2D-133 [[1, 384, 15, 15]] [1, 384, 15, 15] 1,536
ReLU6-90 [[1, 384, 15, 15]] [1, 384, 15, 15] 0
Conv2D-134 [[1, 384, 15, 15]] [1, 64, 15, 15] 24,576
BatchNorm2D-134 [[1, 64, 15, 15]] [1, 64, 15, 15] 256
InvertedResidual-44 [[1, 64, 15, 15]] [1, 64, 15, 15] 0
Conv2D-135 [[1, 64, 15, 15]] [1, 384, 15, 15] 24,576
BatchNorm2D-135 [[1, 384, 15, 15]] [1, 384, 15, 15] 1,536
ReLU6-91 [[1, 384, 15, 15]] [1, 384, 15, 15] 0
Conv2D-136 [[1, 384, 15, 15]] [1, 384, 15, 15] 3,456
BatchNorm2D-136 [[1, 384, 15, 15]] [1, 384, 15, 15] 1,536
ReLU6-92 [[1, 384, 15, 15]] [1, 384, 15, 15] 0
Conv2D-137 [[1, 384, 15, 15]] [1, 96, 15, 15] 36,864
BatchNorm2D-137 [[1, 96, 15, 15]] [1, 96, 15, 15] 384
InvertedResidual-45 [[1, 64, 15, 15]] [1, 96, 15, 15] 0
Conv2D-138 [[1, 96, 15, 15]] [1, 576, 15, 15] 55,296
BatchNorm2D-138 [[1, 576, 15, 15]] [1, 576, 15, 15] 2,304
ReLU6-93 [[1, 576, 15, 15]] [1, 576, 15, 15] 0
Conv2D-139 [[1, 576, 15, 15]] [1, 576, 15, 15] 5,184
BatchNorm2D-139 [[1, 576, 15, 15]] [1, 576, 15, 15] 2,304
ReLU6-94 [[1, 576, 15, 15]] [1, 576, 15, 15] 0
Conv2D-140 [[1, 576, 15, 15]] [1, 96, 15, 15] 55,296
BatchNorm2D-140 [[1, 96, 15, 15]] [1, 96, 15, 15] 384
InvertedResidual-46 [[1, 96, 15, 15]] [1, 96, 15, 15] 0
Conv2D-141 [[1, 96, 15, 15]] [1, 576, 15, 15] 55,296
BatchNorm2D-141 [[1, 576, 15, 15]] [1, 576, 15, 15] 2,304
ReLU6-95 [[1, 576, 15, 15]] [1, 576, 15, 15] 0
Conv2D-142 [[1, 576, 15, 15]] [1, 576, 15, 15] 5,184
BatchNorm2D-142 [[1, 576, 15, 15]] [1, 576, 15, 15] 2,304
ReLU6-96 [[1, 576, 15, 15]] [1, 576, 15, 15] 0
Conv2D-143 [[1, 576, 15, 15]] [1, 96, 15, 15] 55,296
BatchNorm2D-143 [[1, 96, 15, 15]] [1, 96, 15, 15] 384
InvertedResidual-47 [[1, 96, 15, 15]] [1, 96, 15, 15] 0
Conv2D-144 [[1, 96, 15, 15]] [1, 576, 15, 15] 55,296
BatchNorm2D-144 [[1, 576, 15, 15]] [1, 576, 15, 15] 2,304
ReLU6-97 [[1, 576, 15, 15]] [1, 576, 15, 15] 0
Conv2D-145 [[1, 576, 15, 15]] [1, 576, 8, 8] 5,184
BatchNorm2D-145 [[1, 576, 8, 8]] [1, 576, 8, 8] 2,304
ReLU6-98 [[1, 576, 8, 8]] [1, 576, 8, 8] 0
Conv2D-146 [[1, 576, 8, 8]] [1, 160, 8, 8] 92,160
BatchNorm2D-146 [[1, 160, 8, 8]] [1, 160, 8, 8] 640
InvertedResidual-48 [[1, 96, 15, 15]] [1, 160, 8, 8] 0
Conv2D-147 [[1, 160, 8, 8]] [1, 960, 8, 8] 153,600
BatchNorm2D-147 [[1, 960, 8, 8]] [1, 960, 8, 8] 3,840
ReLU6-99 [[1, 960, 8, 8]] [1, 960, 8, 8] 0
Conv2D-148 [[1, 960, 8, 8]] [1, 960, 8, 8] 8,640
BatchNorm2D-148 [[1, 960, 8, 8]] [1, 960, 8, 8] 3,840
ReLU6-100 [[1, 960, 8, 8]] [1, 960, 8, 8] 0
Conv2D-149 [[1, 960, 8, 8]] [1, 160, 8, 8] 153,600
BatchNorm2D-149 [[1, 160, 8, 8]] [1, 160, 8, 8] 640
InvertedResidual-49 [[1, 160, 8, 8]] [1, 160, 8, 8] 0
Conv2D-150 [[1, 160, 8, 8]] [1, 960, 8, 8] 153,600
BatchNorm2D-150 [[1, 960, 8, 8]] [1, 960, 8, 8] 3,840
ReLU6-101 [[1, 960, 8, 8]] [1, 960, 8, 8] 0
Conv2D-151 [[1, 960, 8, 8]] [1, 960, 8, 8] 8,640
BatchNorm2D-151 [[1, 960, 8, 8]] [1, 960, 8, 8] 3,840
ReLU6-102 [[1, 960, 8, 8]] [1, 960, 8, 8] 0
Conv2D-152 [[1, 960, 8, 8]] [1, 160, 8, 8] 153,600
BatchNorm2D-152 [[1, 160, 8, 8]] [1, 160, 8, 8] 640
InvertedResidual-50 [[1, 160, 8, 8]] [1, 160, 8, 8] 0
Conv2D-153 [[1, 160, 8, 8]] [1, 960, 8, 8] 153,600
BatchNorm2D-153 [[1, 960, 8, 8]] [1, 960, 8, 8] 3,840
ReLU6-103 [[1, 960, 8, 8]] [1, 960, 8, 8] 0
Conv2D-154 [[1, 960, 8, 8]] [1, 960, 8, 8] 8,640
BatchNorm2D-154 [[1, 960, 8, 8]] [1, 960, 8, 8] 3,840
ReLU6-104 [[1, 960, 8, 8]] [1, 960, 8, 8] 0
Conv2D-155 [[1, 960, 8, 8]] [1, 320, 8, 8] 307,200
BatchNorm2D-155 [[1, 320, 8, 8]] [1, 320, 8, 8] 1,280
InvertedResidual-51 [[1, 160, 8, 8]] [1, 320, 8, 8] 0
Conv2D-156 [[1, 320, 8, 8]] [1, 1280, 8, 8] 409,600
BatchNorm2D-156 [[1, 1280, 8, 8]] [1, 1280, 8, 8] 5,120
ReLU6-105 [[1, 1280, 8, 8]] [1, 1280, 8, 8] 0
AdaptiveAvgPool2D-3 [[1, 1280, 8, 8]] [1, 1280, 1, 1] 0
Dropout-3 [[1, 1280]] [1, 1280] 0
Linear-4 [[1, 1280]] [1, 12] 15,372
===============================================================================
Total params: 2,273,356
Trainable params: 2,205,132
Non-trainable params: 68,224
-------------------------------------------------------------------------------
Input size (MB): 0.59
Forward/backward pass size (MB): 165.07
Params size (MB): 8.67
Estimated Total Size (MB): 174.34
-------------------------------------------------------------------------------
当前学习率策略为: Adam + CosineAnnealingDecay, 初始学习率为:0.001.
Epoch 0: CosineAnnealingDecay set learning rate to 0.001.
c:\Users\Administrator\anaconda3\lib\site-packages\paddle\nn\layer\norm.py:653: UserWarning: When training, we now always track global mean and variance.
warnings.warn(
2022-10-15 21:37:20,936 - INFO: Epoch:1/10, batch:10, train_loss:[1.90069], acc_top1:[0.35938], acc_top5:[0.82812](13.14s)
2022-10-15 21:37:33,308 - INFO: Epoch:1/10, batch:20, train_loss:[1.67285], acc_top1:[0.45312], acc_top5:[0.92188](12.37s)
2022-10-15 21:37:46,745 - INFO: Epoch:1/10, batch:30, train_loss:[1.66951], acc_top1:[0.43750], acc_top5:[0.89062](13.44s)
2022-10-15 21:37:59,983 - INFO: Epoch:1/10, batch:40, train_loss:[1.69990], acc_top1:[0.46875], acc_top5:[0.84375](13.24s)
2022-10-15 21:38:12,609 - INFO: Epoch:1/10, batch:50, train_loss:[1.37996], acc_top1:[0.50000], acc_top5:[0.89062](12.63s)
2022-10-15 21:38:26,137 - INFO: Epoch:1/10, batch:60, train_loss:[1.28067], acc_top1:[0.60938], acc_top5:[0.87500](13.53s)
2022-10-15 21:38:37,554 - INFO: Epoch:1/10, batch:70, train_loss:[1.23229], acc_top1:[0.64062], acc_top5:[0.84375](11.42s)
2022-10-15 21:38:49,420 - INFO: Epoch:1/10, batch:80, train_loss:[1.28323], acc_top1:[0.59375], acc_top5:[0.85938](11.87s)
2022-10-15 21:39:01,785 - INFO: Epoch:1/10, batch:90, train_loss:[1.02347], acc_top1:[0.65625], acc_top5:[0.92188](12.36s)
2022-10-15 21:39:12,994 - INFO: Epoch:1/10, batch:100, train_loss:[1.16567], acc_top1:[0.65625], acc_top5:[0.93750](11.21s)
2022-10-15 21:39:26,052 - INFO: Epoch:1/10, batch:110, train_loss:[1.34003], acc_top1:[0.54688], acc_top5:[0.92188](13.06s)
2022-10-15 21:39:38,692 - INFO: [validation] Epoch:1/10, val_loss:[0.01638], val_top1:[0.67385], val_top5:[0.95077]
c:\Users\Administrator\anaconda3\lib\site-packages\paddle\fluid\dygraph\dygraph_to_static\convert_call_func.py:93: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray
func_in_dict = func == v
c:\Users\Administrator\anaconda3\lib\site-packages\paddle\fluid\layers\math_op_patch.py:336: UserWarning: c:\Users\Administrator\anaconda3\lib\site-packages\paddle\vision\models\mobilenetv2.py:70
The behavior of expression A + B has been unified with elementwise_add(X, Y, axis=-1) from Paddle 2.0. If your code works well in the older versions but crashes in this version, try to use elementwise_add(X, Y, axis=0) instead of A + B. This transitional warning will be dropped in the future.
warnings.warn(
2022-10-15 21:39:39,797 - INFO: 已保存当前测试模型(epoch=1)为最优模型:Zodiac_mobilenet_v2_final
2022-10-15 21:39:39,798 - INFO: 最优top1测试精度:0.67385 (epoch=1)
2022-10-15 21:39:39,799 - INFO: 训练完成,最终性能accuracy=0.67385(epoch=1), 总耗时152.00s, 已将其保存为:Zodiac_mobilenet_v2_final
2022-10-15 21:39:50,130 - INFO: Epoch:2/10, batch:120, train_loss:[0.97352], acc_top1:[0.65625], acc_top5:[0.95312](24.08s)
2022-10-15 21:40:03,550 - INFO: Epoch:2/10, batch:130, train_loss:[1.17883], acc_top1:[0.60938], acc_top5:[0.93750](13.42s)
2022-10-15 21:40:15,082 - INFO: Epoch:2/10, batch:140, train_loss:[1.21900], acc_top1:[0.64062], acc_top5:[0.87500](11.53s)
2022-10-15 21:40:28,610 - INFO: Epoch:2/10, batch:150, train_loss:[1.18754], acc_top1:[0.62500], acc_top5:[0.92188](13.53s)
2022-10-15 21:40:41,518 - INFO: Epoch:2/10, batch:160, train_loss:[0.98892], acc_top1:[0.67188], acc_top5:[0.93750](12.91s)
2022-10-15 21:40:52,975 - INFO: Epoch:2/10, batch:170, train_loss:[1.24128], acc_top1:[0.53125], acc_top5:[0.93750](11.46s)
2022-10-15 21:41:04,548 - INFO: Epoch:2/10, batch:180, train_loss:[1.27410], acc_top1:[0.56250], acc_top5:[0.90625](11.57s)
2022-10-15 21:41:17,861 - INFO: Epoch:2/10, batch:190, train_loss:[1.06652], acc_top1:[0.64062], acc_top5:[0.95312](13.31s)
2022-10-15 21:41:29,506 - INFO: Epoch:2/10, batch:200, train_loss:[0.99669], acc_top1:[0.59375], acc_top5:[0.93750](11.64s)
2022-10-15 21:41:41,398 - INFO: Epoch:2/10, batch:210, train_loss:[1.00127], acc_top1:[0.68750], acc_top5:[0.90625](11.89s)
2022-10-15 21:41:55,194 - INFO: Epoch:2/10, batch:220, train_loss:[0.89258], acc_top1:[0.73438], acc_top5:[0.93750](13.80s)
2022-10-15 21:42:11,028 - INFO: [validation] Epoch:2/10, val_loss:[0.01346], val_top1:[0.72923], val_top5:[0.95538]
2022-10-15 21:42:12,037 - INFO: 已保存当前测试模型(epoch=2)为最优模型:Zodiac_mobilenet_v2_final
2022-10-15 21:42:12,038 - INFO: 最优top1测试精度:0.72923 (epoch=2)
2022-10-15 21:42:12,038 - INFO: 训练完成,最终性能accuracy=0.72923(epoch=2), 总耗时304.24s, 已将其保存为:Zodiac_mobilenet_v2_final
2022-10-15 21:42:19,672 - INFO: Epoch:3/10, batch:230, train_loss:[0.94152], acc_top1:[0.65625], acc_top5:[0.96875](24.48s)
2022-10-15 21:42:32,887 - INFO: Epoch:3/10, batch:240, train_loss:[0.79751], acc_top1:[0.73438], acc_top5:[0.93750](13.21s)
2022-10-15 21:42:46,043 - INFO: Epoch:3/10, batch:250, train_loss:[1.04685], acc_top1:[0.70312], acc_top5:[0.95312](13.16s)
2022-10-15 21:42:59,116 - INFO: Epoch:3/10, batch:260, train_loss:[1.22611], acc_top1:[0.56250], acc_top5:[0.89062](13.07s)
2022-10-15 21:43:11,976 - INFO: Epoch:3/10, batch:270, train_loss:[1.04515], acc_top1:[0.67188], acc_top5:[0.92188](12.86s)
2022-10-15 21:43:23,918 - INFO: Epoch:3/10, batch:280, train_loss:[1.12440], acc_top1:[0.64062], acc_top5:[0.92188](11.94s)
2022-10-15 21:43:36,411 - INFO: Epoch:3/10, batch:290, train_loss:[1.02652], acc_top1:[0.62500], acc_top5:[0.93750](12.49s)
2022-10-15 21:43:47,960 - INFO: Epoch:3/10, batch:300, train_loss:[0.85053], acc_top1:[0.70312], acc_top5:[0.98438](11.55s)
2022-10-15 21:44:01,074 - INFO: Epoch:3/10, batch:310, train_loss:[0.87603], acc_top1:[0.71875], acc_top5:[0.95312](13.11s)
2022-10-15 21:44:13,157 - INFO: Epoch:3/10, batch:320, train_loss:[0.49464], acc_top1:[0.82812], acc_top5:[0.96875](12.08s)
2022-10-15 21:44:26,528 - INFO: Epoch:3/10, batch:330, train_loss:[0.74669], acc_top1:[0.78125], acc_top5:[0.96875](13.37s)
2022-10-15 21:44:43,850 - INFO: [validation] Epoch:3/10, val_loss:[0.01251], val_top1:[0.74769], val_top5:[0.95538]
2022-10-15 21:44:44,811 - INFO: 已保存当前测试模型(epoch=3)为最优模型:Zodiac_mobilenet_v2_final
2022-10-15 21:44:44,812 - INFO: 最优top1测试精度:0.74769 (epoch=3)
2022-10-15 21:44:44,813 - INFO: 训练完成,最终性能accuracy=0.74769(epoch=3), 总耗时457.02s, 已将其保存为:Zodiac_mobilenet_v2_final
2022-10-15 21:44:49,402 - INFO: Epoch:4/10, batch:340, train_loss:[1.10934], acc_top1:[0.64062], acc_top5:[0.89062](22.87s)
2022-10-15 21:45:01,853 - INFO: Epoch:4/10, batch:350, train_loss:[0.83510], acc_top1:[0.78125], acc_top5:[0.98438](12.45s)
2022-10-15 21:45:14,319 - INFO: Epoch:4/10, batch:360, train_loss:[0.86266], acc_top1:[0.71875], acc_top5:[0.95312](12.47s)
2022-10-15 21:45:27,578 - INFO: Epoch:4/10, batch:370, train_loss:[1.08172], acc_top1:[0.64062], acc_top5:[0.90625](13.26s)
2022-10-15 21:45:39,082 - INFO: Epoch:4/10, batch:380, train_loss:[0.89507], acc_top1:[0.67188], acc_top5:[0.96875](11.50s)
2022-10-15 21:45:50,931 - INFO: Epoch:4/10, batch:390, train_loss:[0.61764], acc_top1:[0.79688], acc_top5:[0.96875](11.85s)
2022-10-15 21:46:03,674 - INFO: Epoch:4/10, batch:400, train_loss:[0.99256], acc_top1:[0.67188], acc_top5:[0.96875](12.74s)
2022-10-15 21:46:16,624 - INFO: Epoch:4/10, batch:410, train_loss:[0.97828], acc_top1:[0.71875], acc_top5:[0.92188](12.95s)
2022-10-15 21:46:30,535 - INFO: Epoch:4/10, batch:420, train_loss:[0.80416], acc_top1:[0.70312], acc_top5:[0.96875](13.91s)
2022-10-15 21:46:43,594 - INFO: Epoch:4/10, batch:430, train_loss:[1.13662], acc_top1:[0.60938], acc_top5:[0.92188](13.06s)
2022-10-15 21:46:56,037 - INFO: Epoch:4/10, batch:440, train_loss:[0.81127], acc_top1:[0.76562], acc_top5:[0.96875](12.44s)
2022-10-15 21:47:16,847 - INFO: [validation] Epoch:4/10, val_loss:[0.01057], val_top1:[0.77846], val_top5:[0.97231]
2022-10-15 21:47:17,859 - INFO: 已保存当前测试模型(epoch=4)为最优模型:Zodiac_mobilenet_v2_final
2022-10-15 21:47:17,860 - INFO: 最优top1测试精度:0.77846 (epoch=4)
2022-10-15 21:47:17,860 - INFO: 训练完成,最终性能accuracy=0.77846(epoch=4), 总耗时610.06s, 已将其保存为:Zodiac_mobilenet_v2_final
2022-10-15 21:47:20,970 - INFO: Epoch:5/10, batch:450, train_loss:[1.10049], acc_top1:[0.64062], acc_top5:[0.87500](24.93s)
2022-10-15 21:47:32,811 - INFO: Epoch:5/10, batch:460, train_loss:[0.87662], acc_top1:[0.70312], acc_top5:[0.93750](11.84s)
2022-10-15 21:47:45,955 - INFO: Epoch:5/10, batch:470, train_loss:[0.92672], acc_top1:[0.65625], acc_top5:[0.89062](13.14s)
2022-10-15 21:47:58,466 - INFO: Epoch:5/10, batch:480, train_loss:[1.16143], acc_top1:[0.70312], acc_top5:[0.89062](12.51s)
2022-10-15 21:48:10,150 - INFO: Epoch:5/10, batch:490, train_loss:[0.81107], acc_top1:[0.76562], acc_top5:[0.96875](11.68s)
2022-10-15 21:48:22,280 - INFO: Epoch:5/10, batch:500, train_loss:[0.82532], acc_top1:[0.70312], acc_top5:[0.98438](12.13s)
2022-10-15 21:48:36,174 - INFO: Epoch:5/10, batch:510, train_loss:[0.95035], acc_top1:[0.71875], acc_top5:[0.98438](13.89s)
2022-10-15 21:48:48,890 - INFO: Epoch:5/10, batch:520, train_loss:[0.81344], acc_top1:[0.76562], acc_top5:[0.98438](12.72s)
2022-10-15 21:49:01,853 - INFO: Epoch:5/10, batch:530, train_loss:[1.07374], acc_top1:[0.62500], acc_top5:[0.95312](12.96s)
2022-10-15 21:49:15,523 - INFO: Epoch:5/10, batch:540, train_loss:[0.80372], acc_top1:[0.73438], acc_top5:[0.93750](13.67s)
2022-10-15 21:49:28,724 - INFO: Epoch:5/10, batch:550, train_loss:[0.94745], acc_top1:[0.68750], acc_top5:[0.96875](13.20s)
2022-10-15 21:49:41,363 - INFO: Epoch:5/10, batch:560, train_loss:[0.71733], acc_top1:[0.75000], acc_top5:[0.96875](12.64s)
2022-10-15 21:49:51,530 - INFO: [validation] Epoch:5/10, val_loss:[0.01006], val_top1:[0.77846], val_top5:[0.96923]
2022-10-15 21:49:51,530 - INFO: 最优top1测试精度:0.77846 (epoch=4)
2022-10-15 21:49:51,530 - INFO: 训练完成,最终性能accuracy=0.77846(epoch=4), 总耗时763.73s, 已将其保存为:Zodiac_mobilenet_v2_final
2022-10-15 21:50:05,149 - INFO: Epoch:6/10, batch:570, train_loss:[0.73211], acc_top1:[0.76562], acc_top5:[0.93750](23.79s)
2022-10-15 21:50:19,135 - INFO: Epoch:6/10, batch:580, train_loss:[0.73287], acc_top1:[0.75000], acc_top5:[0.95312](13.99s)
2022-10-15 21:50:32,096 - INFO: Epoch:6/10, batch:590, train_loss:[0.66739], acc_top1:[0.79688], acc_top5:[0.96875](12.96s)
2022-10-15 21:50:44,288 - INFO: Epoch:6/10, batch:600, train_loss:[0.87314], acc_top1:[0.68750], acc_top5:[0.96875](12.19s)
2022-10-15 21:50:56,489 - INFO: Epoch:6/10, batch:610, train_loss:[0.85797], acc_top1:[0.73438], acc_top5:[0.92188](12.20s)
2022-10-15 21:51:09,024 - INFO: Epoch:6/10, batch:620, train_loss:[0.88708], acc_top1:[0.67188], acc_top5:[0.93750](12.54s)
2022-10-15 21:51:20,980 - INFO: Epoch:6/10, batch:630, train_loss:[0.80561], acc_top1:[0.76562], acc_top5:[0.98438](11.96s)
2022-10-15 21:51:34,987 - INFO: Epoch:6/10, batch:640, train_loss:[0.80808], acc_top1:[0.73438], acc_top5:[0.95312](14.01s)
2022-10-15 21:51:48,246 - INFO: Epoch:6/10, batch:650, train_loss:[1.06750], acc_top1:[0.67188], acc_top5:[0.93750](13.26s)
2022-10-15 21:52:00,190 - INFO: Epoch:6/10, batch:660, train_loss:[1.00397], acc_top1:[0.68750], acc_top5:[0.95312](11.94s)
2022-10-15 21:52:12,064 - INFO: Epoch:6/10, batch:670, train_loss:[0.82336], acc_top1:[0.76562], acc_top5:[0.95312](11.88s)
2022-10-15 21:52:24,967 - INFO: [validation] Epoch:6/10, val_loss:[0.00929], val_top1:[0.80769], val_top5:[0.97077]
2022-10-15 21:52:25,960 - INFO: 已保存当前测试模型(epoch=6)为最优模型:Zodiac_mobilenet_v2_final
2022-10-15 21:52:25,961 - INFO: 最优top1测试精度:0.80769 (epoch=6)
2022-10-15 21:52:25,961 - INFO: 训练完成,最终性能accuracy=0.80769(epoch=6), 总耗时918.16s, 已将其保存为:Zodiac_mobilenet_v2_final
2022-10-15 21:52:37,370 - INFO: Epoch:7/10, batch:680, train_loss:[0.78673], acc_top1:[0.75000], acc_top5:[0.93750](25.31s)
2022-10-15 21:52:50,384 - INFO: Epoch:7/10, batch:690, train_loss:[0.90894], acc_top1:[0.70312], acc_top5:[0.93750](13.01s)
2022-10-15 21:53:04,954 - INFO: Epoch:7/10, batch:700, train_loss:[0.87277], acc_top1:[0.68750], acc_top5:[0.95312](14.57s)
2022-10-15 21:53:17,499 - INFO: Epoch:7/10, batch:710, train_loss:[0.76676], acc_top1:[0.71875], acc_top5:[0.96875](12.55s)
2022-10-15 21:53:28,588 - INFO: Epoch:7/10, batch:720, train_loss:[0.64217], acc_top1:[0.78125], acc_top5:[0.98438](11.09s)
2022-10-15 21:53:40,780 - INFO: Epoch:7/10, batch:730, train_loss:[1.03779], acc_top1:[0.65625], acc_top5:[0.93750](12.19s)
2022-10-15 21:53:52,589 - INFO: Epoch:7/10, batch:740, train_loss:[0.96022], acc_top1:[0.68750], acc_top5:[0.93750](11.81s)
2022-10-15 21:54:06,354 - INFO: Epoch:7/10, batch:750, train_loss:[0.97269], acc_top1:[0.65625], acc_top5:[0.92188](13.76s)
2022-10-15 21:54:19,550 - INFO: Epoch:7/10, batch:760, train_loss:[0.81942], acc_top1:[0.75000], acc_top5:[0.95312](13.20s)
2022-10-15 21:54:32,326 - INFO: Epoch:7/10, batch:770, train_loss:[0.61867], acc_top1:[0.81250], acc_top5:[0.96875](12.78s)
2022-10-15 21:54:44,298 - INFO: Epoch:7/10, batch:780, train_loss:[0.71930], acc_top1:[0.75000], acc_top5:[0.95312](11.97s)
2022-10-15 21:54:59,355 - INFO: [validation] Epoch:7/10, val_loss:[0.01031], val_top1:[0.80154], val_top5:[0.97538]
2022-10-15 21:54:59,355 - INFO: 最优top1测试精度:0.80769 (epoch=6)
2022-10-15 21:54:59,356 - INFO: 训练完成,最终性能accuracy=0.80769(epoch=6), 总耗时1071.56s, 已将其保存为:Zodiac_mobilenet_v2_final
2022-10-15 21:55:06,243 - INFO: Epoch:8/10, batch:790, train_loss:[0.66573], acc_top1:[0.78125], acc_top5:[0.96875](21.94s)
2022-10-15 21:55:18,301 - INFO: Epoch:8/10, batch:800, train_loss:[0.64515], acc_top1:[0.76562], acc_top5:[1.00000](12.06s)
2022-10-15 21:55:31,219 - INFO: Epoch:8/10, batch:810, train_loss:[0.86719], acc_top1:[0.75000], acc_top5:[0.92188](12.92s)
2022-10-15 21:55:46,051 - INFO: Epoch:8/10, batch:820, train_loss:[0.80408], acc_top1:[0.75000], acc_top5:[0.92188](14.83s)
2022-10-15 21:56:00,268 - INFO: Epoch:8/10, batch:830, train_loss:[0.64013], acc_top1:[0.79688], acc_top5:[0.98438](14.22s)
2022-10-15 21:56:12,456 - INFO: Epoch:8/10, batch:840, train_loss:[1.28000], acc_top1:[0.62500], acc_top5:[0.89062](12.19s)
2022-10-15 21:56:24,714 - INFO: Epoch:8/10, batch:850, train_loss:[0.88058], acc_top1:[0.68750], acc_top5:[0.96875](12.26s)
2022-10-15 21:56:36,767 - INFO: Epoch:8/10, batch:860, train_loss:[1.26459], acc_top1:[0.67188], acc_top5:[0.90625](12.05s)
2022-10-15 21:56:49,051 - INFO: Epoch:8/10, batch:870, train_loss:[0.60057], acc_top1:[0.75000], acc_top5:[0.98438](12.28s)
2022-10-15 21:56:59,658 - INFO: Epoch:8/10, batch:880, train_loss:[0.80651], acc_top1:[0.68750], acc_top5:[0.96875](10.61s)
2022-10-15 21:57:12,805 - INFO: Epoch:8/10, batch:890, train_loss:[0.88189], acc_top1:[0.73438], acc_top5:[0.92188](13.15s)
2022-10-15 21:57:30,539 - INFO: [validation] Epoch:8/10, val_loss:[0.00994], val_top1:[0.80462], val_top5:[0.98000]
2022-10-15 21:57:30,539 - INFO: 最优top1测试精度:0.80769 (epoch=6)
2022-10-15 21:57:30,540 - INFO: 训练完成,最终性能accuracy=0.80769(epoch=6), 总耗时1222.74s, 已将其保存为:Zodiac_mobilenet_v2_final
2022-10-15 21:57:35,060 - INFO: Epoch:9/10, batch:900, train_loss:[0.70748], acc_top1:[0.79688], acc_top5:[0.92188](22.25s)
2022-10-15 21:57:47,187 - INFO: Epoch:9/10, batch:910, train_loss:[1.09790], acc_top1:[0.68750], acc_top5:[0.93750](12.13s)
2022-10-15 21:58:00,252 - INFO: Epoch:9/10, batch:920, train_loss:[0.67622], acc_top1:[0.78125], acc_top5:[0.98438](13.06s)
2022-10-15 21:58:13,230 - INFO: Epoch:9/10, batch:930, train_loss:[0.55844], acc_top1:[0.81250], acc_top5:[0.98438](12.98s)
2022-10-15 21:58:25,351 - INFO: Epoch:9/10, batch:940, train_loss:[1.20681], acc_top1:[0.59375], acc_top5:[0.92188](12.12s)
2022-10-15 21:58:37,268 - INFO: Epoch:9/10, batch:950, train_loss:[1.01273], acc_top1:[0.62500], acc_top5:[0.90625](11.92s)
2022-10-15 21:58:50,217 - INFO: Epoch:9/10, batch:960, train_loss:[0.66012], acc_top1:[0.78125], acc_top5:[0.92188](12.95s)
2022-10-15 21:59:03,994 - INFO: Epoch:9/10, batch:970, train_loss:[0.84226], acc_top1:[0.73438], acc_top5:[0.92188](13.78s)
2022-10-15 21:59:16,460 - INFO: Epoch:9/10, batch:980, train_loss:[0.67667], acc_top1:[0.76562], acc_top5:[0.93750](12.47s)
2022-10-15 21:59:29,026 - INFO: Epoch:9/10, batch:990, train_loss:[0.54721], acc_top1:[0.85938], acc_top5:[0.95312](12.57s)
2022-10-15 21:59:42,000 - INFO: Epoch:9/10, batch:1000, train_loss:[0.48747], acc_top1:[0.82812], acc_top5:[0.98438](12.97s)
2022-10-15 22:00:01,803 - INFO: [validation] Epoch:9/10, val_loss:[0.01072], val_top1:[0.79692], val_top5:[0.96769]
2022-10-15 22:00:01,803 - INFO: 最优top1测试精度:0.80769 (epoch=6)
2022-10-15 22:00:01,804 - INFO: 训练完成,最终性能accuracy=0.80769(epoch=6), 总耗时1374.01s, 已将其保存为:Zodiac_mobilenet_v2_final
2022-10-15 22:00:04,137 - INFO: Epoch:10/10, batch:1010, train_loss:[1.07021], acc_top1:[0.70312], acc_top5:[0.90625](22.14s)
2022-10-15 22:00:15,992 - INFO: Epoch:10/10, batch:1020, train_loss:[0.95580], acc_top1:[0.68750], acc_top5:[0.85938](11.85s)
2022-10-15 22:00:28,059 - INFO: Epoch:10/10, batch:1030, train_loss:[0.73189], acc_top1:[0.78125], acc_top5:[0.96875](12.07s)
2022-10-15 22:00:40,760 - INFO: Epoch:10/10, batch:1040, train_loss:[0.85184], acc_top1:[0.73438], acc_top5:[0.89062](12.70s)
2022-10-15 22:00:52,954 - INFO: Epoch:10/10, batch:1050, train_loss:[0.71404], acc_top1:[0.81250], acc_top5:[0.98438](12.19s)
2022-10-15 22:01:06,065 - INFO: Epoch:10/10, batch:1060, train_loss:[0.90584], acc_top1:[0.76562], acc_top5:[0.93750](13.11s)
2022-10-15 22:01:18,061 - INFO: Epoch:10/10, batch:1070, train_loss:[0.68545], acc_top1:[0.78125], acc_top5:[0.96875](11.99s)
2022-10-15 22:01:30,420 - INFO: Epoch:10/10, batch:1080, train_loss:[0.81097], acc_top1:[0.78125], acc_top5:[0.92188](12.36s)
2022-10-15 22:01:43,084 - INFO: Epoch:10/10, batch:1090, train_loss:[0.73113], acc_top1:[0.75000], acc_top5:[0.96875](12.66s)
2022-10-15 22:01:56,791 - INFO: Epoch:10/10, batch:1100, train_loss:[0.73655], acc_top1:[0.73438], acc_top5:[0.95312](13.71s)
2022-10-15 22:02:10,212 - INFO: Epoch:10/10, batch:1110, train_loss:[0.86019], acc_top1:[0.65625], acc_top5:[0.92188](13.42s)
2022-10-15 22:02:22,674 - INFO: Epoch:10/10, batch:1120, train_loss:[0.77266], acc_top1:[0.73438], acc_top5:[0.95312](12.46s)
2022-10-15 22:02:32,709 - INFO: [validation] Epoch:10/10, val_loss:[0.01078], val_top1:[0.79538], val_top5:[0.97231]
2022-10-15 22:02:32,710 - INFO: 最优top1测试精度:0.80769 (epoch=6)
2022-10-15 22:02:32,710 - INFO: 训练完成,最终性能accuracy=0.80769(epoch=6), 总耗时1524.91s, 已将其保存为:Zodiac_mobilenet_v2_final
训练完毕,结果路径D:\Workspace\ExpResults\Project013TransferLearningZodiac\final_models.
2022-10-15 22:02:33,318 - INFO: Done.
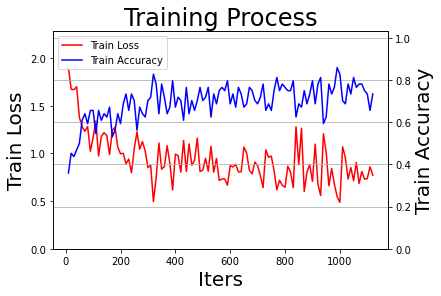
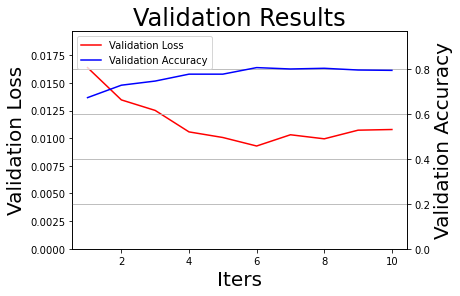
训练完成后,建议将 ExpResults 文件夹的最终文件 copy 到 ExpDeployments 用于进行部署和应用。
3.5 离线测试
Paddle 2.0+的离线测试也抛弃了fluid方法。基本流程和训练是一致。
from sympy import evaluate if __name__ == '__main__': # 设置输入样本的维度 input_spec = InputSpec(shape=[None] + args['input_size'], dtype='float32', name='image') label_spec = InputSpec(shape=[None, 1], dtype='int64', name='label') # 载入模型 network = eval("paddle.vision.models." + args['architecture'] + "(num_classes=args['class_dim'])") model = paddle.Model(network, input_spec, label_spec) # 模型实例化 model.load(args['deployments_path']['deployment_checkpoint_model']) # 载入调优模型的参数 model.prepare(loss=paddle.nn.CrossEntropyLoss(), # 设置loss metrics=paddle.metric.Accuracy(topk=(1,5))) # 设置评价指标 # 执行评估函数,并输出验证集样本的损失和精度 print('开始评估...') avg_loss, avg_acc_top1, avg_acc_top5 = evaluate(model, val_reader, verbose=1) print('\r[验证集] 损失: {:.5f}, top1精度:{:.5f}, top5精度为:{:.5f}\n'.format(avg_loss, avg_acc_top1, avg_acc_top5), end='') avg_loss, avg_acc_top1, avg_acc_top5 = evaluate(model, test_reader, verbose=1) print('\r[测试集] 损失: {:.5f}, top1精度:{:.5f}, top5精度为:{:.5f}'.format(avg_loss, avg_acc_top1, avg_acc_top5), end='')
开始评估...
[验证集] 损失: 0.00929, top1精度:0.80769, top5精度为:0.970770]
[测试集] 损失: 0.01098, top1精度:0.79848, top5精度为:0.968180]
【结果分析】
需要注意的是此处的精度与训练过程中输出的测试精度是不相同的,因为训练过程中使用的是验证集, 而这里的离线测试使用的是测试集.
【实验结果及评价】
下面我们将在 AlexNet, ResNet50, ResNet18, Mobilenetv2, VGG16五个模型对十二生肖数据集进行评估,所有模型设置batch_size=64。
数据集包含样本8500个,其中训练验证集样本7840个,训练集样本7190个, 验证集样本650个, 测试集样本660个, 共计8500个。
1. 实验结果
| 模型名称 | Baseline模型 | ImageNet预训练 | learning_rate | best_epoch | top-1 acc | top-5 acc | loss | test_top1_acc | 单batch时间/总训练时间(s) | 可训练参数/总参数 |
|---|---|---|---|---|---|---|---|---|---|---|
| Zodiac_Alexnet | Alexnet | 否 | 0.001 | 3/10 | 0.48769 | 0.87231 | 0.02458 | 0.48485 | 9.06/1177.53 | 11,172,042/11,191,242 |
| Zodiac_Resnet18 | ResNet18 | 是 | 0.01 | 7/10 | 0.83385 | 0.97538 | 0.01093 | 0.81364 | 10.20/1389.07 | 11,172,042/11,191,242 |
| Zodiac_Resnet18_withoutPretrained | ResNet18 | 否 | 0.01 | 50/50 | 0.60769 | 0.90769 | 0.02072 | 0.60909 | 12.28/7220.98 | 11,172,042/11,191,242 |
| Zodiac_Resnet50 | ResNet50 | 是 | 0.01 | 8/10 | 0.94615 | 0.99846 | 0.00343 | 0.94545 | 11.67/1455.60 | 23,479,500/23,585,740 |
| Zodiac_Resnet50_withoutPretrained | ResNet50 | 否 | 0.01 | 45/50 | 0.54154 | 0.89538 | 0.04756 | 0.55152 | 11.24/7868.96 | 23,479,500/23,585,740 |
| Zodiac_VGG16 | VGG16 | 是 | 0.001 | 8/10 | 0.89385 | 0.98615 | 0.00581 | 0.86515 | 16.69/2243.58 | 134,309,708/134,309,708 |
| Zodiac_VGG16_withoutPretrained | VGG16 | 否 | 0.001 | 45/50 | 0.55231 | 0.90000 | 0.03685 | 0.86429 | 14.75/8727.87 | 134,309,708/134,309,708 |
| Zodiac_Mobilenetv2 | Mobilenetv2 | 是 | 0.001 | 9/10 | 0.92769 | 0.99692 | 0.00425 | 0.91212 | 10.18/1294.77 | 2,205,132/2,273,356 |
| Zodiac_Mobilenetv2_withoutPretrained | Mobilenetv2 | 否 | 0.001 | 44/50 | 0.52615 | 0.87077 | 0.03536 | 0.51667 | 10.44/5838.82s | 2,205,132/2,273,356 |
2. 实验结果分析
从实验结果可以得到以下几个结论:
- 基于Imagenet预训练模型的
微调训练(finetune)比从头训练收敛更快,且更容易获得较好的性能 - VGG16因为参数较多,因此被应用到简单的
手势识别数据集时更容易发生过拟合,训练起来更困难;相似的ResNet50在该数据集上也趋向于过拟合 - VGG16和Alexnet模型因为
参数较多,且没有类似残差结构的辅助,需要更低的学习率来进行训练 参数的数量对训练时间有较大的影响- 从损失loss和精确度来看,没有使用Imagenet预训练参数的模型的ResNet18还没有完全收敛。也证明了迁移学习在计算机视觉任务中的作用明显
- 同一种模型的
参数数量是固定的,主要由其卷积层、全连接层等内部结构决定 - 由于任务并不复杂,因此四种模型的top5精度都比较高,说明CNN模型的判别能力还是很不错的
- 总体来看,ResNet50的性能是最好的,要优于ResNet18, VGG16和Mobilenet v2。一方面体现了残差网络的强大性能,另一方面也说明更深的模型对于识别精度是有积极意义的(Resnet50是50层,而Resnet18只有18层,VGG16也只有16层)。此外,Mobilenetv2也具有相当不错的性能,并且参数量只有ResNet50模型的10%,使其更适合部署在移动设备上。
值得注意的是,由于数据集比较简单,参数的初始化以及随机梯度下降算法对于训练的过程影响比较大。即每次训练的过程(甚至结果)可能会有一定的波动,但较好的超参数设置仍然有助于获得较好的性能。