第09章-第1节 基于深度学习的目标检测 课堂互动 显示答案 | 返回首页
作者:欧新宇(Xinyu OU)
最后更新:2025-01-05
【课堂互动13.2.1】目标检测概述
1.(多选)目标检测通常包含两个子任务,识别图像中存在的物体和给出物体在图像中的位置,以下可用于这两个任务的损失函数正确的包括()和()。
A. SVM 和 Smooth L1 Loss
B. Softmax 和 L2 Loss
C. 二值交叉熵 和 Smooth L1
D. L2 Loss 和 Softmax
2.(多选)以下数据集,哪些是目标检测的经典数据集?
A. Imagenet ILSVRC分类数据集
B. Pascal VOC数据库
C. MNIST手写字体识别
D. MSCOCO
E. DukeMTMC-reID行人数据集
3.(多选)以下任务需要区分实例(Instance)的包括()。
A. 图像分类(Classification)
B. 目标检测(Object Detection)
C. 语义分割(Semantic Segmentation)
D. 实例分割(Instance Segmentation)
4.(多选)对象边界框定位,常见的方法包括()。
A. (中心x, 中心y, 宽度, 高度)
B. (左上角x1, 左上角y1, 右下角x2, 右下角y2)
C. (中心x, 中心y, 半径x, 半径y)
D. (左上角x1, 左上角y1, 宽度, 高度)
E. (中心x, 中心y, 左上角x1, 左上角y1)
5.(多选)下列哪些模型属于目标检测模型?
A. VGG16
B. Faster R-CNN
C. ResNet50
D. YOLO
E. GoogLeNet
6.(多选)下列数据可以用来做目标检测任务的标注信息的是()。
A. 标量数据,例如:0, 1, 2, 3...
B. 序列数据,例如:[23,231,234,334,2]
C. XML文件
D. Json文件
【课堂互动13.2.2】评价指标
1. 交并比IoU是进行边界框回归的一种匹配方法,以下描述正确的包括()。
A. IoU可以考虑1对1,1对多,多对1三种匹配方法
B. IoU用于衡量Ground-truth边界框和预测边界框之间并的区域/重叠的区域的比值
C. IoU为真的前提是Ground-Truth类别和预测的类别是相同
D. 当IoU小于预定义的阈值时,匹配结果为真
2. 精确度(Precision)是目标检测中非常重要的评价指标,它衡量了()。
A. 预测为正的样本数占总样本数的比例
B. 预测中真正为正的样本数占总样本数的比例
C. 预测中真正为正的样本数占预测为正的样本数的比例
D. 预测为正且真正为正的样本数占预测为正的样本数的比例
E. 预测为正且真正为正的样本数占总样本数的比例
3. 召回率(Recall)是目标检测中非常重要的评价指标,它衡量了()。
A. 预测为正的样本数占总样本数的比例
B. 预测为正且真的为正的样本数占总样本数的比率
C. 预测为正的样本占所有正确样本数的比例
D. 预测为正且真的为正的样本数占所有正确样本数的比例
4. 【计算题】米老鼠使用花草数据集训练了一个兰花识别系统,该数据集有37种花,共计2000幅图片,其中兰花有180幅。米老鼠所设计的兰花识别系统,总共识别出300幅兰花图像,其中有90幅为正确识别。试问,针对兰花来说,该系统的F1-Score为多少?
A. 0.3
B. 0.5
C. 0.15
D. 0.375
5.(多选)在使用Pascal VOC数据集进行目标检测任务时,以下分类器设计正确的包括()。
A. 20个二分类SVM分类器
B. 21个二分类SVM分类器
C. 1个20分类的Softmax分类器
D. 1个21分类的Softmax分类器
6. 在下图中,黄色框A为GroundTruth标注区域,蓝色框B为模型预测区域,红色阴影区域C为两者重合部分。下列()正确计算了标注区域和预测区域之间的IOU。
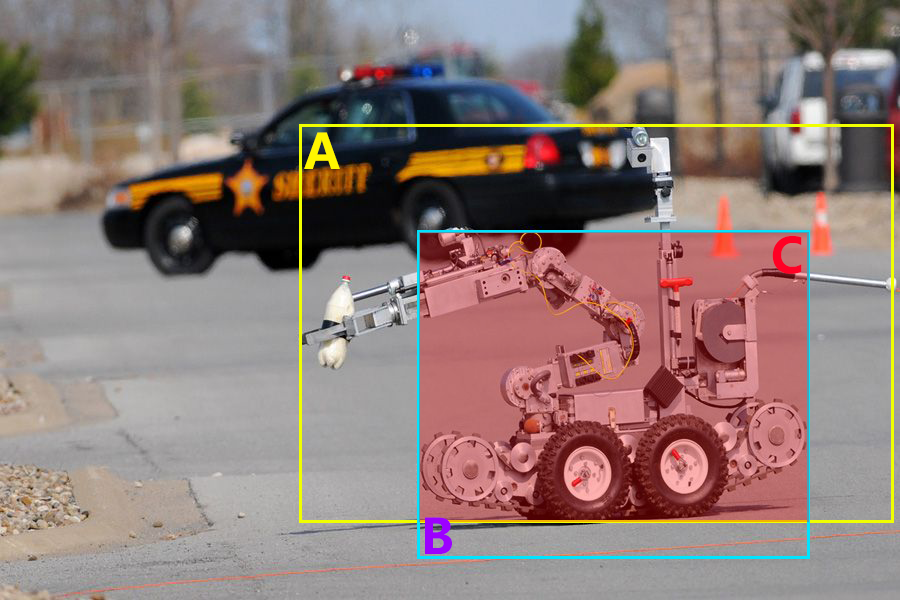
A. (B-C)/B
B. C/(A+B-C)
C. (B-C)/(A-C)
D. C/(A+B+C)
【课堂互动13.2.3】传统目标检测技术
1.(多选)候选区域的生成通常会被作为目标检测的前置工作,通常给定的候选区域数量越多()。
A. 召回率越高
B. 召回率越低
C. 精确度越高
D. 精确度越低
2. 以下技术,哪一组都属于候选区域生成?
A. 滑动窗口、Adaboost、DPM
B. EdgeBox、Bing、HoG
C. Selective Search、EdgeBox、Bing
D. SVM、Selective Search、RPN
3. 以下区域建议算法,速度最快的一个是()。
A. 滑动窗口算法
B. Bing
C. Selective Search
D. EdgeBox
4. 与传统目标检测算法相比,基于深度学习的目标检测模型所提取的特征专用性较强,且不易被迁移。
A. 正确
B. 错误
【课堂互动13.2.4】关键技术简介
1. 设某卷积特征图的尺度为7×7×256,若按照{1:1, 1:2, 2:1}的比例,每种比例4种尺度构建锚点。总共可以生成()个RoIs。
A. 49
B. 12
C. 147
D. 588
E. 150528
2. BoundingBox回归,包含多种回归目标,其中边界框微调(BoundingBox Refinement)是指()。
A. 求目标对象的最终边界框
B. 求目标对象的最终边界框与区域建议之间的变化值
C. 求目标对象的最终边界框与图像基准点(左上角)的变化值
D. 求目标对象的最终边界框与图像基准点(中心)的变化值
3. 在使用区域建议网络(RPN)进行Bounding Box分类时,分类器输出的是()。
A. 二进制交叉熵的损失值
B. Softmax的语义类别
C. 目标的对象性置信度
D. Softmax的类别概率
4. 特征金字塔网络实现了多尺度特征的提取,其中较深的层次语义信息丰富,卷积特征图分辨率(),适合获取较大目标;较浅的层次,卷积特征图感受野(),适合获取较小的目标。
A. 小 小
B. 小 大
C. 大 小
D. 大 大
5. 非极大值抑制在目标检测中非常有用,它可以(),只保留其中一个。
A. 删除多个属于同一类别的不同对象
B. 删除同一个对象,且预测为同一种类别的多个冗余预测
C. 删除同一个对象,但预测为不同种类别的多个预测
D. 随机删除置信度低的多个预测
【课堂互动13.2.5】基于两阶段方法的目标检测技术 @ R-CNN, SPP-Net
1.(多选)R-CNN实现了基于卷积神经网络的目标检测,但它依然存在很多不足,包括()。
A. 卷积网络、分类器、边界框回归都需要单独训练,无法统一回传梯度,即影响速度,又使训练过于复杂
B. 因为每个建议框都需要运行大于2000次前向传输,因此预测速度很慢
C. 容易产生定位误差
D. 特征图上的一个网格只能检测出一个对象
2. 在标准的R-CNN模型中,使用了Selective Search算法实现候选区域的生成,除了该算法,下列哪些算法也可以被用在R-CNN模型中提取候选区域。
A. Bing
B. 滑动窗口
C. EdgeBox
D. 以上都可以
E. 以上都不行
3. 在标准的R-CNN模型中,使用了SVM对最终输出的特征进行分类,从而实现对象类别的识别。下列哪些算法也可以被用在R-CNN模型中实现分类。
A. 随机森林
B. 决策树
C. Softmax
D. 以上都不行
E. 以上都可以
4. SPP-Net使用空间金字塔池化来实现特征层中RoI特征的映射,但是由于后续仍然是全连接层,因此仍然无法实现任意尺度样本的输入。
A. 正确
B. 错误
5.(多选)针对R-CNN模型在预测时的四个主要的问题,SPP-Net主要解决或缓解了哪几个问题?
A. 由于每个区域都需要进行一次CNN前向导致的预测速度慢的问题
B. 所有区域都需要变形为固定的尺寸,导致的失真问题
C. 用于特征提取的ConvNet,用于分类的SVM和用于边界框定位的BBox回归需要单独训练,导致的性能下降和训练复杂性问题
D. 区域建议算法速度较慢的问题
【课堂互动13.2.6】基于两阶段方法的目标检测技术 @ Fast R-CNN
1. 在使用Selective Search等区域建议方法去生成Fast R-CNN所使用的建议区域时,通常会生成大约2000个建议框,建议框的数量由程序确定,无法进行修改。
A. 正确
B. 错误
2.(多选)在Fast R-CNN模型中引入了RoI Pooling,该技术实现了RoI区域的特征可以从卷积特征图上进行提取,而不用每个RoI区域都进行一次CNN前向传输。但这种技术依然存在一些问题,主要包括()。
A. RoI错位误差
B. 无法生成定长的特征,因此要求输入样本必须固定尺度
C. 速度较慢且需要大量的计算资源
D. 无法自动生成区域建议,依赖于附加的区域建议算法
3. Fast R-CNN对R-CNN进行了改进,特别是执行速度方面,但使用的依然是相同的分类器。
A. 正确
B. 错误
4. Fast R-CNN的运行时间主要由()主导。
A. 特征提取
B. 区域建议
C. 区域回归
D. 区域框分类
5. RoI对齐(RoI Align)解决了RoI Pooling因为对齐特征图导致的定位误差问题,它主要是通过()实现RoI区域的特征提取。
A. 自动平移
B. 区域形变
C. 区域回归
D. 双线性插值
6. 在Fast R-CNN中,用于分类的Softmax和用于边界框定位的bbox回归所使用的特征来源于()。
A. 同一个全连接层
B. 不同的全连接层
C. 同一个卷积层
D. 不同的卷积层
【课堂互动13.2.7】基于两阶段方法的目标检测技术 @ Faster R-CNN
1. 下列目标检测算法中,哪些算法在提取卷积特征时,对于每个区域建议框都需要进行一次CNN前向传输。
A. R-CNN
B. SPP-Net
C. Fast R-CNN
D. Faster R-CNN
2.(多选)下列目标检测模型中,哪些模型可以使用非极大抑制来实现冗余预测的移除?
A. R-CNN
B. SPP-Net
C. Fast R-CNN
D. Faster R-CNN
3. Faster R-CNN包含两套分类器和两套区域回归器,其中两套分类器具有相同的功能。
A. 正确
B. 错误
4. 与Fast R-CNN和R-CNN类似,Faster R-CNN虽然使用区域建议网络RPN替代了前置的区域建议算法,但依然需要生成大约2000个左右的RoIs。
A. 正确
B. 错误
5.(多选)在实际应用中,关于RPN网络生成的锚点Anchor,下列描述不正确有()
A. 数量大约等于300个
B. 数量大约等于2000个
C. 其长宽比都包括{1:1, 1:2, 2:1}三种,尺度一般为3-5种
D. 每个卷积特征图上的网格有且仅有一个锚点
【课堂互动13.2.8】基于单阶段方法的目标检测技术 @ YOLOv1v2,SSD,RetinaNet
1.(多选)Focal Loss是一种精心设计的损失函数,它有效地改善了基于单级(One-stage)目标检测系统识别性能较低问题,它主要解决的问题包括()。
A. 缓解正负样本不均匀问题
B. 缓解不同尺寸样本不均匀问题
C. 缓解样本和背景不均匀问题
D. 缓解难易样本不均匀问题
2. YOLOv1是第一个基于卷积神经网络的端到端的目标检测系统,由于它是一种基于回归的算法,因此它可以实现边界框的密集采样,从而实现较高的检测召回率。
A. 正确
B. 错误
3. SSD模型的主要贡献在于()。
A. 提出基于卷积神经网络的区域建议方法,从而实现在卷积特征图上预设不同尺度的区域建议框
B. 提出Focal Loss损失函数解决样本严重不均衡问题
C. 提出基于多个卷积层的多尺度特征提取方法,提高不同尺度目标检测的鲁棒性
D. 提出难样本挖掘算法,实现对难样本识别性能的提高
E. 提出非极大抑制算法,用来解决冗余预测的问题
4. 由于两级结构针对区域进行的了专门的设计,因此两级网络一定比单级网络的检测识别率更高。
A. 正确
B. 错误
5. 在YOLO目标检测算法中,特征图被划分为 W×H 个网格,每个网格设置B个建议区域。因此,YOLO在同一个网格区域内可以实现多个目标的识别。
A. 正确
B. 错误
【课堂互动13.2.9】基于单阶段方法的目标检测技术 @ YOLOv3
1. 自从2018年YOLOv3被提出后,它逐渐成为工业界的宠儿,相比两阶段的目标检测算法,YOLOv3具有()的优点。
A. 受益于单阶段的优势,YOLOv3抛弃了生成建议框的过程,因此大大提高了检测速度
B. 由于每个网格中的建议框都是通过聚类算法从训练集中获得,因此建议框比RPN具有更高的置信度,从而获得比两阶段算法更优的精确度
C. 基于网格的密集采样大大提高了YOLOv3算法的召回率
D. 基于网格的密集采样使YOLOv3在识别小目标和聚集的目标方面更优于两阶段的算法
2. COCO数据集包含80个类别,YOLOv3在该数据集上总共聚类了()个先验锚框。
A. 3
B. 4
C. 9
D. 80
E. 81
3. YOLOv3的特征图的形态为[N, C, H, W], 该模型可以生成()个网格。
A. N
B. N×C
C. N×H
D. H×W
E. C
4. YOLOv3在VOC数据集(20类)上,每个预测框都需要包含()个信息。
A. 20
B. 21
C. 24
D. 25
E. 5
5. 在YOLOv3中,与真实框 IoU<0.5 的先验锚框被称为负例。对于负例样本,不计算Loss。
A. 正确
B. 错误
【课堂互动13.2.10】基于单阶段方法的目标检测技术 @ PP-YOLO
1. Image Mixup是一种常见的图像增强算法,该算法将任意两张图片进行组合,其实现方法为()。
A. 将两幅图像进行水平并排拼合
B. 将两幅图像进行垂直并排拼合
C. 将两幅图像按照一定的透明度进行融合
D. 将两幅图像的目标对象拼合到其中一副图像的背景中
E. 随机使用上述四种方法中的一种进行变换
2.(多选)Label Smooth通过()实现将硬标签向软标签进行变换,从而缓解过拟合问题。
A. 对One-Hot目标的正例的1减去一个小量
B. 对One-Hot目标的正例的1增加一个小量
C. 对One-Hot目标的负例的0减去一个小量
D. 对One-Hot目标的负例的0增加一个小量
3. 使用ResNet50D对ResNet50进行改进的主要原因是()。
A. 使用stride=2的1×1卷积进行特征提取时,会有一定的信息丢失
B. 使用stride=2的3×3卷积进行特征提取时,会有一定的信息丢失
C. 使用stride=2的2×2 AvgPool时,会有一定的信息丢失
D. 使用连续卷积时,会有一定的信息丢失
4.(多选)下列对于可变性卷积描述正确的包括()。
A. 可变性卷积只能用在一个层的卷积核上,不能同时应用于多个层
B. 在训练过程中,不仅需要学习卷积核的值,还需要学习卷积核的形状
C. 在进行卷积核形状学习时,只能学到旋转、平移等刚性形态变换
D. 可变性卷积进行变形学习时,通过逐像素的位移实现整体形态的变换
5. 随即丢弃是一类常见的降低过拟合、提高网络泛化能力方法。下列随机丢弃方法中,在目标检测中性能最好的一种是()。
A. Dropout
B. Droppoint
C. Dropblock
D. Dropconnect
6. 下列算法中,用于解决非极大值在单个网格中无法实现多个不同目标检测的问题的是()。
A. Matrix NMS
B. Grid Sensitive
C. IoU Loss
D. SPP
E. SSLD
【课堂互动13.2.11】基于Anchor-Free的目标检测技术 @ CornerNet
1.(多选)常见的Anchor-Free目标检测算放包括()。
A. 基于关键点的目标检测算法
B. 基于中心点的目标检测算法
C. 基于轮廓的目标检测算法
D. 基于颜色的目标检测算法
E. 基于连通图的目标检测算法
2.(多选)以下描述,哪些属于Anchor-Based目标检测方法的缺点。
A. 为保证召回率,需要较多的锚框,但过多的锚框会导致正负样本严重不均衡
B. 预定义的锚框尺寸有利于提高检测器的泛化能力
C. 基于轮廓的目标检测算法
D. 与Anchor相关的超参数调节困难,过于依赖于经验
E. 海量的锚框会占用较多的计算资源,影响系统效率
3. 在CornerNet中,模型使用一对角点来确定目标的位置,下面正确的一对角点为()。
A. 左上角和右上角
B. 左上角和右下角
C. 左下角和右上角
D. 左下角和右下角
4. 在Corner Pooling算法中,实际上是按照一定的方法执行()。
A. Mean-pooling
B. Global average pooling
C. Max-pooling
D. Stochastic-pooling
5.(多选)在CornerNet的Embeddings模块中,下列描述正确的是()。
A. 同一目标的一对角点距离较大
B. 同一目标的一对角点相似度较高
C. 不同目标的一对角点距离较大
D. 不同目标的一对角点相似度较高
6. 降低惩罚是CornerNet中Heatmaps寻找角点的核心功能之一,其实现方法为()。
A. 正样本的监督信息从角度的一个像素变为一个和目标GT等比例缩小的边界框
B. 正样本的监督信息从角落的一个像素变为一个圆形的高斯区域
C. 正样本的监督信息范围根据预测框的尺度,按照一定的阈值进行缩放
D. 将预测框给出的分类概率乘以预测框于目标GT框的IoU,从而降低预测框概率对总损失的影响
【课堂互动13.2.12】基于Anchor-Free的目标检测技术 @ FCOS,CenterNet,TTFNet
1. FCOS是一种基于()的目标检测算法,它实现了无锚点、无建议框的解决方案。
A. 多层感知机
B. 全Pooling网络结构
C. 全卷积网络结构
D. 图模型结构
2. 在FCOS中提出的中心度(Centerness),主要用来()
A. 通过降低IoU较低的BBox的置信度,来实现RoIs质量的提高
B. 通过提高IoU较高的BBox的置信度来实现RoIs质量的提高
C. 通过提高RoIs的置信度来提高检测的精度
D. 通过提高RoIs的置信度来提高检测的速度
3. CenterNet使用GroundTruth BBox的边界框来确定中心点,为了提高正样本的比例,使用()来扩展中心点。
A. 椭圆高斯分布
B. 椭圆贝努利分布
C. 圆形高斯分布
D. 圆形贝努利分布
E. 离散泊松分布
4.(多选)在TTFNet中下列哪些策略可以在保持性能的基础上提高模型的收敛速度?
A. 通过降低NMS阈值来减少样本的采样数量
B. 通过提高学习率来,减少训练轮次
C. 通过椭圆高斯提高监督信息的质量
D. 通过减少数据预处理来简化训练流程从而提高训练速度
E 使用中心度来惩罚质量较低的RoIs
5. 在TTFNet中,使用GIoU Loss来进行边界框回归,并在Loss中增加了权重项,其主要目的是()。
A. 平衡不同尺度样本产生的Loss
B. 平衡不同形状样本产生的Loss
C. 平衡正负样本产出的Loss
D. 平衡不同色彩空间样本的Loss