【项目023】深度学习训练过程的可视化
作者:欧新宇(Xinyu OU)
当前版本:Release v2.0
开发平台:Paddle 2.5.2
运行环境:Intel Core i7-7700K CPU 4.2GHz, nVidia GeForce GTX 1080 Ti
本教案所涉及的数据集仅用于教学和交流使用,请勿用作商用。
最后更新:2024-06-04
深度学习的训练过程一直被认为是黑盒的,这主要是因为我们并不知道最终的结果究竟是因何而来,我们所看到的仅仅是一些浮点数的组合(张量)。然而,可视化技术为我们打开了一扇窗,让我们对深度学习有了一些可解释依据。常见的可视化技术主要包括三类:
- 卷积层权重可视化 通常,卷积核都是使用某种随机算法实现初始化,经过良好训练之后,这些卷积核的权值通常表现为美观、光滑的滤波器;反之,如果出现噪声图样,则可能意味着网络的训练并没有收敛,或者由于正则化强度过小导致网络出现过拟合。在低层次的卷积层中,一部分卷积核负责提取高频灰度特征,主要呈现出边缘、气泡等结构性特征,而另一部分卷积核则负责提取低频颜色特征;在高层次的卷积层中,卷积核会倾向于呈现更完整、更全面的轮廓特征、全局特征。因此,通过卷积层权值的可视化操作,可以初步判断深度学习模型的优劣。
- 特征图可视化 与卷积层的权重类似,在特征图可视化中,高层响应的特征图关注图像中不同细节,例如背景或主体的纹理或轮廓,可以从中选择图片的风格特征;而底层特征图变得局部且稀疏,可以用于剔除不相关内容并提取目标重要的特征。利用特征图,可以实现显著性区域的识别和利用。
- 训练结果可视化 训练过程的可视化主要是实时地关注训练时训练集和验证集的精度、损失值等评价指标,便于实现超参数的选择和执行早期停止策略。
本教案的V1版本主要关注训练结果的可视化,关于卷积层权重可视化和特征图可视化将在后续的V2版本中呈现。
常见的训练过程可视化主要有两种方式,第一,是利用现有的可视化工具实现,例如百度Paddle的VisualDL,谷歌的Tensorflow;第二,是自定义可视化函数,并使用python代码记录训练过程中输出的迭代次数、精度和损失值,并使用matplotlib库进行输出。此外,我们在自定义可视化函数的时候,由于训练过程一般是按照批次batches进行的,而验证过程是按照周期epoches进行,因此可视化过程也可以考虑将训练和验证分开可视化,前者的横坐标为周期epoches,后者的坐标为迭代次数iters;或者将训练和验证的结果合并可视化,此时的横坐标统一为迭代次数iters,但验证的数据显示仍然是以周期为单位而不是每次迭代都进行一次计算。
【目录结构】
- 本项目目录结构说明(可根据实际情况进行修改)
- 根目录:D:\Workspace\DeepLearning\WebsiteV2
- 项目资源目录:D:\Workspace\DeepLearning\WebsiteV2\Data\Projects\Project023Visualization
- 图片输出目录:D:\Workspace\DeepLearning\WebsiteV2\Images\Projects\Project023Visualization
1. 自定义可视化函数(训练过程和验证过程分开可视化)
1.1 定义可视化函数
import os
import codecs
import json
import paddle
import matplotlib.pyplot as plt # 载入python的第三方图像处理库
# 绘制训练batch精度和平均loss
def draw_process(title, loss_label, accuracy_label, iters, losses, accuracies, figure_path=None, figurename=None, isShow=False):
# 1.第一组坐标轴 Loss
_, ax1 = plt.subplots() # plt.subplots(figsize=(14,6))
ax1.plot(iters, losses, color='red', label=loss_label)
ax1.set_xlabel('Iters', fontsize=20)
ax1.set_ylabel(loss_label, fontsize=20)
max_loss = max(losses)
ax1.set_ylim(0, max_loss*1.2)
# 2.第二组坐标轴 accuracy
ax2 = ax1.twinx()
ax2.plot(iters, accuracies, color='blue', label=accuracy_label)
ax2.set_ylabel(accuracy_label, fontsize=20)
max_acc = max(accuracies)
ax2.set_ylim(0, max_acc*1.2)
# 3.配置图例
plt.title(title, fontsize=24)
handles1, labels1 = ax1.get_legend_handles_labels()
handles2, labels2 = ax2.get_legend_handles_labels()
plt.legend(handles1+handles2, labels1+labels2, loc='best')
plt.grid()
# 4.将绘图结果保存到 final_figures 目录
plt.savefig(os.path.join(figure_path, figurename + '.png'))
# 5.显示绘图结果
if isShow is True:
plt.show()
1.2 测试可视化函数
本例直接读取目标文件夹中已保存的训练日志文件 train.json,并调用可视化函数draw_process()进行绘制。
### 测试可视化函数 ###################################################
if __name__ == '__main__':
root_path = 'D://Workspace//DeepLearning//Websitev2'
projcet_path = os.path.join(root_path, 'Images', 'Projects', 'Project023Visualization')
try:
train_log = json.loads(open(os.path.join(projcet_path, 'train.json'), 'r', encoding='utf-8').read())
draw_process('Training', 'loss', 'accuracy', train_log['iters'], train_log['losses'], train_log['accs_top1'], figure_path=projcet_path, figurename='train', isShow=True)
except:
print('数据不存在,无法进行绘制')
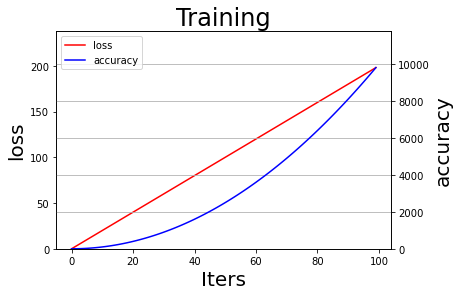
1.3 生成并保存日志数据
在本例中,我们将生成训练日志和验证日志中的测试数据来演示如何保存并读取数据,在实际使用中,日志数据是在 训练过程 中实时生成的。
if __name__ == '__main__':
root_path = 'D://Workspace//DeepLearning//Websitev2'
projcet_path = os.path.join(root_path, 'Images', 'Projects', 'Project023Visualization')
# 1. 初始化用于绘图的日志数据 train_log|val_log: 初始化状态为字典格式,数据字段为列表格式
train_log = val_log = {
'iters': [],
'losses': [],
'accs_top1': [],
'accs_top5': []
}
# 2. 保存日志数据: 在训练过程中,实时更新日志文件
for iters in range(100):
val_log['iters'].append(iters)
val_log['losses'].append(iters*iters)
val_log['accs_top1'].append(iters**0.5)
val_log['accs_top5'].append(3*iters)
# 3. 将日志字典保存为json格式,绘图数据可以在训练结束后自动显示,也可以在训练中手动执行以显示结果
if not os.path.exists(projcet_path):
os.makedirs(projcet_path)
with codecs.open(os.path.join(projcet_path, 'val.json'), 'w', encoding='utf-8') as f_val:
json.dump(val_log, f_val, ensure_ascii=False, indent=4, separators=(',', ':')) # 格式化字典格式的参数列表
# 4. 输出可视化绘图
draw_process('Validation', 'loss', 'accuracy', val_log['iters'], val_log['losses'], val_log['accs_top1'], figure_path=projcet_path, figurename='val', isShow=True)
2. 自定义可视化函数(训练过程和验证过程合并显示可视化)
2.1 定义可视化函数
def draw_process_ch6(visualization_log, show_top5=False, figure_path=None, figurename='visualization_log', isShow=True):
"""绘制训练过程中的训练误差、训练精度、验证误差和验证精度四个重要输出"""
train_losses = visualization_log['train_losses'] # 训练集的损失值
train_accs_top1 = visualization_log['train_accs_top1'] # 训练集的top1精确度
train_accs_top5 = visualization_log['train_accs_top5'] # 训练集的top5精确度
val_losses = visualization_log['val_losses'] # 验证集的损失值
val_accs_top1 = visualization_log['val_accs_top1'] # 验证集的精确度
val_accs_top5 = visualization_log['val_accs_top5'] # 验证集的精确度
epoch_iters = visualization_log['epoch_iters'] # 周期epoch迭代次数
batch_iters = visualization_log['batch_iters'] # 批次batch迭代次数
# 第一组坐标轴 Loss
_, ax1 = plt.subplots()
ax1.plot(batch_iters, train_losses, color='orange', linestyle='--', label='train_loss')
ax1.plot(epoch_iters, val_losses, color='cyan', linestyle='--', label='val_loss')
ax1.set_xlabel('Iters', fontsize=16)
ax1.set_ylabel('Loss', fontsize=16)
max_loss = max(max(train_losses), max(val_losses))
ax1.set_ylim(0, max_loss*1.2)
# 第二组坐标轴 accuracy
ax2 = ax1.twinx()
ax2.plot(batch_iters, train_accs_top1, 'o-', color='red', markersize=3, label='train_accuracy(top1)')
ax2.plot(epoch_iters, val_accs_top1, 'o-', color='blue', markersize=3, label='val_accuracy(top1)')
if show_top5==True:
ax2.plot(batch_iters, train_accs_top5, 'o-', color='magenta', markersize=3, label='train_accuracy(top5)')
ax2.plot(epoch_iters, val_accs_top5, 'o-', color='pink', markersize=3, label='val_accuracy(top5)')
ax2.set_ylabel('Accuracy', fontsize=16)
max_accs = max(max(train_accs_top1), max(train_accs_top5), max(val_accs_top1), max(val_accs_top5))
ax2.set_ylim(0, max_accs*1.2)
# 3.配置图例
plt.title('Training and Validation Results', fontsize=18)
handles1, labels1 = ax1.get_legend_handles_labels() # 图例1
handles2, labels2 = ax2.get_legend_handles_labels() # 图例2
plt.legend(handles1+handles2, labels1+labels2, loc='best')
plt.grid()
# 4.将绘图结果保存到 final_figures 目录
plt.savefig(os.path.join(figure_path, figurename + '.png'))
# 5.显示绘图结果
if isShow is True:
plt.show()
2.2 测试可视化函数
本例直接读取目标文件夹中已保存的训练日志文件 visualization_log.json,并调用可视化函数draw_process_ch6()进行绘制。
### 测试可视化函数 ###################################################
import os
import json
import matplotlib.pyplot as plt # 载入python的第三方图像处理库
import paddle # 载入PaddlePaddle基本库
if __name__ == '__main__':
root_path = 'D://Workspace//DeepLearning//Websitev2'
final_figures_path = os.path.join(root_path, 'Images', 'Projects', 'Project023Visualization')
try:
log_file = json.loads(open(os.path.join(final_figures_path, 'visualization_log.json'), 'r', encoding='utf-8').read())
draw_process_ch6(log_file, figure_path=final_figures_path, show_top5=True)
except:
print('数据不存在,无法进行绘制')
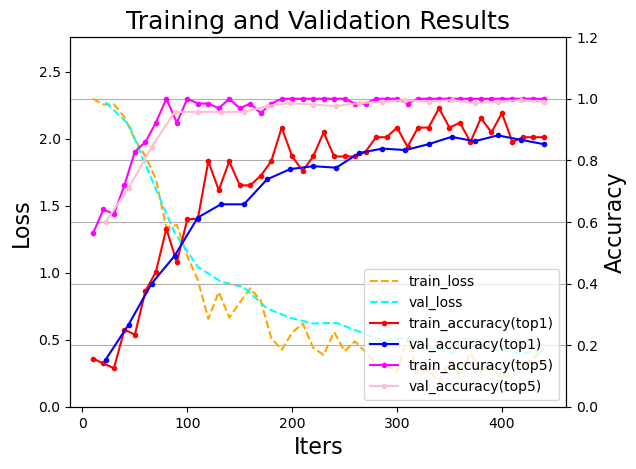
3. 生成并保存日志数据
在本例中,我们将生成visualizaiton_log字典中测试数据来演示如何保存并读取数据,在实际使用中,日志数据是在 训练过程 中实时生成的。
if __name__ == '__main__':
root_path = 'D://Workspace//DeepLearning//Websitev2'
projcet_path = os.path.join(root_path, 'Images', 'Projects', 'Project023Visualization')
# 1. 初始化用于绘图的日志数据visualization_log: 初始化状态为字典格式,数据字段为列表格式
visualization_log = { # 初始化状态字典
'train_losses': [], # 训练损失值
'train_accs_top1': [], # 训练top1精度
'train_accs_top5': [], # 训练top5精度
'val_losses': [], # 验证损失值
'val_accs_top1': [], # 验证top1精度
'val_accs_top5': [], # 验证top5精度
'batch_iters': [], # 批次batch迭代次数
'epoch_iters': [], # 周期epoch迭代次数
}
# 2. 保存日志数据: 在训练过程中,实时更新日志文件(根据实际情况设置,此处为测试数据)
for num_batch in range(100):
visualization_log['train_losses'].append(float(num_batch*num_batch)) # 训练损失avg_loss
visualization_log['batch_iters'].append(num_batch) # 批次batch迭代次数
visualization_log['train_accs_top1'].append(float(num_batch*0.6)) # 训练top1精度acc_top1
visualization_log['train_accs_top5'].append(float(num_batch*0.7)) # 训练top5精度acc_top5
visualization_log['epoch_iters'].append(num_batch) # 周期epoch迭代次数
visualization_log['val_losses'].append(float(num_batch*num_batch*0.9)) # 验证损失val_loss
visualization_log['val_accs_top1'].append(float(num_batch*0.45)) # 验证top1精度val_acc_top1
visualization_log['val_accs_top5'].append(float(num_batch*0.55)) # 验证top5精度val_acc_top5
# 3. 将日志字典保存为json格式,绘图数据可以在训练结束后自动显示,也可以在训练中手动执行以显示结果
if not os.path.exists(final_figures_path): # 判断是否存在文件夹,不存在则创建
os.makedirs(final_figures_path)
with codecs.open(os.path.join(final_figures_path, 'visualization_log_test.json'), 'w', encoding='utf-8') as f_log:
json.dump(visualization_log, f_log, ensure_ascii=False, indent=4, separators=(',', ':')) # 格式化字典格式的参数列表
# 4. 输出可视化绘图
draw_process_ch6(visualization_log, figure_path=final_figures_path, show_top5=True, isShow=True)
