【项目008】卷积神经网络的结构设计与实现(教学版) 隐藏答案 | 返回首页
作者:欧新宇(Xinyu OU)
当前版本:Release v2.0
开发平台:Paddle 2.5.2
运行环境:Intel Core i7-7700K CPU 4.2GHz, nVidia GeForce GTX 1080 Ti
本教案所涉及的数据集仅用于教学和交流使用,请勿用作商用。
最后更新:2024年5月26日
- 学生版ipynb文件下载(点击右键->将链接另存为):Project008ArchitechtureDesignStudent.ipynb
随着网络的加深,卷积神经网络的设计变得越来越复杂。但是,仔细观察可以发现有一些层的结构是规律的,例如Resnet结构,Inception结构等。下面我们将从最简单的LeNet-5和CIFAR-10开始,简要说明如何在Paddle中进行CNN网络结构的设计与实现。由于从飞桨框架2.5版本开始,paddle.fluid 库已被废弃,因此,本教案仅使用Paddle2.0+中推荐的 paddle.nn 库进行实现。若想浏览Paddle早期使用 paddle.fluid 进行库构建的方法,请访问 【项目008】的V1.0版本。
【实验目的】
- 熟悉卷积神经网络的基本结构,特别是卷积层+激活函数+池化层的叠加结构
- 学会计算卷积神经网络各层的超参数
- 学会根据网络结构图实现CNN类的定义
- 学会编写代码实现CNN类的基本测试
- 学会基于Paddle 2.0(paddle.nn)框架的设计模式
【实验要求】
- 所有作业均在AIStudio上进行提交,提交时包含源代码和运行结果
- 按照给定的MNIST和CIFAR-10网络的拓扑结构图,完成
网络参数配置表(Q1, Q4)(每个模型20分) - 根据
网络拓扑结构结构图和参数配置表,完成MNIST神经网络类Class MNIST()Q2和CIFAR神经网络类Class CIFAR10Q5的定义(每个模型20分) - 完善
网络结构测试代码和前向传输测试代码(Q3, Q6)(每个模型10分)
【知识准备】
在Paddle1.8的设计模式中,Paddle使用包括卷积层Conv2D,池化层Pool2D,全连接层Linear在内的三个类来实现不同的功能层,在这些功能层中使用act属性来定义激活函数;但是,在Paddle2.0之后的版本中,Paddle将ReLu, Sigmoid等激活函数从层的定义中移除,并定义了单独类来进行描述。此外,在Paddle 2.0之后的版本中,动态图模式被作为默认模式启用,同时取消了 paddle.fluid 类,而是改用 paddle.nn 类来实现对各个功能层的定义。与此同时,Paddle提供了一个 paddle.vision.models 类,并内置了LeNet, AlexNet, MobileNetV1, V2, ResNet, VGG, DenseNet等经典模型。如果不需要对模型进行修改,则可以使用Paddle的高阶API实现模型的快速调用。
1. Paddle 2.0 设计模式
class paddle.nn.ReLU()
class paddle.nn.Sigmoid()
class paddle.nn.Dropout(p=0.5)
class paddle.nn.Conv2D(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, padding_mode='zeros', weight_attr=None, bias_attr=None, data_format='NCHW')
class paddle.nn.MaxPool2D(kernel_size, stride=None, padding=0, ceil_mode=False, return_mask=False, data_format='NCHW', name=None)
class paddle.nn.Linear(in_features, out_features, weight_attr=None, bias_attr=None, name=None)
- paddle.nn.ReLU
- paddle.nn.Sigmoid
- paddle.nn.Dropout
- paddle.nn.MaxPool2D
- paddle.nn.Conv2D
- paddle.nn.Linear
2. Paddle高阶API
import paddle
AlexNet = paddle.vision.models.AlexNet
model = AlexNet()
paddle.summary(model, (2, 3, 227, 227))
【实验内容】
【任务一】 MNIST模型(50分)
LeNet-5模型的原始输入尺寸是32×32,但是由于MNIST数据集的样本为28×28,因此需要对LeNet-5进行一定的调整。此次我们暂定调整后的模型命名为MNIST。
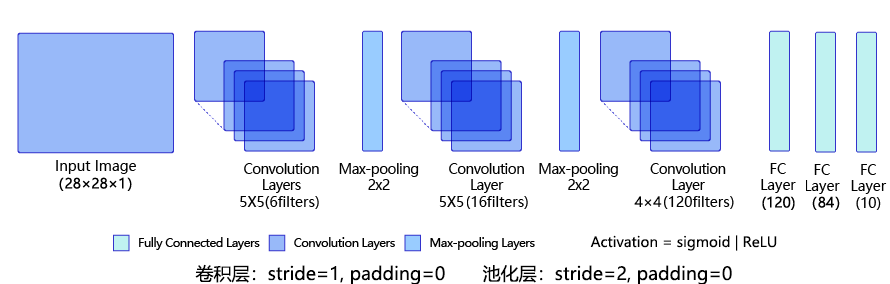
Q1: 根据LeNet-5拓扑结构图完成下列网络参数配置表(Conv1~FC2)(20分)
- 网络参数配置表
| Layer | Input | Kernels_num | Kernels_size | Stride | Padding | PoolingType | Output | Parameters |
|---|---|---|---|---|---|---|---|---|
| Input | 1×28×28 | - | - | - | - | - | 1×28×28 | - |
| Conv1 | 1×28×28 | 6 | 1×5×5 | 1 | 0 | - | 6×24×24 | (1×5×5+1)×6=156 |
| Pool1 | 6×24×24 | 6 | 6×2×2 | 2 | 0 | Max | 6×12×12 | 0 |
| Conv2 | 6×12×12 | 16 | 6×5×5 | 1 | 0 | - | 16×8×8 | (6×5×5+1)×16=2416 |
| Pool2 | 16×8×8 | 16 | 16×2×2 | 2 | 0 | Max | 16×4×4 | 0 |
| Conv3 | 16×4×4 | 120 | 16×4×4 | 1 | 0 | - | 120×1×1 | (16×4×4+1)×120=30840 |
| FC1 | (120×1×1)×1 | - | - | - | - | - | 120×1 | (120+1)×84=10164 |
| FC2 | 120×1 | - | - | - | - | - | 84×1 | (84+1)×10=850 |
| Output | 84×1 | - | - | - | - | - | 10×1 | - |
| Total = 44426 | ||||||||
Q2: 根据LeNet-5拓扑结构图和Q1中完成的网络参数配置表完成下列MNIST模型的类定义([Your codes 1], [Your codes 2])(20分)
- 定义神经网络类
# 载入基础库
import paddle
from paddle.nn import Sequential, Conv2D, MaxPool2D, Linear, ReLU
class MNIST(paddle.nn.Layer):
def __init__(self, num_classes=10):
super(MNIST, self).__init__()
# Q2-1: 根据LeNet-5拓扑结构图和Q1中完成的网络参数配置表完成下列MNIST模型的类定义
# 各层超参数定义: [Your codes 1]
self.features = Sequential(
Conv2D(in_channels=1, out_channels=6, kernel_size=5, stride=1),
ReLU(),
MaxPool2D(kernel_size=2, stride=2),
Conv2D(in_channels=6, out_channels=16, kernel_size=5, stride=1),
ReLU(),
MaxPool2D(kernel_size=2, stride=2),
Conv2D(in_channels=16, out_channels=120, kernel_size=4, stride=1),
ReLU(),
)
self.fc = Sequential(
# conv3层输出通道数为120
Linear(in_features=120, out_features=84),
ReLU(),
# 在最后一个全连接层如果不定义激活函数act='softmax',可以直接在最后的输出层定义激活函数
Linear(in_features=84, out_features=num_classes),
)
def forward(self, inputs):
# Q2-2: 根据LeNet-5拓扑结构图和Q1中完成的网络参数配置表完成下列MNIST模型的类定义
# 定义前向传输过程: [Your codes 2]
x = self.features(inputs)
x = paddle.flatten(x, 1)
x = self.fc(x)
return x
Q3: 完善下列网络结构测试代码([Your codes 3])(10分)
# Q3: 完善下列网络结构测试代码 [Your codes 3]
#### 网络测试
if __name__ == '__main__':
# 1. 输出网络结构
# Q3-1: 完善下列网络结构测试代码: [Your codes 6]
model = MNIST()
paddle.summary(model, (10, 1, 28, 28))
# 2. 测试前向传输
# Q3-2: 完善前向传输测试代码: [Your codes 7]
print('测试前向传输:')
img = paddle.rand([2, 1, 28, 28])
model = MNIST()
outs = model(img).numpy()
print(outs)
print('输出张量的形态为:{}'.format(outs.shape))
---------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===========================================================================
Conv2D-1 [[10, 1, 28, 28]] [10, 6, 24, 24] 156
ReLU-1 [[10, 6, 24, 24]] [10, 6, 24, 24] 0
MaxPool2D-1 [[10, 6, 24, 24]] [10, 6, 12, 12] 0
Conv2D-2 [[10, 6, 12, 12]] [10, 16, 8, 8] 2,416
ReLU-2 [[10, 16, 8, 8]] [10, 16, 8, 8] 0
MaxPool2D-2 [[10, 16, 8, 8]] [10, 16, 4, 4] 0
Conv2D-3 [[10, 16, 4, 4]] [10, 120, 1, 1] 30,840
ReLU-3 [[10, 120, 1, 1]] [10, 120, 1, 1] 0
Linear-1 [[10, 120]] [10, 84] 10,164
ReLU-4 [[10, 84]] [10, 84] 0
Linear-2 [[10, 84]] [10, 10] 850
===========================================================================
Total params: 44,426
Trainable params: 44,426
Non-trainable params: 0
---------------------------------------------------------------------------
Input size (MB): 0.03
Forward/backward pass size (MB): 0.80
Params size (MB): 0.17
Estimated Total Size (MB): 1.00
---------------------------------------------------------------------------
测试前向传输:
[[ 0.5856232 1.9011972 -2.5537167 0.03758901 1.2203399 0.6296974
-0.94731206 0.49605742 -0.2495057 -2.6625118 ]
[ 0.12857331 1.8385615 -2.7530465 -0.14499573 1.2690562 0.7700126
-0.9935208 -0.09221044 -0.32944232 -2.4933076 ]]
输出张量的形态为:(2, 10)
【任务二】 CIFAR10模型(Paddle 2.0)(50分)
CIFAR-10 是一个更接近普适物体的彩色图像数据集。CIFAR-10是由Hinton 的学生Alex Krizhevsky 和Ilya Sutskever 整理的一个用于识别普适物体的小型数据集,该数据集的所有样本均从 80 million tiny images 数据中获取。。一共包含10 个类别的RGB彩色图片:飞机( airplane )、汽车( automobile )、鸟类( bird )、猫( cat )、鹿( deer )、狗( dog )、蛙类( frog )、马( horse )、船( ship )和卡车( truck )。每个图片的尺寸为32 × 32 ,每个类别有6000个图像,数据集中一共有50000 张训练图片和10000 张测试图片。此外还有一个类似的CIFAR-100数据集,也由Alex和Ilya收集,该数据包含100个类,每个类100个样本,其中500个用于训练,100个用于测试。
下图是一个经典的用于CIFAR-10识别的卷积神经网络结构图。
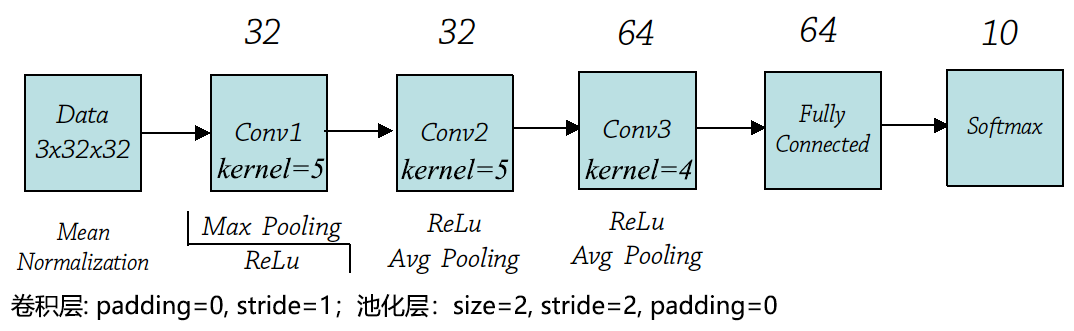
Q4: 根据CIFAR-10拓扑结构图完成下列网络参数配置表(Conv1~FC2)(20分)
- 网络参数配置表
| Layer | Input | Kernels_num | Kernels_size | Stride | Padding | PoolingType | Output | Parameters |
|---|---|---|---|---|---|---|---|---|
| Input | 3×32×32 | - | - | - | - | - | 3×32×32 | - |
| Conv1 | 3×32×32 | 32 | 3×5×5 | 1 | 0 | - | 32×28×28 | (3×5×5+1)×32=2432 |
| Pool1 | 32×28×28 | 32 | 32×2×2 | 2 | 0 | Max | 32×14×14 | 0 |
| Conv2 | 32×14×14 | 32 | 32×5×5 | 1 | 0 | - | 32×10×10 | (32×5×5+1)×32=25632 |
| Pool2 | 32×10×10 | 32 | 32×2×2 | 2 | 0 | Avg | 32×5×5 | 0 |
| Conv3 | 32×5×5 | 64 | 32×4×4 | 1 | 0 | - | 64×2×2 | (32×4×4+1)×64=32832 |
| Pool3 | 64×2×2 | 64 | 64×2×2 | 2 | 0 | Avg | 64×1×1 | 0 |
| FC1 | (64×1×1)×1 | - | - | - | - | - | 64×1 | (64+1)×64=4160 |
| FC2 | 64×1 | - | - | - | - | - | 64×10 | (64+1)×10=650 |
| Output | - | - | - | - | - | - | 10×1 | - |
| Total = 65706 | ||||||||
Q5: 根据Cifar10拓扑结构图和Q4中完成的网络参数配置表完成下列Cifar10模型的类定义([Your codes 4], [Your codes 5])(20分)
- 定义神经网络类
# 载入基础库
import paddle
from paddle.nn import Sequential, Conv2D, MaxPool2D, AvgPool2D, Linear, Dropout, ReLU
class Cifar10(paddle.nn.Layer):
def __init__(self, num_classes=10):
super(Cifar10, self).__init__()
self.num_classes = num_classes
# Q5-1: 根据Cifar10拓扑结构图和Q4中完成的网络参数配置表完成下列Cifar10模型的类定义
# 各层超参数定义: [Your codes 4]
self.features = Sequential(
Conv2D(in_channels=3, out_channels=32, kernel_size=5, stride=1),
ReLU(),
MaxPool2D(kernel_size=2, stride=2),
Conv2D(in_channels=32, out_channels=32, kernel_size=5, stride=1),
ReLU(),
AvgPool2D(kernel_size=2, stride=2),
Conv2D(in_channels=32, out_channels=64, kernel_size=4, stride=1),
ReLU(),
AvgPool2D(kernel_size=2, stride=2),
)
self.fc = Sequential(
Linear(in_features=64*1*1, out_features=64),
Linear(in_features=64, out_features=num_classes),
)
def forward(self, inputs):
# Q5-2: 根据Cifar10拓扑结构图和Q4中完成的网络参数配置表完成下列Cifar10模型的类定义
# 定义前向传输过程: [Your codes 5]
x = self.features(inputs)
x = paddle.flatten(x, 1)
x = self.fc(x)
return x
Q6: 完善下列网络结构测试代码([Your codes 8], [Your codes 9])和前向传输测试代码([Your codes 10])(10分)
#### 网络测试
if __name__ == '__main__':
# 1. 输出网络结构
# Q6-1: 完善下列网络结构测试代码: [Your codes 6]
model = Cifar10()
paddle.summary(model, (1, 3, 32, 32))
# 2. 测试前向传输
# Q6-2: 完善前向传输测试代码: [Your codes 7]
print('测试前向传输:')
img = paddle.rand([2, 3, 32, 32])
model = Cifar10()
outs = model(img).numpy()
print(outs)
print('输出张量的形态为:{}'.format(outs.shape))
---------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===========================================================================
Conv2D-4 [[1, 3, 32, 32]] [1, 32, 28, 28] 2,432
ReLU-1 [[1, 32, 28, 28]] [1, 32, 28, 28] 0
MaxPool2D-1 [[1, 32, 28, 28]] [1, 32, 14, 14] 0
Conv2D-5 [[1, 32, 14, 14]] [1, 32, 10, 10] 25,632
ReLU-2 [[1, 32, 10, 10]] [1, 32, 10, 10] 0
AvgPool2D-1 [[1, 32, 10, 10]] [1, 32, 5, 5] 0
Conv2D-6 [[1, 32, 5, 5]] [1, 64, 2, 2] 32,832
ReLU-3 [[1, 64, 2, 2]] [1, 64, 2, 2] 0
AvgPool2D-2 [[1, 64, 2, 2]] [1, 64, 1, 1] 0
Linear-3 [[1, 64]] [1, 64] 4,160
Linear-4 [[1, 64]] [1, 10] 650
===========================================================================
Total params: 65,706
Trainable params: 65,706
Non-trainable params: 0
---------------------------------------------------------------------------
Input size (MB): 0.01
Forward/backward pass size (MB): 0.49
Params size (MB): 0.25
Estimated Total Size (MB): 0.75
---------------------------------------------------------------------------
测试前向传输:
[[ 0.2849031 -0.05835417 -0.8993984 0.24468683 0.73669934 -0.23037165
1.0173364 0.14233571 0.15384644 -0.4779564 ]
[ 0.20973384 -0.06269945 -0.86370426 0.2379338 0.79307395 -0.05458799
0.9996517 0.09347898 0.11147128 -0.26353168]]
输出张量的形态为:(2, 10)
【任务三】 AlexNet模型(拓展练习)
(以下部分请读者自行完成。)
AlexNet模型[1],由多伦多大学的Geffery Hinton教授的学生Krizhevsky Alex提出,下面使用Paddle2.0的Paddle.nn库进行网络拓扑结构的设计。
[1] Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton. ImageNet classification with deep convolutional neural networks. International Conference on Neural Information Processing Systems. Curran Associates Inc. 2012:1097-1105.
3.1 网络拓扑结构图
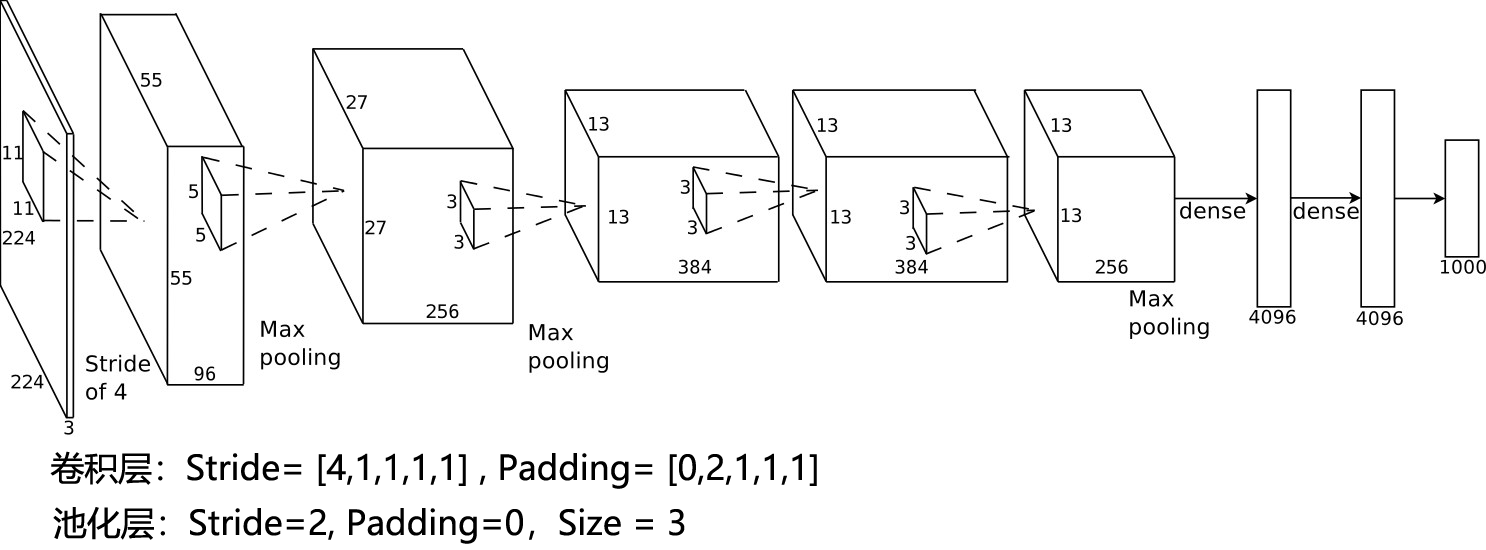
需要注意的是,在大多数深度学习工具包中,Alexnet的输入尺度会被Crop为 [3×227×227]。如果按照原始论文中 [3×224×224] 的尺度进行输入,需要适当调节网络的参数
Conv: Output_size = (Input_size - Kernel_size + 2*Padding)/Stride + 1
Pool: Output_size = Input_size/Stride.
3.2 网络参数配置表
| Layer | Input | Kernel_num | Kernel_size | Stride | Padding | PoolingType | Output | Parameters |
|---|---|---|---|---|---|---|---|---|
| Input | 3×227×227 | - | - | - | - | - | - | - |
| Conv1 | 3×227×227 | 96 | 3×11×11 | 4 | 0 | - | 96×55×55 | (3×11×11+1)×96=34944 |
| Pool1 | 96×55×55 | 96 | 96×3×3 | 2 | 0 | max | 96×27×27 | 0 |
| Conv2 | 96×27×27 | 256 | 96×5×5 | 1 | 2 | - | 256×27×27 | (96×5×5+1)×256=614656 |
| Pool2 | 256×27×27 | 256 | 256×3×3 | 2 | 0 | max | 256×13×13 | 0 |
| Conv3 | 256×13×13 | 384 | 256×3×3 | 1 | 1 | - | 384×13×13 | (256×3×3+1)×384=885120 |
| Conv4 | 384×13×13 | 384 | 384×3×3 | 1 | 1 | - | 384×13×13 | (384×3×3+1)×384=1327488 |
| Conv5 | 384×13×13 | 256 | 384×3×3 | 1 | 1 | - | 256×13×13 | (384×3×3+1)×256=884992 |
| Pool5 | 256×13×13 | 256 | 256×3×3 | 2 | 0 | max | 256×6×6 | 0 |
| FC6 | (256×6×6)×1 | - | - | - | - | - | 4096×1 | (9216+1)×4096=37752832 |
| FC7 | 4096×1 | - | - | - | - | - | 4096×1 | (4096+1)×4096=16781312 |
| FC8 | 4096×1 | - | - | - | - | - | 1000×1 | (4096+1)×1000=4097000 |
| Output | - | - | - | - | - | - | 1000×1 | - |
| Total = 62378344 | ||||||||
其中, 卷积层参数:3747200,占总参数的6%; 全连接层参数:58631144, 占总参数94%。
3.3 定义神经网络类
3.3.1 逐层定义
import paddle
from paddle.nn import Conv2D, MaxPool2D, Linear, Dropout
import paddle.nn.functional as F
# 定义 AlexNet 网络结构
class AlexNet1(paddle.nn.Layer):
def __init__(self, num_classes=1000):
super(AlexNet1, self).__init__()
# AlexNet与LeNet一样也会同时使用卷积和池化层提取图像特征
# 与LeNet不同的是激活函数换成了‘relu’
self.conv1 = Conv2D(in_channels=3, out_channels=96, kernel_size=11, stride=4, padding=5)
self.max_pool1 = MaxPool2D(kernel_size=2, stride=2)
self.conv2 = Conv2D(in_channels=96, out_channels=256, kernel_size=5, stride=1, padding=2)
self.max_pool2 = MaxPool2D(kernel_size=2, stride=2)
self.conv3 = Conv2D(in_channels=256, out_channels=384, kernel_size=3, stride=1, padding=1)
self.conv4 = Conv2D(in_channels=384, out_channels=384, kernel_size=3, stride=1, padding=1)
self.conv5 = Conv2D(in_channels=384, out_channels=256, kernel_size=3, stride=1, padding=1)
self.max_pool5 = MaxPool2D(kernel_size=3, stride=2)
self.fc1 = Linear(in_features=256*6*6, out_features=4096)
self.drop1 = Dropout()
self.fc2 = Linear(in_features=4096, out_features=4096)
self.drop2 = Dropout()
self.fc3 = Linear(in_features=4096, out_features=num_classes)
def forward(self, inputs):
x = self.conv1(inputs)
x = F.relu(x)
x = self.max_pool1(x)
x = self.conv2(x)
x = F.relu(x)
x = self.max_pool2(x)
x = self.conv3(x)
x = F.relu(x)
x = self.conv4(x)
x = F.relu(x)
x = self.conv5(x)
x = F.relu(x)
x = self.max_pool5(x)
x = paddle.reshape(x, [x.shape[0], -1])
x = self.fc1(x)
x = F.relu(x)
x = self.drop1(x) # 在全连接之后使用dropout抑制过拟合
x = self.fc2(x)
x = F.relu(x)
x = self.drop2(x) # 在全连接之后使用dropout抑制过拟合
x = self.fc3(x)
return x
3.3.2 模块化设计
从Alexnet开始,包括VGG,GoogLeNet,Resnet等模型都是层次较深的模型,如果按照逐层的方式进行设计,代码会变得非常繁琐。因此,我们可以考虑使用 Sequential 将相同结构的模型进行汇总和合成,例如Alexnet中,卷积层+激活+池化层就是一个完整的结构体。
import paddle
from paddle.nn import Sequential, Conv2D, MaxPool2D, Linear, Dropout, ReLU
class AlexNet2(paddle.nn.Layer):
def __init__(self, num_classes=1000):
super(AlexNet2, self).__init__()
self.num_classes = num_classes
self.features = Sequential(
Conv2D(in_channels=3, out_channels=96, kernel_size=11, stride=4, padding=0),
ReLU(),
MaxPool2D(kernel_size=3, stride=2),
Conv2D(in_channels=96, out_channels=256, kernel_size=5, stride=1, padding=2),
ReLU(),
MaxPool2D(kernel_size=3, stride=2),
Conv2D(in_channels=256, out_channels=384, kernel_size=3, stride=1, padding=1),
ReLU(),
Conv2D(in_channels=384, out_channels=384, kernel_size=3, stride=1, padding=1),
ReLU(),
Conv2D(in_channels=384, out_channels=256, kernel_size=3, stride=1, padding=1),
ReLU(),
MaxPool2D(kernel_size=3, stride=2),
)
self.fc = Sequential(
Linear(in_features=256*6*6, out_features=4096),
ReLU(),
Dropout(),
Linear(in_features=4096, out_features=4096),
ReLU(),
Dropout(),
Linear(in_features=4096, out_features=num_classes),
)
def forward(self, inputs):
x = self.features(inputs)
x = paddle.flatten(x, 1)
x = self.fc(x)
return x
3.3.3 调用Paddle API高阶端口
import paddle
AlexNet3 = paddle.vision.models.AlexNet
3.4 网络测试
3.4.1 网络结构测试
使用 Paddle.summary() 方法对模型进行结构信息输出。值得注意的是Paddle.vision.models.AlexNet所定义的AlexNet模型与论文中原始的模型有细微差异,有兴趣的同学可以使用 print(model) 方法将模型配置进行输出对比。
model = AlexNet1() # 逐层定义:AlexNet1 | 模块化设计:AlexNet2 | 高阶API接口: AlexNet3
paddle.summary(model, (2, 3, 227, 227))
---------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===========================================================================
Conv2D-13 [[2, 3, 227, 227]] [2, 96, 57, 57] 34,944
MaxPool2D-7 [[2, 96, 57, 57]] [2, 96, 28, 28] 0
Conv2D-14 [[2, 96, 28, 28]] [2, 256, 28, 28] 614,656
MaxPool2D-8 [[2, 256, 28, 28]] [2, 256, 14, 14] 0
Conv2D-15 [[2, 256, 14, 14]] [2, 384, 14, 14] 885,120
Conv2D-16 [[2, 384, 14, 14]] [2, 384, 14, 14] 1,327,488
Conv2D-17 [[2, 384, 14, 14]] [2, 256, 14, 14] 884,992
MaxPool2D-9 [[2, 256, 14, 14]] [2, 256, 6, 6] 0
Linear-9 [[2, 9216]] [2, 4096] 37,752,832
Dropout-1 [[2, 4096]] [2, 4096] 0
Linear-10 [[2, 4096]] [2, 4096] 16,781,312
Dropout-2 [[2, 4096]] [2, 4096] 0
Linear-11 [[2, 4096]] [2, 1000] 4,097,000
===========================================================================
Total params: 62,378,344
Trainable params: 62,378,344
Non-trainable params: 0
---------------------------------------------------------------------------
Input size (MB): 1.18
Forward/backward pass size (MB): 13.20
Params size (MB): 237.95
Estimated Total Size (MB): 252.34
---------------------------------------------------------------------------
{'total_params': 62378344, 'trainable_params': 62378344}
3.4.2 前向传输测试
print('测试前向传输:')
if __name__ == '__main__':
print('测试前向传输:')
img = paddle.rand([2, 3, 227, 227])
model = AlexNet3()
outs = model(img).numpy()
print(outs)
print('输出张量的形态为:{}'.format(outs.shape))
测试前向传输:
测试前向传输:
[[-0.01074712 0.00975456 0.00015983 ... -0.00677018 -0.00430757
0.01052165]
[-0.01127513 0.00967784 -0.00012327 ... -0.00679108 -0.00341656
0.01055686]]
输出张量的形态为:(2, 1000)