【竞赛01】垃圾分类(Garbage Classification) Baseline | 返回首页
作者:欧新宇(Xinyu OU)
当前版本:Release v1.1
开发平台:Paddle 2.3.2
运行环境:Intel Core i7-7700K CPU 4.2GHz, nVidia GeForce GTX 1080 Ti
本教案所涉及的数据集仅用于教学和交流使用,请勿用作商用。
最后更新:2025年1月30日
所有作业均在AIStudio上进行提交,提交时包含源代码和运行结果
一、任务描述
近年来,随着人工智能的发展,其在语音识别、自然语言处理、图像与视频分析等诸多领域取得了巨大成功。随着政府对环境保护的呼吁,垃圾分类成为一个亟待解决的问题,本次竞赛将聚焦在垃圾图片的分类,利用人工智能技术,对居民生活垃圾图片进行检测,找出图片中有哪些类别的垃圾。 要求参赛者基于Paddle,给出一个算法或模型,对于给定的图片,检测出图片中的垃圾类别。给定图片数据,选手据此训练模型,为每张测试数据预测出最正确的类别。
二、数据说明
本竞赛所用训练和测试图片均来自生活场景。总共四十个类别,类别和标签对应关系在训练集中的dict文件里。图片中垃圾的类别,格式是“一级类别/二级类别”,二级类别是具体的垃圾物体类别,也就是训练数据中标注的类别,比如一次性快餐盒、果皮果肉、旧衣服等。一级类别有四种类别:可回收物、厨余垃圾、有害垃圾和其他垃圾。
数据文件包括训练集(有标注)和测试集(无标注),训练集的所有图片分别保存在train文件夹下面的0-39个文件夹中,文件名即类别标签,测试集共有400张待分类的垃圾图片在test文件夹下。

三、分数评定
- 所有奖励分数均叠加到期末总成绩中
- 第一名奖励10分,第二名奖励8分,第三名奖励7分
- 排名4~10名,奖励6分;排名11~20名,奖励5分
- 所有参与竞赛者,奖励2分,与排名奖励不冲突
- 分数评定高于Baseline的参与者,奖励3分,与排名奖励不冲突
四、提交答案
- 所有内容均在AIStudio上进行提交,提交时包含源代码和运行结果
- 数据集下载地址:https://aistudio.baidu.com/aistudio/datasetdetail/71361
- 提交完整程序代码,包括运行过程(非必须)
- 提交结果文件。结果文件为
.txt文件格式,命名为 results.txt,文件内的字段需要按照指定格式写入。- 每个类别的行数和测试集原始数据行数应一一对应,不可乱序。
- 输出结果应检查是否为400行数据,否则成绩无效。
- 输出结果的每一行都包含一个文件名、空格和一个预测结果(数字)
样例如下:
test1.jpg 1
test2.jpg 2
test3.jpg 3
test4.jpg 4
test5.jpg 5
···
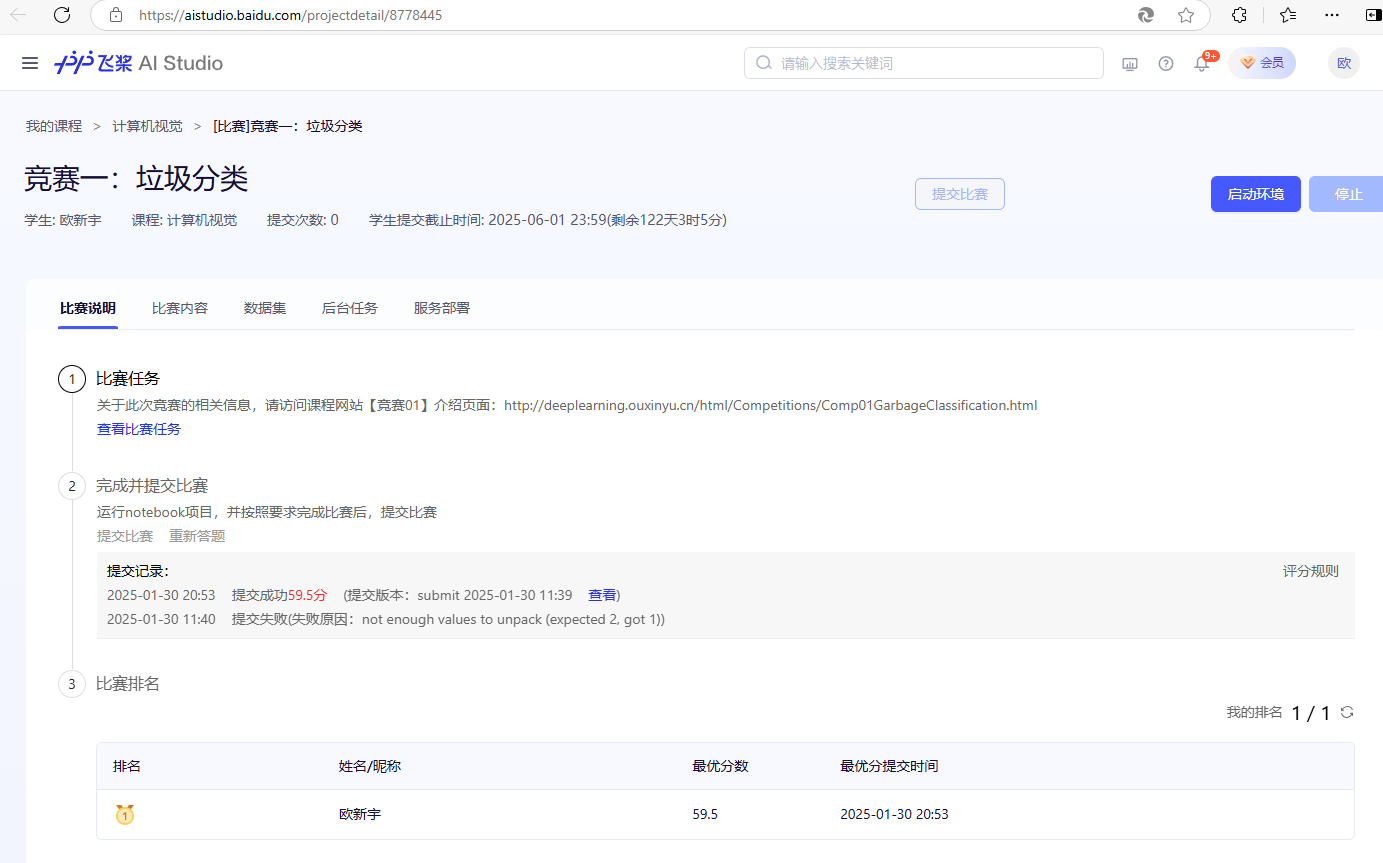
五、结果展示
六、输出预测结果示例代码
若已完成模型训练,并获得了部署模型,那么可以使用以下示例代码进行批量预测,并输出预测结果。假设部署模型、测试数据和预测结果保存路径分别为deployment_final_models、dataset_test_path和prediction_results。
# 导入依赖库
import numpy as np
import os
import cv2
import paddle
import paddle.nn.functional as F
import paddle.vision.transforms as T
exclusion = ['.DS_Store', '.ipynb_checkpoints'] # 被排除的文件夹
# 1. 定义模型、数据集和预测结果保存路径
deployment_final_models = 'D:\\Workspace\\ExpDeployments\\Comp01GarbageClassification\\final_models\\Garbage_resnet50_final'
dataset_test_path = 'D:\\WorkSpace\\ExpDatasets\\Garbage\\test'
prediction_results = 'D:\\Workspace\\ExpDeployments\\Comp01GarbageClassification\\Garbage_resnet50_prediction.txt'
# 2. 定义预测函数
def predict(model, image):
transform = T.Compose([
T.Resize([227, 227]),
T.ToTensor(),
T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
image = transform(image)
image = paddle.unsqueeze(image, axis=0)
logits = model(image)
pred = F.softmax(logits)
pred_id = np.argmax(pred)
return pred_id
#3. 载入使用部署模型进行预测
model = paddle.jit.load(deployment_final_models)
testImg_list = os.listdir(dataset_test_path)
with open(prediction_results, 'a', encoding="utf-8") as f_pred:
for testImg in testImg_list:
if testImg not in exclusion:
img_path = os.path.join(dataset_test_path, testImg)
image = cv2.imread(img_path, 1)
pred_id = predict(model, image)
f_pred.write('{}\t{}\n'.format(testImg, pred_id))
# 4. 输出预测结果
print('共输出预测样本 {} 个,输出路径为:{}。'.format(len(testImg_list), prediction_results))
共输出预测样本 400 个,输出路径为:D:\Workspace\ExpDeployments\Comp01GarbageClassification\Garbage_resnet50_prediction.txt。