【项目001】初识AI:通信大数据行程卡信息识别(教学版) 隐藏答案 | 返回首页
作者:欧新宇(Xinyu OU)
当前版本:Release v2.0
开发平台:Paddle 2.5.2, PaddleOCR
运行环境:Intel Core i7-7700K CPU 4.2GHz, nVidia GeForce GTX 1080 Ti
本教案所涉及的数据集仅用于教学和交流使用,请勿用作商用。
最后更新:2024年5月23日
- 学生版ipynb文件下载(点击右键->将链接另存为):Project001TravelCodeStudent.ipynb
通信大数据行程卡,俗称“行程码”,是在2020年3月6日由中国信息通信研究院联合中国电信、中国移动、中国联通三家基础电信企业推出的服务。这一服务基于手机“信令数据”,通过用户手机所处的基站位置获取,为全国超过16亿手机用户免费提供查询服务。在疫情防控期间,该服务在锁定感染源、密切接触人群以及防控疫情传播方面发挥了重要作用。使用AI对通信大数据卡进行识别是一种简单的应用,相比传统的人工处理,大大提高了数据的处理效率,并且该方法具有广泛的应用场景,可以推广到各种基于图像的文本识别和统计应用中。
【实验目的】
- 回顾计算机视觉的基本知识,包括数字图像处理、数据分析与可视化及Python语言基础;
- 初步感受如何基于AI技术来解决实际应用问题;
- 初步感受Paddle工具包(PaddleORC)的快速开发;
- 能够学会如何使用计算机视觉技术实现批量图像样本的数据采集。
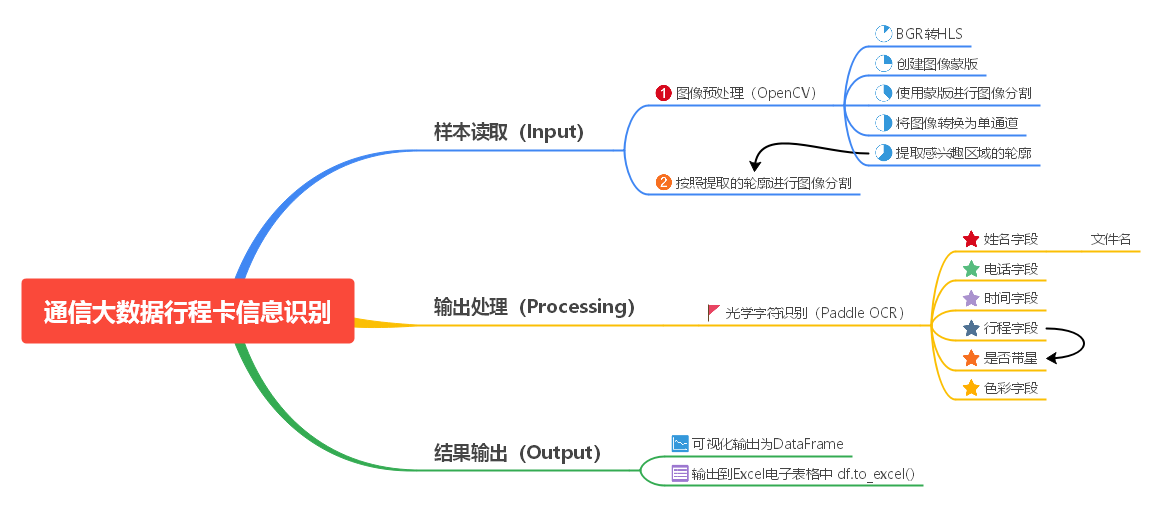
【思维导图】
【目录结构】
- 本项目目录结构说明(可根据实际情况进行修改)
- 根目录:D:\Workspace\DeepLearning\WebsiteV2
- 项目默认目录:D:\Workspace\DeepLearning\WebsiteV2\Data\Projects\Project001TravelCard
- 图像资源目录:D:\Workspace\DeepLearning\WebsiteV2\Data\Projects\Project001TravelCard\Images
- 结果保存目录:D:\Workspace\DeepLearning\WebsiteV2\Data\Projects\Project001TravelCard
- 输出结果名称:output.xlsx
【实验数据】
- 数据集名称:Project001TravelCard
- 数据集大小:2.17M
- 数据集格式:.png, .jpg, .jpeg
- 数据集简介:本数据集包含12张通信大数据行程卡样本,样本中包含有行程卡的图像,图像中包含
手机号码、更新时间、途径、星号状态、是否为绿码等信息,样本以姓名命名。 - 下载地址:Project001TravelCard.rar
【实验1】 实验环境准备
实验难度:简单
实验摘要:根据任务需求安装和配置实验环境,本项目涉及Python基本编程环境、Paddle深度学习基础环境、PaddleOCR光学字符识别和OpenCV图像处理技术和Pandas数据结构的使用。
实验目标:
- 回顾Python文件处理、OpenCV图像处理和Pandas数据结构的几个基本要点和方法
- 能够根据任务要求和实验目的设计代码结构和流程
- 能够完成基于计算机视觉技术的通信大数据行程卡信息识别
实验建议:
-
本项目需要使用JupterLab开发环境,要求安装Anaconda(包含matplotlib, pandas, numpy, PIL库), OpenCV-Python,安装方法请参考【项目001】Python机器学习环境的安装和配置。若在AIStudio中运行该项目,则可跳过这一步,系统已内置相关库。
-
为了快速实现图像数据的处理和分析,本项目调用PaddleOCR库进行文字识别,安装方法如下(根据网络和设备情况不同可能需要2-10分钟):
- Windows 系统
1). 打开Anaconda Prompt命令提示行
2). 运行如下命令进行安装
pip install paddleocr -i https://pypi.tuna.tsinghua.edu.cn/simple
- 百度 AIStudio平台
1). 点击左侧“套件”选项卡,并点击下载PaddleOCR 2.6.0
2). 回到“目录”选项卡,发现Paddle已下载到根目录,并解压至PaddleOCR-2.6.0文件夹
3). 在AIStudio中,新建一个“终端”,然后在命令行中依次执行如下代码进行安装
cd PaddleOCR-2.6.0
pip install -r requirements.txt4). 此外,在AIStudio中,也可以直接在Notebook中执行如下命令
- Windows 系统
!cd ~/PaddleOCR-2.6.0/
!pip install -r requirements.txt
【实验2】 基本库载入及工作环境准备
实验难度:一般
实验摘要:根据任务和代码需要载入相关的库文件
实验目标:
- 学会载入PaddleOCR模块并进行模型初始化;
- 学会定义工作路径空间;
- 掌握从指定文件夹获取所有所有文件的方法;
- 学会对DataFrame控件进行初始化。
实验建议:
- PaddleOCR模块是Paddle生态产品中专门针对光学字符识别的一个工具包,方便实用。该工具包在进行第一次运行的时候,需要去官网的model zoo中下载预训练模型,用于后续的预测实用。在进行使用的时候,该模块只需要运行一次,将模块载入内存即可,不需要每次识别(同一个任务中)均进行一次初始化。超参数
lang=ch|en可以实现中英文识别的切换,超参数show_log=True|False可以配置是否打印初识化过程中的日志信息。 - 定义工作空间是项目化任务非常重要的步骤。主要原因是对于不同IDE编程环境,不同的操作系统,代码对当前目录的认识可能是不同的(例如Jupyter和VSCode就不同),因此可以考虑配置一个工作空间
root_path或者根目录root_path来进行绝对路径的定位(路径变量名可根据习惯自行定义),以防止引用错误。在后续的输入输出时,均使用os.path.join()函数将工作路径匹配到操作路径。 - DataFrame是一种比较方便的数据表/库处理格式,相比字典而已,更加灵活也更适合大数据的处理和可视化。
import os
import cv2
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
import pandas as pd
from paddleocr import PaddleOCR,draw_ocr
# 1. 初始化PaddleOCR
# 通过配置参数'lang'可以实现,英文'en'和中文'ch'字符识别的切换。
ocr = PaddleOCR(use_angle_cls=True, lang='ch', show_log=True) # (只需要运行一次)下载预训练模型,并将模型载入系统内存, 'show_log:True|False':显示运行日志
# 2. 这设置工作路径,'root_path' 指向本项目根路径,可根据实际情况进行修改
# 2.1 Windows
root_path = 'D:\Workspace\DeepLearning\WebsiteV2'
project_path = os.path.join(root_path, 'Data', 'Projects', 'Project001TravelCard')
# 2.2 Linux/Baidu AIStudio
# root_path = '/home/aistudio'
# project_path = os.path.join(root_path, 'work')
# 3. 配置图像获取路径,并获取 'Images' 路径下所有的图像样本。注意,为简化代码,该目录下只能保存待处理样本。
img_path = os.path.join(project_path, 'Images') # 配置图像路径
files = os.listdir(img_path) # 读取图像路径下的所有样本
n = len(files) # 获取样本数量
# 4. 设置需要从图像样本中获取的文本信息,并保存在DataFrame数据结构中
df = pd.DataFrame(columns = [['姓名', '电话号码', '更新时间','途经','是否带星','色彩']])
# 99. 测试并显示部分变量
print('样本总数:{}. \n 分别是:{}。'.format(n, files)) # 显示样本总数和图片列表
display(df)
[2024/05/24 20:59:04] ppocr DEBUG: Namespace(help='==SUPPRESS==', use_gpu=True, use_xpu=False, use_npu=False, ...
样本总数:12.
分别是:['刘备.jpeg', '刘达明.png', '张良武.jpeg', '拉丰.jpeg', '步惊风.jpg', '秦始皇.jpeg', '红卡弟.png', '肇八七.jpg', '苏灿.jpeg', '邓阿飞.png', '郭啸天.png', '黄卡哥.png']。
| 姓名 | 电话号码 | 更新时间 | 途经 | 是否带星 | 色彩 |
|---|
【实验3】 样本载入、预览及基本分析
实验难度:简单
实验摘要:使用Python的相关图像处理库及命令实现图像的载入和基本预处理
实验目标:
- 学会使用PIL库实现彩色图像的载入;
- 学会按照指定要求对图像进行缩放;
- 学会在JupyterLab中显示图像,并指定显示分辨率。
实验建议:
- 在实际应用中,
通信大数据行程卡的采集通常使用中文名进行命名。常见的图像处理库包括OpenCV和PIL,但OpenCV对于中文字符支持不是特别友好,因此建议使用PIL进行图像读取; - 对于部分图像格式,例如PNG,可能会以4个色彩通道形式的RGB-D(多了一个深度Depth维度)存在。但四通道的RGB-D在后续处理中将不被兼容,因此需要事先转换成RGB三通道形式;
- 对于读入的图像,建议事先进行尺度规约以便于后续的特定区域选择;
- 为便于可视化分析,建议使用plt库进行图片显示,cv2的显示将会弹出新窗口,友好性不足;
- 为便于调试代码,暂且使用单个样本进行图像获取。待编写完整图像时再改用循环语句进行批量处理。
i = 5 # 读取第6个样本进行处理
# 1. 读取图像,并转换为numpy数组
img = Image.open(os.path.join(img_path, files[i])).convert('RGB') # 使用PIL库读取图像,并转换为RGB文件格式
img = np.array(img) # 将图像转换为numpy数组,便于后续的计算和处理
# 2. 对图像进行尺度规约
img = cv2.resize(img, dsize = (600,int(600*img.shape[0]/img.shape[1]))) # 将图片压缩至宽600像素,高随宽度进行自动缩放(此处宽度可根据情况进行修改定义)
# 99. 测试并显示部分变量
plt.figure(figsize=(8,8)) # 设置打印图的分辨率
plt.imshow(img) # 显示图像
<matplotlib.image.AxesImage at 0x260d8227f40>

【实验4】 图像预处理
实验难度:中等
实验摘要:使用多种图像处理方法实现图像的预处理,并按照需要将感兴趣区域切割出来
实验目标:使用OpenCV工具包,借助于色彩蒙版技术,将行程卡白色框内的有效信息部分分割出来
实验建议:
- 获取指定颜色区域时,对于彩色区域一般使用HSV色彩通道,但对于白色使用HLS色彩通道。
- 基于色彩蒙版的蒙版技术一般步骤为:切换图像的色彩通道为:1).
HSV|HLS,2).定义感兴趣的色彩色阶范围, 3).创建色彩蒙版,4).生成蒙版图像,5).转换图像为单通道模式。 cv2.findcontours()函数通常会生成所有具有封闭性的区域作为轮廓。因此,需要根据特定任务对轮廓进行一定程度的过滤和筛选,尽量获取有效轮廓。最常见的筛选方法包括定义轮廓的长宽比例及定义轮廓的面积。本项目中对原始输入图像进行尺度规约就是为了方便统一输入图像的尺度从而使得感兴趣区域的面积具有比较明显的尺度。注意对于不同的任务可能会采用不同的过滤方法,并没有严格的通用规范。- 在原图上绘制轮廓及轮廓外接矩形,仅作为可视化分析使用,并非轮廓切割的必要步骤。
- 为便于后续的OCR处理,特别是需要对特定区域进行框选后再进行OCR以提高识别精度时,建议再次进行尺度规约。尺度规约的尺寸超参数,应根据所获取的大部分样本进行权衡。
# 1. 对读入的图像进行预处理,仅保留白色行程卡部分,并将这部分数据提取出来。目的是减少轮廓生成的数量,排除无用的信息
img_hls = cv2.cvtColor(img, cv2.COLOR_BGR2HLS) # 将OpenCV默认颜色空间BGR转换为HLS
white_low = np.array([0,250,0]) # 定义白色色阶下限(需要查寻相关色谱表)
white_high = np.array([255,255,255]) # 定义白色色阶上限(需要查寻相关色谱表)
mask = cv2.inRange(img_hls, white_low, white_high) # 根据色阶范围创建图像蒙版
img_mask = cv2.bitwise_and(img, img, mask=mask) # 利用图像蒙版分割原始图像的白色区域,去除蒙版以外的部分
img_bin = cv2.cvtColor(img_mask, cv2.COLOR_RGB2GRAY) # 将匹配获得的区域转换为灰度图用于后续生成轮廓,即8bit三通道整型数据CV_8UC3转换为8bit单通道整型数据CV_8UC1
# 2. 根据提取出来的白色行程卡区域图提取轮廓
contours, hierarchy = cv2.findContours(img_bin, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) # 生成轮廓
# 3. 排除预处理后的区域中依然属于噪声的轮廓,并将符合条件的轮廓的外接矩形保存到感兴趣区域列表`rois`中。一般会排除面积较小,或长宽比不符合规定的。此处仅排除面积过小区域。注意,排除指定面积区域需要在前面进行尺度归一化的基础上进行处理。
rois = [] # 定义并初始化感兴趣区域列表,对符条件的轮廓区域保存其外接矩形信息
for c in range(len(contours)): # 遍历所有轮廓
x, y, w, h = cv2.boundingRect(contours[c]) # 输出轮廓的外接矩形的起点坐标、高度和宽度
area = cv2.contourArea(contours[c]) # 获取轮廓的面积
if area < 200000: # 测试轮廓的面积,小于指定面积的轮廓将被排除
continue
x_t, y_t, w_t, h_t = x, y, w, h
rois.append([x_t, y_t, w_t, h_t]) # 将符合条件的轮廓添加到rois列表中
# 3. 绘制轮廓框(只运行一次)
img = cv2.rectangle(img, (x, y), (x + w, y + h), (0, 0, 255), 10, 80, 0) # 绘制轮廓的外接矩形
img_ret = cv2.drawContours(img, contours, c, (0, 255, 0), 10, 8) # 绘制轮廓
print('第{}副图片:{},轮廓数:{}。'.format(i, files[i],len(rois))) # 输出指定样本符合条件的轮廓数量(一般只应存在一个符合条件的轮廓)
roi = img[y_t:y_t+h_t, x_t:x_t+w_t, :] # 按照轮廓的外接矩形框将感兴趣区域切割出来用于后续的OCR
roi = cv2.resize(roi, dsize=(500, int(500*roi.shape[0]/roi.shape[1]))) # 将图像进行尺度归一化,宽度为500像素,高度按比例跟随变动
# 99. 可视化部分关键步骤
# 99.1 初始化图像显示框参数,配置分辨率参数
plt.figure(figsize=(6,6))
# 99.2 可视化图像处理后的各种图像
# plt.imshow(img_hls) # 可视化转换为hls色彩通道的原始图像
# plt.imshow(mask, cmap='gray') # 可视化蒙版图像
# plt.imshow(img_mask) # 可视化蒙版处理后的图像,此时为三通道图像
# plt.imshow(img_bin, cmap='gray') # 可视化二值化后的图像,此时为单通道图像(视觉上和三通道图像可能比较像)
# 99.3 可视化
# plt.imshow(img) # 显示绘制轮廓框后的原始图例(需要执行 3.绘制轮廓框/轮廓框外接矩形,此命令才有意义,否则将显示未处理前的图像)
plt.imshow(roi) # 显示轮廓切割后的感兴趣区域roi
# x = roi[150:450,100:400]
# plt.imshow(x) # 获取并显示带颜色的行程码图例包括绿色箭头, 黄色盾牌/黄色飞机和红色红心
第5副图片:秦始皇.jpeg,轮廓数:1。
<matplotlib.image.AxesImage at 0x260f8fd9640>

【实验5】 文字识别及识别结果分析和后处理
实验难度:困难
实验摘要:按照任务要求从图像中提取相关信息,包括姓名, 电话号码, 更新时间,途经,是否带星,色彩,并进行适当的处理提高适应性及抗样本错误能力。
实验目标:
- 能够使用PaddleOCR实现光学字符的识别与提取;
- 能够将PaddleOCR提取的字符按输出要求进行匹配;
- 学会根据不同输出字段的特性进行数据分析和处理,获得更完整和准确的数据;
- 能够将接PaddleOCR解析及后处理后的数据存入DataFrame数据表中。
实验建议:
- 由于
通信大数据行程卡中没有姓名信息,因此需要要求提交数据时以姓名对文件进行命名。若文件命名有其他格式,则此处需要做相应的处理。本项目以姓名命名为例。 - 对于每幅图像,PaddleOCR识别的字符数量通常是不相同的,所以很难按照固定的索引来和输出字段进行匹配。建议可以考虑遍历所有识别出来的文字字段,并分别与输出字段进行匹配,若符合某条件则进行输出;否则跳过或丢弃。
- PaddleOCR识别出来的字符可能存在一些错误,也可能存在不统一的情况,需要手动打印有一些有代表性的数据,并进行认真比对后给出解决办法。例如
全角字符“:”和半角字符“:”之间的差异,需要进行统一,本项目统一为半角字符":"。 - 时间字段需要去掉
“更新于:”字段,并分别将日期和时间提取出来后,再进行组合成[yyyy-mm-dd hh:mm:ss]格式。 到达或途经字段,如果只输出地址信息,则需要排除前面的提示语和后面的备注(在存在星号时,后面有备注信息),我们可以通过查找前面的途经:和后面的(注来定位这些切割点,并利用字符串的索引方法将前后的无用信息去除。值得注意的是,在本例中,由于图像源清晰度不同,OCR识别可能出现问题。对于起点位置,可能会存在途经:,途径:和途经等识别差异,因此需要进行一定的采样以获得可能出现的情况,并进行手动处理。对于终点位置,若为带星号,则会跟随备注信息,并以(注开头;若无星号,则信息结束,可直接进行输出。对于行程字段,由于还可能同时存在多个地点,此时行程字段会被分成多行进行显示。因此,此时需要将多个字段的行程信息进行组合汇总,才能进行后续的处理。此外,由于我们已经使用颜色蒙版对信息框进行了事先分割处理,因此行程字段应该是处于切割出来的roi区域的最底部,换句话说OCR识别出来的列表的最后的几个元素都是行程信息。所以我们只要找到第一个条途经信息,就可以顺序将列表后续的元素进行拼接获得完整的行程信息。- 判断行程是否带星号,可以从行程信息中进行
*匹配来说实现,若匹配成功则说明带星号,匹配失败则说明不带星号。 - 行程卡色彩识别,本例暂未提供,有兴趣的同学可以尝试完成。例如使用色彩模板进行匹配,看是否能找到对应的色彩。
# 本段代码用于从图像中获取姓名, 电话号码, 更新时间,途经,是否带星,色彩等信息。
# 1. 使用PaddleOCR库对roi区域进行文本识别
# !!!由于不同版本的PaddleOCR库对矩阵的实现有所区别,部分版本需要将最后的[0]去掉,即ocr_result=ocr.ocr(roi, cls=True)
ocr_result = ocr.ocr(roi, cls=True)[0] # 从OCR对象中获取识别结果
# 2. 根据输出要求处理相关字段
out_name = os.path.splitext(files[i])[0] # 姓名字段,从图片的文件名中直接获取
for j in range(len(ocr_result)):
matching = ocr_result[j][1][0]
if '动态行程卡' in matching: # 电话字段,半隐藏字段,且有后缀文字,需要将后缀文字去除
out_tel = matching[0:11]
elif '更新于' in matching: # 时间字段,包含提示信息(“更新于”)及日期和时间,需要分别提取并组合成 [yyyy-mm-dd hh:mm:ss] 格式
out_date = matching.replace(':',':')
out_date = out_date[4:14] + ' ' + out_date[14:]
elif '到达' in matching: # 行程字段,匹配OCR识别出来的第一条行程信息
out_journey = ''
start = j
for k in range(start, len(ocr_result)): # 将OCR识别出来的第一条行程信息与后续的列表字段进行拼接,获得完整的行程信息
out_journey = out_journey + ocr_result[k][1][0]
out_journey = out_journey.replace(':',':') # 替换行程信息中的全角引号为半角引号,解决识别中出现的错误
if out_journey.find('途经:') != -1: # 查找行程信息中地址信息的起点索引。
startid = out_journey.find('途经:') + 3
elif out_journey.find('途径:') != -1:
startid = out_journey.find('途径:') + 3
elif out_journey.find('途经') != -1:
startid = out_journey.find('途经') + 2
else:
startid = 0
endid = out_journey.find('(注') # 查找行程信息中地址信息的终点索引。
if endid != -1:
out_journey = out_journey[startid:endid]
else:
out_journey = out_journey[startid::]
out_isStar = '是' if '*' in out_journey else '否' # 根据行程信息中是否存在星号进行判断
# roi_sign = roi[150:430,100:400]
out_color = '未识别' # 颜色字段,本例未给出,有兴趣的同学可以在此次添加判断代码
# 3. 将输出处理好的识别结果写入DataFrame列表中
df.loc[i] = np.array([out_name, out_tel, out_date, out_journey, out_isStar, out_color])
# 99. 数据表可视化
display(df)
| 姓名 | 电话号码 | 更新时间 | 途经 | 是否带星 | 色彩 | |
|---|---|---|---|---|---|---|
| 5 | 秦始皇 | 138****5210 | 2021.09.28 16:24:03 | 辽宁省阜新市,天津市,吉林省长春市吉林省四平市,辽宁省锦州市,浙江省杭州市 | 否 | 未识别 |
【实验6】 结果输出
实验难度:简单
实验摘要:将保存到DataFrame数据结构的信息输出到Excel电子表格
实验目标:学会将DataFrame的数据输处到Excel电子表格
实验建议:无
df.to_excel(os.path.join(projcet_path, 'output.xlsx'))
print('结果保存至{},完毕。'.format(projcet_path))
结果保存至D://Workspace//DeepLearning//Websitev2\Data\Projects\Project001TravelCard,完毕。
【实验7】 批量处理并输出
实验难度:简单
实验摘要:将指定文件夹中所有待处理的样本图片,经过处理后输出到Excel电子表格
实验目标:学会批量处理数据文件
实验建议:一般来说,批量处理数据只需要进行循环操作即可,在本例中我们可以完成基本环境的设置,包括OCR模型准备、路径定义等,然后使用for循环去遍历整个样本文件夹,并依次进行处理,处理后的文本数据先保存到DataFrame列表中,最后将DataFrame列表中的数据输出到Excel电子表格中。
import os
import cv2
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
import pandas as pd
from paddleocr import PaddleOCR,draw_ocr
# 1. 初始化PaddleOCR
# 通过配置参数'lang'可以实现,英文'en'和中文'ch'字符识别的切换。
# ocr = PaddleOCR(use_angle_cls=True, lang='ch', show_log=False) # 模型下载,只需要执行一次
# 2. 这设置工作路径,'root_path' 指向本项目根路径,可根据实际情况进行修改
# 2.1 Windows
root_path = 'D:\Workspace\DeepLearning\WebsiteV2'
project_path = os.path.join(root_path, 'Data', 'Projects', 'Project001TravelCard')
# 2.2 Linux/Baidu AIStudio
# root_path = '/home/aistudio'
# project_path = os.path.join(root_path, 'work')
img_path = os.path.join(project_path, 'Images')
files = os.listdir(img_path)
n = len(files)
# 3. 设置需要从图像样本中获取的文本信息,并保存在DataFrame数据结构中
df = pd.DataFrame(columns = [['姓名', '电话号码', '更新时间','途经','是否带星','色彩']])
print('开始打印文本提取结果...')
# 4. 图像预处理
for i in range(n):
# plt.figure(figsize=(10,10))
img = Image.open(os.path.join(img_path, files[i])).convert('RGB')
img = np.array(img)
img = cv2.resize(img, dsize = [600,int(600*img.shape[0]/img.shape[1])])
img_hls = cv2.cvtColor(img, cv2.COLOR_BGR2HLS) # 将OpenCV默认颜色空间BGR转换为HLS
white_low = np.array([0,250,0]) # 定义白色色阶下限(需要查寻相关色谱表)
white_high = np.array([255,255,255]) # 定义白色色阶上限(需要查寻相关色谱表)
mask = cv2.inRange(img_hls, white_low, white_high) # 根据色阶范围创建图像蒙版
img_mask = cv2.bitwise_and(img, img, mask=mask) # 利用图像蒙版分割原始图像的白色区域,去除蒙版以外的部分
img_bin = cv2.cvtColor(img_mask, cv2.COLOR_RGB2GRAY) # 将匹配获得的区域转换为灰度图用于后续生成轮廓,即8bit三通道整型数据CV_8UC3转换为8bit单通道整型数据CV_8UC1
contours, hierarchy = cv2.findContours(img_bin, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) # 生成轮廓
# 排除预处理后的区域中依然属于噪声的轮廓,并将符合条件的轮廓的外接矩形保存到感兴趣区域列表`rois`中。一般会排除面积较小,或长宽比不符合规定的。此处仅排除面积过小区域。注意,排除指定面积区域需要在前面进行尺度归一化的基础上进行处理。
rois = [] # 定义并初始化感兴趣区域列表,对符条件的轮廓区域保存其外接矩形信息
for c in range(len(contours)): # 遍历所有轮廓
x, y, w, h = cv2.boundingRect(contours[c]) # 输出轮廓的外接矩形的起点坐标、高度和宽度
area = cv2.contourArea(contours[c]) # 获取轮廓的面积
if area < 200000: # 测试轮廓的面积,小于指定面积的轮廓将被排除
continue
x_t, y_t, w_t, h_t = x, y, w, h
rois.append([x_t, y_t, w_t, h_t]) # 将符合条件的轮廓添加到rois列表中
# 3. 绘制轮廓框(只运行一次)
img = cv2.rectangle(img, (x, y), (x + w, y + h), (0, 0, 255), 10, 80, 0) # 绘制轮廓的外接矩形
img_ret = cv2.drawContours(img, contours, c, (0, 255, 0), 10, 8) # 绘制轮廓
roi = img[y_t:y_t+h_t, x_t:x_t+w_t, :] # 按照轮廓的外接矩形框将感兴趣区域切割出来用于后续的OCR
roi = cv2.resize(roi, dsize=[500, int(500*roi.shape[0]/roi.shape[1])]) # 将图像进行尺度归一化,宽度为500像素,高度按比例跟随变动
# 5. 文字识别及识别结果分析和后处理
ocr_result = ocr.ocr(roi, cls=True)[0] # 调用PaddleOCR库实现对感兴趣区域图片roi中的字符识别
out_name = os.path.splitext(files[i])[0] # 姓名字段,从图片的文件名中直接获取
for j in range(len(ocr_result)):
matching = ocr_result[j][1][0]
if '动态行程卡' in matching: # 电话字段,半隐藏字段,且有后缀文字,需要将后缀文字去除
out_tel = matching[0:11]
elif '更新于' in matching: # 时间字段,包含提示信息(“更新于”)及日期和时间,需要分别提取并组合成 [yyyy-mm-dd hh:mm:ss] 格式
out_date = matching.replace(':',':')
out_date = out_date[4:14] + ' ' + out_date[14:]
elif '到达' in matching: # 行程字段,匹配OCR识别出来的第一条行程信息
out_journey = ''
start = j
for k in range(start, len(ocr_result)): # 将OCR识别出来的第一条行程信息与后续的列表字段进行拼接,获得完整的行程信息
out_journey = out_journey + ocr_result[k][1][0]
out_journey = out_journey.replace(':',':') # 替换行程信息中的全角引号为半角引号,解决识别中出现的错误
if out_journey.find('途经:') != -1: # 查找行程信息中地址信息的起点索引。
startid = out_journey.find('途经:') + 3
elif out_journey.find('途径:') != -1:
startid = out_journey.find('途径:') + 3
elif out_journey.find('途经') != -1:
startid = out_journey.find('途经') + 2
else:
startid = 0
endid = out_journey.find('(注') # 查找行程信息中地址信息的终点索引。
if endid != -1:
out_journey = out_journey[startid:endid]
else:
out_journey = out_journey[startid::]
out_isStar = '是' if '*' in out_journey else '否' # 根据行程信息中是否存在星号进行判断
# roi_sign = roi[150:430,100:400]
out_color = '未识别'
# 将输出处理好的识别结果写入DataFrame列表中
df.loc[i] = np.array([out_name, out_tel, out_date, out_journey, out_isStar, out_color]) # 逐行输出结果至DataFrame
print('已完成:[{}/{}] {}: {}'.format(i,n, out_name,out_journey)) # 输出指定样本符合条件的轮廓数量(一般只应存在一个符合条件的轮廓)
# 6. 将输出处理好的识别结果写入DataFrame列表中
display(df) # display() 只能在Notebook中运行,在pythn中需要使用print()进行替代
df.to_excel(os.path.join(project_path, 'output_all.xlsx')) # 将结果保存到Excel电子表格
print('结果保存至{},完毕。'.format(project_path))
开始打印文本提取结果...
已完成:[0/12] 刘备: 西藏自治区山南市,陕西省西安市,西藏自治区拉萨市,北京市,西藏自治区林芝市
已完成:[1/12] 刘达明: 江西省赣州市
已完成:[2/12] 张良武: 河南省郑州市河南省周口市,河南省驻马店市,湖北省武汉市,湖南省长沙市,广东省深圳市
已完成:[3/12] 拉丰: 天津市,美国
已完成:[4/12] 步惊风: 北京市,四川省成都市*
已完成:[5/12] 秦始皇: 辽宁省阜新市,天津市,吉林省长春市,吉林省四平市,辽宁省锦州市,浙江省杭州市
已完成:[6/12] 红卡弟: 湖北黄网
已完成:[7/12] 肇八七: 云南省昆明市
已完成:[8/12] 苏灿: 江苏省南京市*
已完成:[9/12] 邓阿飞: 江西省南昌市,江西省宜春市,江西省吉安市,江西省赣州市
已完成:[10/12] 郭啸天: 江西省赣州市
已完成:[11/12] 黄卡哥: 日本
| 姓名 | 电话号码 | 更新时间 | 途经 | 是否带星 | 色彩 | |
|---|---|---|---|---|---|---|
| 0 | 刘备 | 138****1537 | 2020.06.19 00:23:30 | 西藏自治区山南市,陕西省西安市,西藏自治区拉萨市,北京市,西藏自治区林芝市 | 否 | 未识别 |
| 0 | 刘备 | 138****1537 | 2020.06.19 00:23:30 | 西藏自治区山南市,陕西省西安市,西藏自治区拉萨市,北京市,西藏自治区林芝市 | 否 | 未识别 |
| 1 | 刘达明 | 181****2855 | 2020.05.12 13:43:04 | 江西省赣州市 | 否 | 未识别 |
| 2 | 张良武 | 188****5333 | 2020.04.16 11:12:26 | 河南省郑州市河南省周口市,河南省驻马店市,湖北省武汉市,湖南省长沙市,广东省深圳市 | 否 | 未识别 |
| 3 | 拉丰 | 188****3980 | 2020.07.02 16:22:15 | 天津市,美国 | 否 | 未识别 |
| 4 | 步惊风 | 186****0023 | 2022.09.03 17:44:39 | 北京市,四川省成都市* | 是 | 未识别 |
| 5 | 秦始皇 | 138****5210 | 2021.09.28 16:24:03 | 辽宁省阜新市,天津市,吉林省长春市,吉林省四平市,辽宁省锦州市,浙江省杭州市 | 否 | 未识别 |
| 6 | 红卡弟 | 188****1880 | 2020.07.02 16:22:15 | 湖北黄网 | 否 | 未识别 |
| 7 | 肇八七 | 186****0023 | 2022.09.03 17:44:39 | 云南省昆明市 | 否 | 未识别 |
| 8 | 苏灿 | 133****9346 | 2022.06.28 11:04:26 | 江苏省南京市* | 是 | 未识别 |
| 9 | 邓阿飞 | 150****7181 | 2020.05.12 11:56:03 | 江西省南昌市,江西省宜春市,江西省吉安市,江西省赣州市 | 否 | 未识别 |
| 10 | 郭啸天 | 180****5615 | 2020.05.12 11:46:57 | 江西省赣州市 | 否 | 未识别 |
| 11 | 黄卡哥 | 188****1880 | 2020.07.02 16:22:15 | 日本 | 否 | 未识别 |
结果保存至D://Workspace//DeepLearning//Websitev2\Data\Projects\Project001TravelCard,完毕。